El investigador Tushar Sen denunció un presunto intento de soborno tras recibir correos de un supuesto revisor que le ofrecía aceptar su artículo a cambio de un pago. Wiley abrió una investigación y confirmó que la dirección de correo utilizada no coincidía con la de ningún revisor oficialmente asignado. Como medida cautelar, la editorial revisó nuevamente la decisión sobre el manuscrito sin considerar esa evaluación. El caso ha reavivado el debate sobre la integridad, la seguridad y la transparencia del proceso de revisión por pares.
El investigador independiente Tushar Sen, especializado en ciberseguridad y residente en Nueva Delhi, denunció un presunto intento de extorsión durante el proceso de revisión por pares tras enviar un manuscrito sobre modelado de malware polimórfico a la revista Security and Privacy, publicada por Wiley. Días después del envío recibió varios correos electrónicos de una persona que afirmaba ser uno de los revisores del artículo. En ellos le indicaba que el trabajo aún no estaba preparado para su publicación, pero le proponía un «proceso de revisión de pago», asegurándole que, si aceptaba, revisaría el manuscrito en una semana y recomendaría su aceptación. Sen interpretó el mensaje como un intento de obtener dinero a cambio de una evaluación favorable y decidió no responder.
Tras ignorar la propuesta, el supuesto revisor continuó enviándole mensajes en los que advertía que, si no recibía respuesta, recomendaría el rechazo del manuscrito. Finalmente, el mismo día en que el individuo afirmó haber recomendado la denegación del artículo, Sen recibió la comunicación oficial de la revista notificándole el rechazo de su trabajo. Las observaciones incluidas en los informes de evaluación coincidían en parte con las críticas expresadas previamente en los correos del supuesto revisor, lo que reforzó las sospechas del investigador sobre una posible manipulación del proceso editorial. Convencido de que había sido víctima de un intento de soborno, Sen denunció inmediatamente el caso ante la revista.
El episodio tuvo un importante impacto personal sobre el investigador, quien afirmó haber sufrido una intensa ansiedad y una profunda pérdida de confianza en el sistema de revisión por pares. Según explicó, cada nuevo mensaje recibido le provocaba una gran angustia, hasta el punto de impedirle continuar con su trabajo diario. Posteriormente amplió sus denuncias enviando numerosos correos a Wiley, a la revista, al Committee on Publication Ethics (COPE), a profesores, periodistas y organismos estadounidenses como el FBI y la Securities and Exchange Commission (SEC), solicitando una auditoría independiente de los registros editoriales, una revisión ética completa de la revista y una nueva evaluación de su política editorial.
Por su parte, Wiley confirmó que su equipo de integridad de la investigación abrió una investigación formal tras recibir la denuncia y las copias de las conversaciones aportadas por Sen. La editorial recordó que los revisores tienen prohibido contactar directamente con los autores y que cualquier solicitud de compensación económica constituye una grave violación de las normas éticas. Sin embargo, también señaló que la dirección de correo electrónico utilizada por la persona que contactó con Sen no coincidía con la de ninguno de los revisores oficialmente invitados, por lo que no podía confirmar que realmente se tratara de un evaluador asignado al manuscrito ni garantizar la autenticidad de todos los mensajes. Aun así, como medida cautelar, Wiley decidió revisar nuevamente la decisión editorial sin tener en cuenta la evaluación atribuida al supuesto revisor implicado.
La investigación periodística realizada por Retraction Watch tampoco logró confirmar la identidad del individuo que envió los correos. La dirección electrónica dejó de estar operativa y las dos universidades argelinas con las que supuestamente estaba vinculado negaron que esa persona hubiera pertenecido a sus instituciones. Incluso un antiguo colaborador declaró que había interrumpido su relación científica precisamente porque nunca pudo verificar la identidad ni la afiliación académica del supuesto investigador, quien se presentaba como un investigador palestino independiente interesado en matemáticas y astronomía.
El caso se complicó además por el intercambio de mensajes entre Sen y el editor jefe de la revista, Mohammad S. Obaidat. En su denuncia, Sen acusó a la revista de estar «infectada por revisores corruptos» y sugirió que el editor podía estar implicado en el escándalo. Obaidat respondió agradeciendo la comunicación, pero reprochó al autor el uso de un lenguaje poco profesional y las acusaciones dirigidas contra la revista y sus responsables, advirtiéndole de las posibles consecuencias de formular imputaciones sin pruebas concluyentes.
En conjunto, el episodio pone de manifiesto las vulnerabilidades que pueden afectar al sistema de revisión por pares, desde posibles intentos de extorsión o suplantación de identidad hasta la dificultad de verificar la autenticidad de determinadas comunicaciones. Aunque Wiley considera que se trata de un caso aislado, la investigación ha reabierto el debate sobre la necesidad de reforzar los mecanismos de seguridad, confidencialidad y supervisión de los procesos editoriales para preservar la confianza en uno de los pilares fundamentales de la comunicación científica.
Han, C., Manoharan, S., Ye, X., & Speidel, U. (2026). Phantom citations: An empirical study of non-existent and unverifiable references in scholarly literature. Journal of the Association for Information Science and Technology. https://doi.org/10.1002/asi.70104
La integridad de la comunicación científica depende en gran medida de la precisión de las referencias bibliográficas. Las citas permiten verificar las fuentes utilizadas, contextualizar nuevos hallazgos y facilitar la reproducibilidad de la investigación. Sin embargo, la rápida incorporación de herramientas de inteligencia artificial generativa en la redacción académica ha incrementado la preocupación por la aparición de referencias inexistentes o imposibles de verificar, conocidas como phantom citations o citas fantasma.
Estas referencias presentan una apariencia completamente legítima —con autores, títulos, revistas e incluso DOI— pero no corresponden a ninguna publicación real. El estudio de Han y colaboradores aborda este problema mediante dos preguntas fundamentales: si es posible desarrollar una herramienta automática y auditable capaz de detectar este tipo de referencias y cuál es la magnitud real del fenómeno en publicaciones científicas recientes relacionadas con la inteligencia artificial y la educación.
Los autores revisan la literatura previa sobre errores bibliográficos y demuestran que el problema de las referencias incorrectas precede a la aparición de la IA generativa. No obstante, destacan que los grandes modelos de lenguaje han introducido una nueva modalidad de error: la generación automática de referencias completamente inventadas pero altamente plausibles. Diversos estudios previos muestran que modelos como GPT-3.5, GPT-4 o Bard producen porcentajes significativos de citas fabricadas, mientras que investigaciones recientes han detectado miles de referencias inexistentes incluso en artículos ya publicados y sometidos a revisión por pares. Estas referencias falsas no solo dificultan la verificación de los trabajos, sino que pueden propagarse a través de nuevas publicaciones, contaminar las redes de citación, alterar indicadores bibliométricos y comprometer revisiones sistemáticas y metaanálisis.
