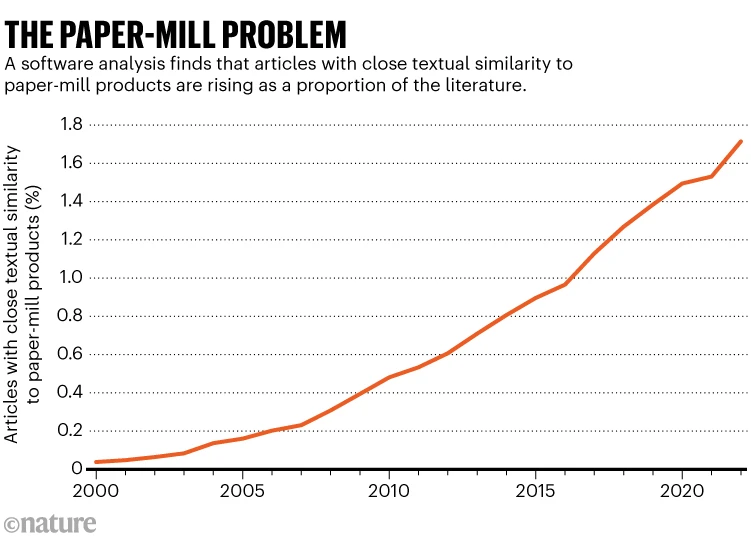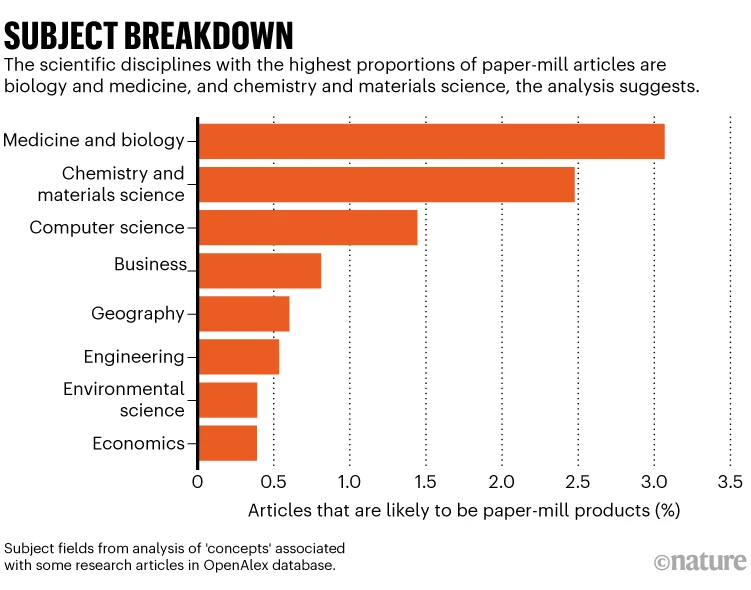
Harvey, Laura y Adam Hyde. “Guest Post — Trust & Community Are the Moat, Infrastructure Is Your Leverage: Dispatches from PurePub.AI”. The Scholarly Kitchen, 9 de junio de 2026
Se recogen las principales conclusiones surgidas del encuentro PurePub.AI, un evento que reunió a 47 expertos en 15 sesiones dedicadas a explorar el impacto de la inteligencia artificial en la publicación académica. La elevada participación —más de 800 asistentes en directo y centenares de intervenciones en los debates— demuestra que la IA ha dejado de ser una cuestión futurista para convertirse en una preocupación estratégica inmediata para editoriales, sociedades científicas y proveedores de servicios. Las discusiones revelaron que los grandes temas que dominan actualmente el sector son la transformación de los flujos de trabajo, la evolución de los modelos de negocio, el papel creciente de las máquinas como consumidoras de contenidos y la necesidad de replantear los procesos editoriales tradicionales.
Uno de los mensajes centrales del encuentro es que la transición hacia la llamada “IA agéntica” ya está en marcha. En una primera fase, las organizaciones utilizan la IA para realizar más rápidamente tareas que ya existían, como la búsqueda de revisores, la detección de fraude científico, la realización de controles técnicos o el enriquecimiento de metadatos. Sin embargo, la evolución apunta hacia una segunda etapa en la que la IA no solo automatiza procesos, sino que mejora significativamente los servicios ofrecidos a investigadores, autores y lectores. Ejemplos de ello son los asistentes inteligentes para la consulta de contenidos científicos, las herramientas de revisión automatizada o los sistemas capaces de generar nuevos servicios de apoyo a la investigación. Aun así, la mayoría de las organizaciones siguen en una fase experimental y todavía no han alcanzado un despliegue generalizado de estas tecnologías.
