
Supporting Academic Research : new study identifies opportunities for research offices and libraries to strengthen support for researcher. Jerusalén: Ex-Libris, 2019
Texto completo
Una encuesta de 300 investigadores de los Estados Unidos, el Reino Unido y Australia indicó un acuerdo universal de que las bibliotecas deberían apoyar el proceso de investigación académica.
Los datos de un estudio encargado por Ex Libris parecen indicar una especie de desconexión entre las expectativas de los investigadores de la biblioteca y lo que sucede en la práctica.
Este documento incluye los resultados de una encuesta de 300 investigadores y entrevistas con miembros de alto rango de oficinas de investigación en los Estados Unidos, el Reino Unido y Australia.
El documento examina las prioridades clave de investigación, que incluyen:
- La satisfacción de los investigadores con el apoyo recibido por la oficina de investigación y la biblioteca.
- Qué actividades realizan los investigadores por si mismos en lugar de obtener ayuda de otros
- Experiencia en la búsqueda y solicitud de subvenciones.
- Medición del impacto de la investigación
- Exhibir y mantener los perfiles de los investigadores.
Expectativas: las bibliotecas deberían estar haciendo algo (¿pero qué?)
Se preguntó a los investigadores «¿Cuál de las siguientes opciones espera que haga la biblioteca para apoyar su tarea como investigador?» Aquí está el desglose general de las respuestas:
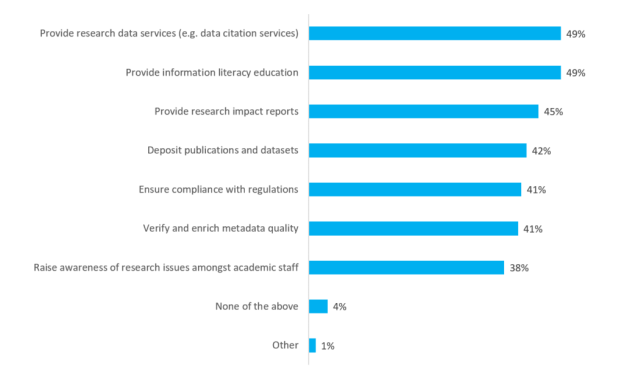
Todo ello sugiere que, a pesar de la falta de claridad sobre lo que las bibliotecas podrían estar haciendo para apoyar los procesos de investigación, todos los investigadores piensan que deberían estar haciendo algo más.
En la práctica, a pesar de las expectativas declaradas por los investigadores, las bibliotecas juegan muy limitado en el proceso de investigación académica. El estudio Ex Libris también encuestó a los investigadores sobre qué partes del proceso de investigación gestionan ellos mismos de forma independiente y cuáles no, y a quién recurren para obtener ayuda. En ningún caso más del 12% de los encuestados mencionó a la biblioteca como su fuente de apoyo o asistencia.
Los resultados respecto a las tareas en que los investigadores recurren al personal de la biblioteca son:
- Gestión de cargos por procesamiento de artículos (APC): 12%
- Depósito en un repositorio institucional – 12%
- Garantizar el cumplimiento de las políticas de acceso abierto: 10%
- Encontrar revistas relevantes para publicación – 9%
- Monitorear el impacto de su investigación – 8%
- Preparación de planes de gestión de datos: 8%
- Enviar su investigación para su publicación: 6%
- Encontrar oportunidades de financiación relevantes: 5%
- Solicitud de subvenciones de financiación – 4%
Aproximadamente la mitad de los investigadores encuestados dijeron que lo hacían ellos mismos, en lugar de contar con el apoyo de otros. Sin embargo, incluso entre aquellos que obtienen ayuda de sus instituciones, la mayoría recurre a la oficina de investigación o a asistentes de investigación.
Claramente, aunque todavía están involucradas solo en una minoría de estos casos, el soporte de la biblioteca está más enfocado en la gestión de tareas de publicación de investigación, como la gestión de los cargos de procesamiento de artículos (APCs), la búsqueda de revistas relevantes para publicación, depósitos en repositorios institucionales y garantizar el cumplimiento de políticas de acceso abierto.
Esto está en línea con el tipo de actividades que los investigadores esperan de sus bibliotecas institucionales, como se señaló anteriormente. Sin embargo, incluso un número mayor de investigadores dijeron que esperaban que la biblioteca proporcionara servicios de datos de investigación y educación en alfabetización informacional.
La brecha entre lo que a los investigadores les gustaría que hicieran sus bibliotecas y el apoyo que reciben en la práctica no es un abismo insalvable. Más bien, es una gran gran oportunidad en la que las bibliotecas están en una posición única para poder aprovecharla. Las bibliotecas pueden desempeñar un papel más destacado en el ciclo de vida de la investigación al ofrecer más servicios y un mayor apoyo para las actividades relacionadas con la publicación, esencialmente basándose en lo que ya están haciendo, además de expandir sus servicios para incluir el apoyo al proceso de investigación en sí.