Para afrontar este desafío, el artículo desarrolla una herramienta de verificación bibliográfica automatizada basada en un proceso de múltiples etapas. El sistema extrae automáticamente las referencias de los documentos PDF mediante GROBID y posteriormente verifica cada una utilizando varias fuentes bibliográficas internacionales, entre ellas Crossref, OpenAlex, Semantic Scholar y arXiv. La metodología combina la comprobación de DOI, la validación de URL, la comparación de títulos mediante algoritmos de similitud, la coincidencia de autores y la verificación de fechas de publicación. Además, todas las referencias que no pueden resolverse automáticamente son revisadas manualmente antes de ser clasificadas definitivamente como «no verificables». Esta estrategia permite reducir tanto los falsos positivos como los falsos negativos y proporciona un procedimiento transparente y reproducible para evaluar la autenticidad de las referencias bibliográficas.
La evaluación empírica constituye una de las aportaciones más relevantes del estudio. Los investigadores analizaron un corpus formado por 3.201 artículos científicos revisados por pares, publicados entre 2023 y 2025 en congresos relacionados con la inteligencia artificial aplicada a la educación e indexados en IEEE Xplore, ACM Digital Library y SpringerLink. Los resultados muestran que 69 artículos (2,16 %) contenían al menos una referencia imposible de verificar mediante el protocolo desarrollado. La distribución no fue homogénea entre congresos: algunos presentaban porcentajes muy reducidos mientras que otros alcanzaban cifras superiores al 12 %. Asimismo, los autores observaron un incremento temporal preocupante, ya que los artículos con referencias no verificables pasaron del 0,73 % en 2023 al 3,61 % en 2025, aunque advierten que parte de este aumento puede deberse a diferencias entre las sedes de publicación analizadas.
El trabajo incluye además un estudio de caso que ilustra cómo una referencia generada por IA puede parecer completamente auténtica pese a no existir realmente. En el ejemplo analizado, el DOI no resolvía ningún registro, el título no aparecía en Google Scholar ni en IEEE Xplore y, aunque la revista citada era real, el artículo mencionado nunca había sido publicado. Este tipo de referencias suele construirse combinando patrones extraídos de publicaciones auténticas, lo que dificulta enormemente su detección durante la revisión editorial y aumenta el riesgo de que pasen inadvertidas para autores, revisores y editores.
Para validar la eficacia de su sistema, los autores compararon su herramienta con Hallucinator, uno de los programas de código abierto más conocidos para detectar referencias alucinadas. Sobre un conjunto de prueba formado por 731 referencias pertenecientes a 37 artículos, el sistema propuesto obtuvo una precisión del 92,9 %, un recall del 93,1 % y un F1 del 93 %, superando a Hallucinator en precisión y equilibrio global. Además, el nuevo sistema completó el análisis en apenas 13 minutos, frente a los 351 minutos requeridos por Hallucinator en su configuración estándar, lo que representa una mejora muy significativa tanto en rendimiento como en eficiencia computacional.
En la discusión final, los autores sostienen que la presencia de referencias imposibles de verificar constituye un nuevo desafío para la integridad científica. Argumentan que el fenómeno responde a una combinación de factores: la presión por publicar, la utilización creciente de herramientas de IA para redactar manuscritos, las limitaciones del proceso tradicional de revisión por pares y la falta de comprobación sistemática de las bibliografías. Como consecuencia, proponen incorporar procedimientos automáticos de verificación de referencias en los flujos editoriales de revistas y congresos, así como fomentar entre investigadores y revisores una cultura de comprobación rigurosa de todas las citas antes de la publicación. El estudio concluye que, aunque el porcentaje de artículos afectados todavía es relativamente reducido, la tendencia observada justifica el desarrollo de nuevas herramientas y protocolos que preserven la fiabilidad de la comunicación científica en la era de la inteligencia artificial.
La industria china de las novelas web (web novels), uno de los mayores ecosistemas de literatura digital del mundo, atraviesa una profunda transformación debido a la irrupción de la inteligencia artificial generativa. Durante los últimos años, las principales plataformas de publicación alentaron el uso de herramientas de IA para aumentar la productividad de los autores, acelerar la generación de contenidos y satisfacer la enorme demanda de nuevos capítulos que caracteriza a este mercado. Sin embargo, el éxito de estas tecnologías ha terminado generando un problema inesperado: una avalancha de novelas producidas parcial o totalmente por inteligencia artificial que está deteriorando la calidad del catálogo y provocando una creciente desconfianza entre lectores y escritores.
El mercado chino de novelas web funciona mediante un modelo de publicación seriada en el que miles de autores publican capítulos diariamente. Los escritores suelen recibir ingresos en función del número de lecturas y de suscriptores, lo que crea una fuerte presión por producir grandes cantidades de contenido de forma continua. La aparición de modelos de lenguaje capaces de redactar escenas, diálogos e incluso capítulos completos permitió a muchos autores multiplicar su ritmo de publicación. Algunos utilizan la IA como herramienta de apoyo para desarrollar tramas o superar bloqueos creativos, mientras que otros generan prácticamente toda la obra mediante algoritmos, limitándose a revisar el texto antes de publicarlo.
Esta automatización ha provocado un aumento espectacular del volumen de obras disponibles, pero también una disminución perceptible de su calidad. Los lectores denuncian que muchas historias presentan personajes repetitivos, argumentos previsibles, inconsistencias narrativas y abundantes errores derivados del uso excesivo de la IA. En numerosos casos resulta difícil distinguir unas novelas de otras, ya que los modelos tienden a reproducir estructuras argumentales similares y clichés propios de los géneros más populares, como la fantasía, el romance o las novelas de cultivo (xianxia). La sensación de saturación está afectando negativamente a la experiencia de lectura y a la confianza del público en las plataformas digitales.
Los autores humanos también manifiestan una creciente preocupación. Muchos consideran que las herramientas generativas facilitan la aparición de obras derivadas que reutilizan estilos, personajes o tramas existentes sin autorización. Existe además el temor de que los modelos hayan sido entrenados utilizando millones de novelas publicadas previamente sin el consentimiento de sus creadores, reproduciendo así el mismo debate sobre derechos de autor que actualmente afecta a otros sectores culturales. Para numerosos escritores profesionales, la IA no solo incrementa la competencia, sino que amenaza el valor económico de su trabajo al inundar el mercado con contenidos de producción masiva.
Ante esta situación, las grandes plataformas chinas de literatura digital han comenzado a modificar su estrategia. Empresas que inicialmente promovían el uso de la inteligencia artificial están implantando nuevas normas para limitar su utilización. Algunas exigen que los autores declaren expresamente si han empleado IA durante el proceso creativo, mientras que otras desarrollan sistemas automáticos para detectar textos generados artificialmente y penalizar aquellos que presenten un uso excesivo de estas herramientas. El objetivo es preservar la confianza de los lectores y evitar que el catálogo quede dominado por contenido automatizado de baja calidad.