La revisión por pares constituye uno de los ámbitos donde los cambios resultan más visibles. Los participantes señalaron que los modelos de IA más avanzados ya son capaces de realizar numerosas tareas asociadas al proceso de evaluación científica. La cuestión ya no es si la IA puede participar en la revisión, sino qué aspectos deberían seguir dependiendo del juicio humano. Mientras los sistemas automáticos destacan en tareas de verificación técnica, análisis estadístico, detección de inconsistencias o comprobación de la transparencia metodológica, los revisores humanos continúan siendo esenciales para valorar la originalidad, la relevancia científica, la pertinencia de las preguntas de investigación o la importancia potencial de los resultados. El futuro parece orientarse hacia una colaboración complementaria entre humanos y máquinas más que hacia una sustitución completa de los expertos.
Precisamente esta complementariedad lleva a una reflexión más amplia sobre el valor diferencial que los seres humanos aportan en un entorno cada vez más automatizado. Según los autores, atributos como el criterio, el gusto, la responsabilidad, la capacidad de generar confianza y el mantenimiento de relaciones dentro de las comunidades científicas se perfilan como espacios donde la intervención humana seguirá siendo indispensable. No obstante, también aparecen interrogantes sobre cómo afectará esta transformación a los perfiles profesionales existentes. Muchos participantes expresaron preocupación por la posibilidad de que ciertos trabajadores terminen desempeñando funciones limitadas a supervisar sistemas automáticos, una tarea poco estimulante si no se redefine adecuadamente el papel humano dentro de los nuevos ecosistemas editoriales.
Otro fenómeno destacado es el auge del denominado vibe coding, una metodología que permite a profesionales sin formación avanzada en programación crear prototipos funcionales mediante herramientas de IA. Durante el evento se presentaron trece proyectos desarrollados mediante este enfoque, que abarcan desde gestores de noticias hasta plataformas de transferencia de manuscritos o sistemas de revisión de textos alternativos para imágenes. La importancia de esta tendencia radica en que democratiza la innovación tecnológica, permitiendo que expertos en edición, marketing, operaciones o gestión editorial puedan diseñar soluciones adaptadas a sus necesidades sin depender completamente de equipos técnicos especializados.
Sin embargo, la conclusión más relevante del artículo gira en torno a la idea expresada en su título: la confianza y la comunidad constituyen la auténtica “muralla defensiva” de los editores científicos, mientras que la infraestructura representa su principal fuente de ventaja competitiva. En un contexto en el que la generación de contenidos se vuelve cada vez más barata y abundante gracias a la IA, la capacidad de filtrar, validar y contextualizar la información adquiere un valor extraordinario. Los autores sostienen que las marcas editoriales consolidadas y las comunidades científicas que las respaldan poseen un activo difícilmente replicable por las plataformas tecnológicas: la confianza acumulada durante décadas. Esta visión coincide con otros análisis recientes que consideran que el verdadero valor de las sociedades científicas y los editores no reside únicamente en los contenidos, sino en las relaciones, la reputación y la capacidad de proporcionar señales fiables en un entorno saturado de información.
La infraestructura tecnológica emerge como el segundo gran factor estratégico. Diversos expertos insistieron en que el éxito de la IA depende mucho menos de los modelos lingüísticos que de la capacidad para integrarlos con sistemas, datos y flujos de trabajo existentes. Según una de las citas más repetidas del encuentro, un agente de IA es apenas un 5 % modelo y un 95 % ingeniería de procesos. Esto significa que disponer de datos estructurados, sistemas interoperables y arquitecturas capaces de conectar múltiples fuentes de información será mucho más importante que simplemente adoptar la última tecnología disponible. La verdadera ventaja competitiva se construirá alrededor de la calidad de los datos y de la capacidad organizativa para utilizarlos eficazmente.
Para terminar, los autores plantean una visión de la publicación científica en 2030. Prevén que los agentes inteligentes estarán completamente integrados en los flujos editoriales, que las personas concentrarán su trabajo en tareas relacionadas con la responsabilidad, el juicio crítico y la construcción de comunidades, y que las organizaciones más exitosas serán aquellas que hayan invertido con suficiente anticipación en infraestructuras robustas y flexibles. En este escenario, la inteligencia artificial no sustituirá el valor humano, sino que aumentará la importancia de aquello que las máquinas todavía no pueden ofrecer: confianza, criterio y pertenencia a una comunidad científica reconocida.