El reportaje muestra que la cuestión no consiste únicamente en decidir si la IA debe utilizarse o no, sino en determinar cuál debe ser su papel dentro del proceso creativo. Muchos escritores defienden un uso complementario, empleando la inteligencia artificial para tareas como la documentación, la corrección gramatical, la generación de ideas o la planificación de escenas, pero consideran que la construcción narrativa, el desarrollo de personajes y el estilo literario deben seguir siendo responsabilidad del autor humano. Esta posición intenta encontrar un equilibrio entre aprovechar las ventajas tecnológicas y mantener la originalidad y la calidad artística de las obras.
El caso de las novelas web chinas constituye un ejemplo especialmente significativo porque este sector es uno de los mayores laboratorios mundiales de creación digital. Millones de lectores consumen diariamente historias publicadas en plataformas que funcionan con algoritmos de recomendación y modelos de monetización basados en la frecuencia de publicación. Las tensiones surgidas entre productividad, creatividad y calidad anticipan debates que probablemente aparecerán también en otros ámbitos editoriales, como la prensa, la edición de libros, los guiones audiovisuales o la creación de contenidos para redes sociales.
En conjunto, el artículo muestra cómo una tecnología inicialmente concebida para aumentar la eficiencia ha terminado obligando a replantear las reglas de producción y distribución de contenidos. La experiencia de las plataformas chinas demuestra que la inteligencia artificial puede acelerar extraordinariamente la creación literaria, pero también que un uso indiscriminado puede erosionar la confianza de los lectores, devaluar el trabajo de los autores y saturar el mercado con obras poco diferenciadas. El desafío para la industria será encontrar mecanismos que permitan aprovechar el potencial de la IA sin sacrificar la creatividad, la diversidad y la autenticidad que constituyen el principal valor de la literatura.
El crecimiento del uso de herramientas de inteligencia artificial como ChatGPT, Gemini o Claude ha generado una nueva preocupación en ámbitos como la educación, el periodismo, la contratación de personal y la creación de contenidos: ¿es posible distinguir con fiabilidad un texto escrito por una persona de otro generado por una IA? Para responder a esta pregunta, Popular Science realizó una prueba práctica con cinco de los detectores de IA más populares del mercado: Pangram, Grammarly, GPTZero, Scribbr y Copyleaks.
Los detectores de texto generado por inteligencia artificial se han convertido en una herramienta habitual en escuelas, universidades y empresas preocupadas por el uso de modelos como ChatGPT, Gemini o Claude. Sin embargo, una prueba realizada por Popular Science demuestra que estas aplicaciones están lejos de ser infalibles. El artículo evaluó cinco detectores ampliamente utilizados enfrentándolos tanto a textos escritos íntegramente por una persona como a otros producidos por diferentes modelos de IA.
El objetivo era comprobar si realmente pueden distinguir con precisión entre escritura humana y escritura artificial. Los resultados revelan que todos los sistemas analizados cometieron errores, aunque en distinta medida, lo que pone de manifiesto las limitaciones actuales de esta tecnología.
La principal conclusión es que ningún detector ofrece una fiabilidad del 100 %. Algunas herramientas identificaron correctamente buena parte de los textos generados por IA, pero también clasificaron como artificiales escritos completamente humanos (falsos positivos) y, a la inversa, consideraron como humanos algunos textos creados por modelos de lenguaje (falsos negativos). Esta variabilidad se debe a que los detectores no reconocen el origen real de un documento, sino que calculan la probabilidad de que un texto presente determinados patrones estadísticos característicos de la escritura generada por IA, como la baja «perplejidad» o una estructura lingüística especialmente uniforme.
Pangram: el detector más preciso
La primera herramienta evaluada fue Pangram, que se presenta como «un detector de IA que realmente funciona». En la prueba obtuvo un resultado perfecto. Reconoció correctamente ambos textos escritos por el autor como completamente humanos, asignándoles un 100 % de probabilidad de autoría humana y un alto grado de confianza. Del mismo modo, identificó correctamente los textos generados por ChatGPT y Claude como escritos íntegramente por IA. Además de emitir un porcentaje, explicó qué expresiones o estructuras habían influido en su decisión, señalando algunas frases típicas del estilo de los modelos de lenguaje.
Grammarly: muy fiable, aunque menos contundente
La segunda herramienta fue Grammarly, conocida tradicionalmente por sus funciones de corrección ortográfica y gramatical, pero que también incorpora un detector de IA. Los dos textos humanos fueron clasificados correctamente como escritos por una persona, sin detectar ningún patrón asociado a inteligencia artificial. Sin embargo, cuando analizó los textos generados por Claude y Gemini, sí detectó que probablemente habían sido creados mediante IA, aunque con un grado de confianza inferior al de Pangram: uno recibió una probabilidad del 68 % y el otro del 66 % de haber sido generado artificialmente. Es decir, Grammarly acertó en todos los casos, aunque mostró mayor cautela en sus conclusiones.
GPTZero: otra de las herramientas más fiables
El tercer detector fue GPTZero, una de las aplicaciones más conocidas en el ámbito educativo y universitario. Los dos textos escritos por el autor fueron clasificados como completamente humanos, indicando incluso que existía una elevada confianza en esa conclusión. Cuando analizó los textos producidos por Gemini y ChatGPT también los identificó correctamente como generados por inteligencia artificial. Una característica interesante de GPTZero es que no solo ofrece una valoración global, sino que señala las frases concretas que considera más características de un texto generado por IA. Sin embargo, el propio autor reconoce que, al revisar esas frases, no siempre resulta evidente qué rasgos específicos justifican dicha clasificación.
Scribbr: el gran decepcionante
La cuarta herramienta fue Scribbr, conocida principalmente por sus servicios de revisión académica. En este caso, el detector identificó correctamente los textos humanos como escritos por personas. Sin embargo, falló completamente al analizar los textos generados por IA, clasificándolos también como totalmente humanos. Lo más llamativo es que el sistema mostró una elevada confianza en sus conclusiones erróneas, lo que pone de manifiesto una calibración insuficiente para detectar contenidos generados por modelos actuales.
Copyleaks: resultados irregulares
El último detector analizado fue Copyleaks, una plataforma que también ofrece herramientas para detectar imágenes y vídeos generados mediante IA. Como ocurrió con los demás detectores, identificó correctamente los textos humanos. Sin embargo, al evaluar los textos generados por IA obtuvo resultados contradictorios: uno de ellos fue clasificado erróneamente como completamente humano, mientras que el otro fue detectado correctamente como generado por inteligencia artificial. Esta inconsistencia llevó al autor a concluir que la calibración del sistema todavía necesita mejoras.
Detector
Textos humanos
Textos IA
Resultado
Pangram
✔✔
✔✔
4/4
Grammarly
✔✔
✔✔
4/4
GPTZero
✔✔
✔✔
4/4
Scribbr
✔✔
✘✘
2/4
Copyleaks
✔✔
✔✘
3/4
El reportaje explica que basta con realizar pequeñas modificaciones en un texto generado por IA para dificultar considerablemente su detección. Una revisión manual, la incorporación de experiencias personales o incluso el uso de herramientas de reformulación pueden alterar los patrones lingüísticos que utilizan los detectores para emitir sus predicciones. Del mismo modo, textos escritos por personas con un estilo muy formal, repetitivo o académico pueden ser erróneamente etiquetados como contenidos generados por inteligencia artificial. Esta limitación resulta especialmente preocupante en el ámbito educativo, donde ya se han documentado casos de estudiantes acusados injustamente debido a la confianza excesiva depositada en estas herramientas.
Otra conclusión importante del análisis es que los detectores deben considerarse únicamente un indicio y nunca una prueba definitiva. El artículo coincide con numerosos investigadores y organismos educativos en que estas herramientas pueden servir para señalar textos que merecen una revisión más detallada, pero no deberían utilizarse como única evidencia para sancionar a un estudiante o cuestionar la autoría de un documento. La mejor práctica consiste en combinar su uso con otros métodos de evaluación, como el seguimiento del proceso de escritura, entrevistas con el autor, versiones previas del trabajo o actividades presenciales que permitan verificar el aprendizaje.
En conjunto, la prueba de Popular Science confirma que los detectores de IA siguen siendo una tecnología inmadura. Aunque han mejorado respecto a sus primeras versiones y pueden ofrecer información útil en determinados contextos, la rápida evolución de los modelos generativos hace que la carrera entre generación y detección sea cada vez más difícil. La tendencia actual apunta a que, más que confiar ciegamente en algoritmos de detección, instituciones educativas y organizaciones deberán desarrollar nuevas estrategias de evaluación y políticas de uso responsable de la inteligencia artificial.
Un análisis publicado por Nature revela la existencia de un mercado internacional altamente organizado dedicado a la venta de autorías científicas, una de las manifestaciones más preocupantes del fraude en la comunicación académica. La investigación recopiló una base de datos con más de 18.700 anuncios publicados entre marzo de 2020 y abril de 2026 por siete grandes paper mills —empresas que producen artículos científicos fraudulentos o de escasa calidad y comercializan puestos de autoría—, poniendo de manifiesto que estas prácticas se han convertido en una industria transnacional con un elevado volumen económico.
El estudio muestra que el precio por ocupar la posición de primer autor oscila desde 57 dólares hasta más de 5.600 dólares, con una mediana cercana a los 800 dólares. Las ofertas se difundían principalmente mediante canales de Telegram y páginas web especializadas, dirigidas especialmente a investigadores sometidos a fuertes presiones para publicar, procedentes de regiones como Oriente Medio, Asia Central, Europa del Este e India. Además de artículos científicos, algunas organizaciones ofrecían también autorías en libros, patentes, premios académicos e incluso otros servicios destinados a mejorar artificialmente el prestigio profesional de los clientes.
Los investigadores sostienen que estos negocios van mucho más allá de la producción de manuscritos falsificados. En realidad, operan como empresas especializadas en la manipulación de la reputación científica, aprovechando un sistema académico donde las publicaciones siguen siendo el principal indicador para acceder a promociones, financiación y reconocimiento profesional. Esta dinámica alimenta un mercado que responde directamente a la presión del modelo de «publicar o perecer».
La investigación también demuestra que una parte de estos trabajos fraudulentos consigue superar los procesos editoriales y llegar a revistas científicas de prestigio. Al comparar cientos de anuncios con publicaciones reales, los autores identificaron 53 artículos publicados cuyos títulos coincidían con las ofertas de venta de autoría; únicamente cinco habían sido retractados. Entre las revistas afectadas aparecen publicaciones de grandes editoriales internacionales como Springer Nature, Wiley, Elsevier, Frontiers y Taylor & Francis, además de actas de congresos del IEEE, lo que evidencia que incluso los sistemas editoriales más consolidados siguen siendo vulnerables a estas prácticas.
El estudio concluyó que ocupar la posición de primer autor tiene un coste medio cercano a los 800 dólares, con precios que oscilan entre 57 y más de 5.600 dólares. Los resultados se describen en un preprint enviado al repositorio arXiv. La base de datos también pone de manifiesto el alcance internacional de las paper mills. Los investigadores localizaron anuncios en Telegram relacionados con operaciones en India, Irak y Uzbekistán, además de miles de anuncios procedentes de sitios web vinculados a empresas establecidas en Rusia, Letonia, Kazajistán y Ucrania. Las siete paper mills analizadas anunciaban la venta de puestos de autoría en artículos científicos, mientras que algunas también ofrecían la posibilidad de figurar como autores de libros de texto, patentes y otros productos académicos, además de servicio relacionados con la obtención de premios y reconocimientos académicos.
El análisis también sugiere que algunos manuscritos producidos por estas organizaciones llegan a publicarse. Los periodistas de Nature revisaron más de 600 anuncios vinculados a unos 400 artículos e identificaron 53 trabajos publicados cuyos títulos coincidían con los de los anuncios. Solo cinco de ellos habían sido retractados.
Los autores consideran que la base de datos recopilada puede convertirse en una herramienta valiosa para editores y editoriales científicas. El análisis de los anuncios permitirá desarrollar mecanismos automáticos para detectar manuscritos sospechosos, identificar revistas especialmente expuestas y comprender mejor las estrategias comerciales empleadas por estas organizaciones. En un contexto donde el fraude científico evoluciona rápidamente y se beneficia de nuevas tecnologías y plataformas digitales, disponer de este tipo de información resulta esencial para reforzar la integridad de la investigación y proteger la credibilidad de la literatura científica.
Besançon, Lonni; Cabanac, Guillaume; Labbé, Cyril; Magazinov, Alexander; di Scala, Jules; Tkaczyk, Dominika; Weber-Boer, Kathryn (2025).Detection of metadata manipulations: Finding sneaked references in the scholarly literature. Preprint enviado a Journal of the Association for Information Science and Technology (JASIST). arXiv:2501.03771. Disponible en: arXiv – Detection of metadata manipulations
La investigación demuestra que la infraestructura global de comunicación científica presenta una vulnerabilidad crítica: es posible manipular artificialmente el impacto académico insertando citas inexistentes en los metadatos de un artículo sin alterar el documento publicado, comprometiendo así la fiabilidad de los sistemas internacionales de evaluación basados en citación. Los resultados son extraordinariamente reveladores. El análisis de 4.077 documentos identificó más de 80.000 referencias fraudulentas insertadas artificialmente, distribuidas en 2.787 artículos manipulados.
Este trabajo constituye una de las investigaciones más inquietantes y relevantes de los últimos años en el ámbito de la integridad científica, al revelar una nueva forma de manipulación bibliométrica basada en la inserción de lo que los autores denominan “sneaked references” o referencias infiltradas. Se trata de citas que no aparecen en el texto visible ni en la bibliografía real de un artículo científico, pero que sí son introducidas artificialmente en los metadatos depositados en infraestructuras académicas como Crossref, permitiendo que sistemas bibliométricos las contabilicen como citas legítimas. El hallazgo cuestiona directamente la fiabilidad de numerosos indicadores de impacto científico utilizados globalmente, desde el índice h hasta métricas institucionales empleadas en rankings universitarios, financiación de proyectos o evaluación académica.
El estudio se centra inicialmente en el caso del International Journal of Innovative Science and Research Technology (IJISRT), una revista en la que los investigadores detectaron un patrón sistemático de inserción fraudulenta de referencias adicionales durante el registro de metadatos. Estas referencias eran invisibles para cualquier lector que consultara el PDF del artículo, pero aparecían en los registros enviados a Crossref, generando citas falsas que beneficiaban principalmente a artículos publicados en la misma revista. Este mecanismo constituye una variante sofisticada del conocido fenómeno del citation gaming, es decir, estrategias destinadas a inflar artificialmente el número de citas recibidas por revistas o artículos con el fin de mejorar indicadores de impacto y reputación científica.
Para detectar esta anomalía, los autores diseñan dos metodologías automatizadas innovadoras. La primera consiste en comparar la lista de referencias depositadas en los metadatos de Crossref con las referencias extraídas automáticamente del PDF mediante herramientas como GROBID, especializada en extracción estructurada de documentos académicos. La segunda técnica compara directamente el texto completo extraído del PDF con las cadenas textuales almacenadas en los registros de referencias de Crossref, utilizando algoritmos de similitud textual como la distancia de Levenshtein implementada en bibliotecas como RapidFuzz. Ambas metodologías buscan determinar si una referencia registrada en el sistema realmente aparece en el documento original o si ha sido añadida clandestinamente en la fase de indexación.
Los resultados son extraordinariamente reveladores. El análisis de 4.077 documentos identificó más de 80.000 referencias fraudulentas insertadas artificialmente, distribuidas en 2.787 artículos manipulados. Algunos artículos beneficiados llegaron a recibir cientos de citas indebidas, alcanzando cifras completamente anómalas en plataformas como Digital Science Dimensions o OpenAlex OpenAlex. El caso más extremo documentado en el artículo corresponde a un DOI que aparecía acreditado con aproximadamente 1.700 citas en Dimensions y 1.800 en OpenAlex, aunque una parte sustancial de esas citas provenían exclusivamente de referencias falsas introducidas en metadatos y nunca presentes en publicaciones reales. Esto demuestra que la manipulación logró atravesar múltiples sistemas de agregación científica y afectar directamente bases de datos utilizadas mundialmente para evaluar investigación.
Uno de los aspectos más preocupantes del estudio es que esta manipulación ocurre en una capa invisible para la mayoría de investigadores, bibliotecarios y evaluadores científicos. Tradicionalmente, las malas prácticas en citación implicaban añadir citas irrelevantes dentro del propio artículo, mediante coerción editorial o acuerdos entre autores. Sin embargo, el mecanismo identificado aquí opera después de la publicación, en el nivel de los metadatos depositados en infraestructuras centrales del ecosistema científico. Esto significa que incluso artículos perfectamente legítimos pueden convertirse, sin conocimiento de sus autores, en vehículos para generar citas artificiales que alteren métricas globales. El problema deja de ser un asunto editorial aislado para convertirse en una vulnerabilidad sistémica de la infraestructura internacional de comunicación científica.
Los investigadores intentaron además escalar el análisis a gran escala examinando más de 47 millones de documentos científicos procesados por Dimensions desde el año 2000, con el objetivo de detectar patrones similares en toda la literatura académica mundial. Aunque el procesamiento masivo presenta limitaciones técnicas, especialmente en la extracción automática de referencias desde archivos PDF, el estudio demuestra que existen mecanismos potenciales para auditar grandes volúmenes de literatura científica y detectar patrones anómalos de citación. Los autores también exploraron heurísticas basadas en referencias duplicadas dentro de registros Crossref como posible señal temprana de manipulación sistemática.
El artículo plantea profundas implicaciones para todo el ecosistema de comunicación científica. Si plataformas como Crossref, OpenAlex, Scopus o sistemas derivados utilizan metadatos potencialmente manipulados, entonces gran parte de los indicadores bibliométricos contemporáneos podrían estar sujetos a distorsiones invisibles. Los autores reclaman mecanismos de auditoría más rigurosos por parte de infraestructuras académicas, validaciones automáticas entre texto completo y metadatos depositados, así como mayor vigilancia sobre prácticas editoriales sospechosas. Más allá del caso específico investigado, el estudio abre una discusión fundamental sobre la fragilidad de los sistemas de evaluación científica contemporáneos y sobre cómo la obsesión por las métricas cuantitativas puede incentivar nuevas formas de fraude cada vez más sofisticadas y difíciles de detectar.
Sun, Yicheng, Yihan Liao, and Xiaoxue Ma. “Trusting AI to Detect AI? A Systematic Evaluation of the Reliability and Robustness of Current AIGC Detection Tools for Student Academic Work.” Computers & Education (2026). Elsevier. https://doi.org/10.1016/j.compedu.2026.105456
La investigación demuestra que los actuales detectores de texto generado por inteligencia artificial presentan problemas significativos de precisión, vulnerabilidad ante modificaciones simples y riesgo elevado de falsos positivos, por lo que no deben considerarse herramientas plenamente fiables para evaluar autoría académica, abriendo un debate más amplio sobre cómo la educación debe adaptarse a la presencia estructural de la inteligencia artificial en la escritura y el aprendizaje.
El estudio analiza uno de los debates más relevantes en el ámbito educativo contemporáneo: hasta qué punto pueden considerarse fiables las herramientas de inteligencia artificial diseñadas para detectar contenidos producidos por otros sistemas de IA generativa, especialmente en contextos académicos donde universidades, escuelas y docentes buscan identificar si un trabajo ha sido elaborado por estudiantes o generado parcial o totalmente mediante modelos como OpenAI ChatGPT, asistentes de escritura automatizada o generadores de texto similares. La investigación parte de una preocupación creciente: mientras las instituciones educativas adoptan detectores automáticos para preservar la integridad académica, todavía existe poca evidencia científica sólida acerca de la precisión real de estos sistemas y de sus limitaciones metodológicas.
Los autores realizaron una evaluación sistemática y comparativa de múltiples detectores de contenido generado por IA (AIGC detectors, Artificial Intelligence Generated Content detectors), sometiéndolos a pruebas extensivas con diferentes tipos de textos académicos producidos tanto por humanos como por sistemas de lenguaje avanzados. El objetivo era medir dos dimensiones fundamentales: la fiabilidad, entendida como la capacidad del sistema para clasificar correctamente un texto, y la robustez, es decir, la resistencia del detector frente a modificaciones o manipulaciones deliberadas destinadas a engañar al algoritmo. Los resultados muestran que muchas herramientas presentan inconsistencias importantes y no ofrecen un nivel de precisión suficientemente estable como para convertirse en un criterio único de evaluación académica.
Uno de los hallazgos más significativos es que numerosos detectores funcionan razonablemente bien cuando analizan textos generados directamente por modelos de lenguaje sin edición posterior, pero su rendimiento cae de manera drástica cuando el contenido es ligeramente modificado por una persona. Cambios mínimos como reformular frases, alterar el orden sintáctico, introducir expresiones más personales o corregir ciertos patrones lingüísticos pueden reducir notablemente la capacidad del sistema para identificar el origen artificial del texto. Esto revela que la mayoría de detectores dependen de patrones estadísticos superficiales relacionados con la predictibilidad léxica y la regularidad sintáctica, en lugar de comprender realmente la autoría del contenido.
La investigación también advierte sobre el problema inverso: los falsos positivos. En numerosas pruebas, textos completamente redactados por humanos fueron clasificados erróneamente como producidos por inteligencia artificial. Este aspecto resulta especialmente preocupante en contextos universitarios, ya que una detección incorrecta puede derivar en acusaciones injustas de fraude académico, cuestionamiento de la honestidad del estudiante o procedimientos disciplinarios basados en evidencia técnicamente poco fiable. El estudio subraya que confiar excesivamente en estas herramientas puede generar problemas éticos y legales, particularmente cuando las instituciones utilizan resultados automatizados como prueba concluyente en procesos de evaluación.
Otro aspecto analizado es la evolución constante de los grandes modelos lingüísticos (LLM, Large Language Models). Herramientas de detección entrenadas para reconocer patrones asociados a versiones anteriores de modelos como ChatGPT ChatGPT, Anthropic Claude o sistemas similares pueden volverse rápidamente obsoletas cuando aparecen modelos más sofisticados capaces de producir lenguaje cada vez más cercano a la escritura humana natural. Esto genera una especie de carrera tecnológica permanente: conforme mejoran los generadores de texto, los detectores deben actualizarse continuamente, aunque sin garantía de alcanzar precisión duradera.
El estudio examina además estrategias conocidas como evasión adversarial, es decir, técnicas intencionadas utilizadas para burlar detectores automáticos. Entre ellas se incluyen la paráfrasis automática, traducción múltiple entre idiomas, edición humana posterior, reformulación mediante otros modelos lingüísticos e incluso la mezcla de fragmentos humanos con contenido generado por IA. Los resultados demuestran que muchos detectores pierden efectividad frente a estas intervenciones relativamente simples, lo que pone en duda su utilidad práctica en escenarios reales donde un usuario busca deliberadamente evitar la detección.
Desde una perspectiva educativa, los investigadores plantean una reflexión importante: el problema no puede abordarse únicamente desde la lógica policial o punitiva. La expansión de herramientas generativas obliga a repensar los sistemas tradicionales de evaluación académica. Si resulta cada vez más difícil distinguir entre producción humana y producción asistida por IA, las universidades deben reconsiderar qué significa realmente aprender, escribir, investigar y demostrar competencias intelectuales en un entorno donde la inteligencia artificial forma parte habitual del proceso de trabajo. En lugar de centrarse exclusivamente en detectar fraude, el sistema educativo debería avanzar hacia modelos pedagógicos que integren críticamente la IA, enseñando al alumnado a utilizarla de manera ética, transparente y reflexiva.
Los autores concluyen que, aunque los detectores automáticos pueden servir como herramientas auxiliares dentro de procesos más amplios de evaluación, actualmente no ofrecen suficiente precisión, consistencia ni robustez como para convertirse en árbitros definitivos de la autenticidad académica. Recomiendan que cualquier institución educativa evite depender exclusivamente de sistemas automáticos y combine su uso con revisión humana, análisis contextual del trabajo, conocimiento previo del estilo del estudiante y nuevas estrategias pedagógicas orientadas a la alfabetización crítica en inteligencia artificial.
En términos más amplios, el estudio pone de relieve una paradoja tecnológica cada vez más evidente: se está utilizando inteligencia artificial para detectar inteligencia artificial, pero ambos sistemas evolucionan simultáneamente en una dinámica competitiva donde los mecanismos de control van siempre un paso detrás de las capacidades generativas. Esto plantea preguntas profundas no solo sobre integridad académica, sino sobre confianza, autoría intelectual y el futuro mismo de la producción del conocimiento en la era algorítmica
Bibliochecker ejemplifica cómo las nuevas herramientas de verificación automatizada pueden convertirse en aliadas estratégicas para preservar la integridad académica frente a los errores y alucinaciones producidas por la inteligencia artificial generativa.
En un contexto académico marcado por el uso creciente de sistemas de inteligencia artificial generativa como ChatGPT, Gemini o Claude, una de las preocupaciones más relevantes dentro de la investigación científica es la proliferación de “alucinaciones bibliográficas”, es decir, referencias inventadas o parcialmente incorrectas que los modelos generan al construir citas aparentemente plausibles pero inexistentes. Frente a este problema surge Bibliochecker, una herramienta web diseñada específicamente para verificar la autenticidad y consistencia de referencias bibliográficas generadas o asistidas por inteligencia artificial.
Bibliochecker se presenta como una aplicación accesible directamente desde el navegador, sin necesidad de instalación ni registro, lo que facilita su uso inmediato por parte de investigadores, estudiantes, bibliotecarios, editores científicos y revisores académicos. Su objetivo principal consiste en detectar posibles errores, inconsistencias o invenciones en listas bibliográficas, especialmente aquellas elaboradas mediante herramientas de IA. La plataforma automatiza la verificación cruzando la información proporcionada con bases de datos académicas consolidadas como CrossRef, Semantic Scholar y OpenAlex, lo que permite comprobar la existencia real de un documento, validar identificadores DOI y contrastar la coherencia entre título, autoría y fecha de publicación.
Una de sus fortalezas radica en la flexibilidad del ingreso de datos. El usuario puede introducir referencias de tres formas distintas: pegando directamente texto copiado desde documentos Word o PDF, cargando archivos en formato .docx que contengan exclusivamente la sección bibliográfica o utilizando ejemplos predeterminados para familiarizarse con el funcionamiento del sistema. La herramienta identifica automáticamente cada referencia incluso cuando estas aparecen en texto corrido o sin separación entre líneas, aplicando patrones inspirados en la normativa APA 7 para detectar estructuras bibliográficas.
El sistema permite activar distintos módulos de comprobación según las necesidades del usuario. El módulo de CrossRef verifica en tiempo real la validez del DOI y compara metadatos asociados; Semantic Scholar realiza búsquedas por similitud textual del título y verifica autoría y año; OpenAlex consulta su base académica abierta para confirmar coincidencias; mientras que un verificador específico examina si la referencia cumple con requisitos formales del estilo APA 7, revisando aspectos como el formato de autores, la correcta ubicación del año entre paréntesis, el uso de puntuación normativa o la presencia obligatoria del DOI en artículos científicos. Además, el sistema incorpora enlaces a Google Scholar para facilitar comprobaciones manuales complementarias.
Cada referencia analizada recibe un diagnóstico estructurado en cuatro categorías claramente diferenciadas. La categoría “Válida” indica que la obra fue localizada en las bases de datos sin inconsistencias detectadas. La categoría “Sospechosa” señala discrepancias parciales, como diferencias entre nombres de autores, títulos ligeramente distintos o inconsistencias cronológicas. La categoría “Problema” representa casos más graves, donde el DOI no existe o el documento no aparece en ninguna base académica consultada, sugiriendo una alta probabilidad de invención o error generado por IA. Finalmente, el estado “Sin DOI” identifica referencias donde no ha sido posible realizar validación automática mediante identificadores persistentes, algo frecuente en libros, tesis o documentos no indexados formalmente.
Otro elemento destacable es la posibilidad de exportar un reporte completo en formato HTML, generando una tabla estructurada con todos los resultados obtenidos. Este informe puede compartirse, archivarse o imprimirse, facilitando procesos editoriales, revisión académica o auditoría bibliográfica previa a la publicación de artículos científicos. La herramienta también incorpora distintos modos visuales —oscuro, claro y editorial sobrio— que mejoran la experiencia de uso en distintos contextos de trabajo.
Desde una perspectiva más amplia, Bibliochecker responde a una necesidad emergente dentro del ecosistema de la comunicación científica contemporánea: la verificación crítica de contenidos generados por inteligencia artificial. A medida que investigadores y estudiantes incorporan sistemas generativos en tareas de redacción académica, aumenta el riesgo de incluir citas falsas que comprometan la integridad científica. En este escenario, herramientas como Bibliochecker no sustituyen el criterio profesional humano, pero sí actúan como filtros preliminares de enorme valor para fortalecer la calidad documental y reducir errores antes de la difusión pública del conocimiento.
La propia plataforma insiste en una advertencia metodológica fundamental: sus resultados constituyen un apoyo automatizado y nunca un dictamen definitivo. Incluso una referencia marcada como válida puede contener errores que escapan a la detección automática, mientras que referencias catalogadas como sospechosas pueden corresponder a simples inconsistencias de metadatos o documentos no indexados en las bases consultadas. En otras palabras, Bibliochecker representa un ejemplo significativo del nuevo paradigma de colaboración entre inteligencia artificial y revisión humana experta, particularmente relevante para bibliotecas académicas, editoriales científicas y profesionales de la gestión de información digital.
An infographic explaining what AI detectors can confidently identify and where their analysis falls short.
Atamhenwan, Lucky E. (2026). How are combinations of human-written words and LLM-generated words by ChatGPT, Copilot, Gemini and Grammarly detected by Turnitin? Education and Information Technologies. Springer Nature. DOI: 10.1007/s10639-026-14049-2
La rápida expansión de herramientas de inteligencia artificial está transformando profundamente la educación y la escritura académica. Ante este cambio, universidades e instituciones recurren cada vez más a detectores automáticos como Turnitin para identificar textos generados por IA. El estudio de Lucky E. Atamhenwan analiza hasta qué punto Turnitin puede distinguir con precisión entre escritura humana y contenido producido total o parcialmente por inteligencia artificial.
La expansión acelerada de la inteligencia artificial generativa en los últimos años ha transformado profundamente la educación superior y los procesos de producción textual. La aparición de modelos de lenguaje de gran escala como ChatGPT, Microsoft Copilot, Google Gemini y Grammarly ha permitido que estudiantes, investigadores y profesionales generen textos complejos con rapidez y una calidad lingüística cada vez más cercana a la escritura humana. Frente a este nuevo escenario, instituciones educativas de todo el mundo han comenzado a depender de sistemas automáticos de detección de contenido generado por IA, siendo Turnitin una de las herramientas más utilizadas. El estudio de Lucky E. Atamhenwan se propone analizar hasta qué punto Turnitin es realmente capaz de diferenciar entre textos escritos por humanos y textos producidos, parcial o totalmente, mediante modelos de lenguaje artificial.
La investigación parte de una cuestión central: aunque numerosas universidades están comenzando a utilizar detectores automáticos de IA para evaluar trabajos académicos, existe todavía una gran incertidumbre acerca de la precisión real de estas herramientas. El autor recuerda que la irrupción masiva de ChatGPT en noviembre de 2022 marcó un punto de inflexión sin precedentes en la relación entre inteligencia artificial y educación. En apenas unos meses aparecieron múltiples sistemas generativos capaces no solo de redactar textos completos, sino también de resumir documentos, corregir gramática, traducir contenidos, programar código y reformular ideas con notable coherencia. Este avance ha generado enormes beneficios pedagógicos, pero también ha abierto interrogantes sobre plagio, autoría y honestidad académica, especialmente cuando los estudiantes presentan como propio un contenido producido parcial o totalmente por IA.
Para estudiar la eficacia de Turnitin, el investigador diseñó un experimento de gran escala basado en 81 documentos diferentes, construidos a partir de combinaciones variables entre escritura humana y texto generado por modelos de lenguaje. Los documentos contenían mezclas progresivas que iban desde un 100% de texto humano hasta un 100% de texto generado por IA, utilizando cuatro sistemas distintos: ChatGPT, Copilot, Gemini y Grammarly. Se crearon textos de aproximadamente 4.000 palabras y se fueron introduciendo porcentajes crecientes de contenido generado artificialmente: 5%, 10%, 15%, 20%, 30%, 50%, 70%, hasta llegar al 100%. Cada documento fue sometido al detector de Turnitin para observar qué porcentaje del contenido era identificado como generado por inteligencia artificial. Este diseño experimental permitió estudiar no solamente si Turnitin detecta IA, sino también cómo cambia su comportamiento cuando el texto combina escritura humana y escritura algorítmica.
Uno de los resultados más relevantes del estudio es que Turnitin no detectó absolutamente ningún contenido generado por IA cuando este representaba solo el 5% o el 10% del texto total. Esto significa que si un estudiante escribe la mayor parte de un trabajo por sí mismo y utiliza un modelo de lenguaje únicamente para generar pequeños fragmentos, Turnitin puede no generar ninguna alerta. A partir de porcentajes cercanos al 15%, el sistema comienza a identificar contenido sospechoso, pero con un problema importante: las puntuaciones no son exactas. Cuando el porcentaje real de texto generado por IA es bajo, Turnitin suele sobreestimar la cantidad de contenido artificial, produciendo falsos incrementos. Paradójicamente, cuando el porcentaje real de IA es muy alto, el detector comienza a subestimar la presencia artificial, mostrando cifras inferiores a la realidad. Esta inconsistencia cuestiona seriamente la confianza absoluta en el sistema.
El comportamiento del detector varía además según el modelo de lenguaje utilizado. En el caso de ChatGPT, Turnitin mostró una tendencia sistemática a detectar porcentajes inferiores al contenido real generado por IA. Incluso cuando un texto estaba producido al 100% por ChatGPT, Turnitin solo identificó un 60% como artificial. Con Copilot y Gemini los resultados fueron algo más equilibrados, aunque igualmente inconsistentes: en algunos casos sobreestimaban la presencia de IA y en otros la reducían. Grammarly presentó un patrón diferente, con detecciones superiores al porcentaje real cuando la intervención de IA era baja, pero subestimaciones cuando aumentaba la proporción de texto generado automáticamente. Esto demuestra que no existe un criterio homogéneo y que el detector responde de manera distinta según las características lingüísticas propias de cada modelo de inteligencia artificial.
Un segundo bloque del estudio analiza un fenómeno cada vez más extendido: el uso de herramientas diseñadas específicamente para “humanizar” textos creados por IA con el objetivo de evitar ser detectados. Para ello se utilizaron plataformas como QuillBot, EasyEssayAI y RyneAI, muy conocidas en comunidades digitales por su capacidad para reformular textos y hacerlos parecer escritos por humanos. Los investigadores tomaron textos generados al 100% por ChatGPT, Copilot, Gemini y Grammarly, y posteriormente los pasaron por estas herramientas de reformulación antes de volver a analizarlos en Turnitin. Los resultados fueron especialmente reveladores: textos completamente generados por Copilot y posteriormente reformulados con QuillBot obtuvieron una puntuación del 0%, es decir, Turnitin los consideró completamente humanos. De manera similar, RyneAI consiguió que textos enteramente generados por Copilot, Gemini o Grammarly fueran clasificados también con 0% de contenido artificial.
Desde un punto de vista estadístico, el estudio confirma que existe una correlación muy fuerte entre la cantidad real de texto generado por IA y la puntuación otorgada por Turnitin. Sin embargo, esta relación no implica precisión. Los análisis de correlación y regresión muestran que el sistema detecta patrones asociados al texto artificial, pero no logra cuantificar de manera fiable cuánto contenido ha sido realmente producido por inteligencia artificial. El modelo estadístico utilizado revela que el 82,5% de la variabilidad observada en las puntuaciones depende efectivamente de la presencia de texto generado por IA, pero el margen de error sigue siendo considerable. En otras palabras: Turnitin reconoce señales asociadas al uso de IA, pero no constituye una herramienta exacta para determinar porcentajes reales de autoría algorítmica.
Las implicaciones educativas del trabajo son profundas. El autor sostiene que las universidades no deberían utilizar las puntuaciones de Turnitin como prueba concluyente para sancionar estudiantes, especialmente cuando los porcentajes detectados son bajos o moderados. Según el estudio, puntuaciones inferiores al 40% deben interpretarse con gran cautela, mientras que valores superiores al 60% pueden ser indicativos más sólidos, aunque nunca definitivos. Más allá de la detección, el artículo plantea que el verdadero desafío no consiste en prohibir la inteligencia artificial, sino en redefinir el modo en que se evalúa el aprendizaje. A medida que los modelos generativos evolucionen, será cada vez más difícil impedir su uso en tareas escritas tradicionales. Esto obliga a replantear metodologías de evaluación, incorporando sistemas supervisados, navegadores bloqueados, evaluaciones presenciales y nuevas formas de demostrar conocimiento que no dependan exclusivamente de la producción textual.
El estudio concluye que la educación necesita abandonar la visión puramente punitiva sobre la inteligencia artificial y avanzar hacia un modelo de integración ética y transparente. La IA debe entenderse como una herramienta legítima de aprendizaje, siempre que existan normas claras sobre su uso. El autor propone una cooperación entre universidades, empresas tecnológicas y plataformas como Turnitin para desarrollar sistemas que no solo detecten contenido generado por IA, sino que permitan rastrear el origen y el proceso de creación de los textos. En definitiva, esta investigación desmonta la idea de que los detectores actuales sean infalibles y muestra que, en el contexto actual, confiar ciegamente en estas herramientas para tomar decisiones académicas puede generar errores, injusticias y conflictos éticos considerables. Más que una solución definitiva, los detectores de IA representan apenas una tecnología en desarrollo dentro de un escenario educativo que está cambiando a una velocidad sin precedentes.
Datos clave:
Precisión con textos humanos: Turnitin no arrojó falsos positivos en el texto escrito completamente por humanos (0% de puntuación de IA).
Umbral mínimo de detección: Turnitin no detectó la presencia de IA cuando el porcentaje real de texto generado por los LLM era del 5% o 10% (marcando 0% en la puntuación).
Distorsión en porcentajes bajos (Inexactitud por exceso): Cuando la cantidad de IA era baja pero detectable (ej. 15% o 20%), Turnitin tendió a sobreestimar el puntaje, otorgando porcentajes de IA detectada más altos que la realidad (ej. detectó entre 21% y 24% para un 15% real).
Distorsión en porcentajes altos (Inexactitud por defecto): A medida que aumentaba el texto de IA en la combinación, el detector tendió a subestimar el puntaje real. Al llegar al 100% de contenido de IA en textos largos (4,000 palabras), Turnitin nunca puntuó 100%; las calificaciones máximas para textos puros de IA fueron de 87% (Copilot/Gemini), 82% (Grammarly) y apenas un 60% (ChatGPT).
Correlación: Existe una relación positiva muy fuerte ($R^2$ de Nagelkerke = 0.825): a mayor porcentaje real de IA, mayor es la puntuación de detección de Turnitin, confirmando que la detección se debe efectivamente a los fragmentos de IA
ChatGPT: Fue el modelo que más «burló» el detector en formato mixto. Turnitin puntuó por debajo de la realidad en el 65% de sus textos. Incluso al 25% de contenido real de ChatGPT, Turnitin marcó 0%.
Copilot y Gemini: Siguieron un comportamiento similar entre sí; Turnitin tendió a sobreestimar el porcentaje de IA en rangos bajos y medianos, pero empezó a reportar por debajo de la realidad a partir del 75% de contenido de IA.
Grammarly: Turnitin detectó niveles inflados (más altos que la realidad) entre el 15% y 40% de contenido, pero empezó a puntuar por debajo del porcentaje real a partir del 45% de texto generado por Grammarly.
RyneAI: Fue la herramienta de evasión más efectiva. Logró reducir la puntuación de Turnitin a 0% para Copilot, Grammarly y Gemini (haciendo que el detector los aceptara por completo como humanos). Para ChatGPT, la redujo al 26%.
QuillBot (AI Humanizer): Consiguió reducir la puntuación de Copilot a 0%. Sin embargo, fue menos efectivo con los demás: ChatGPT (33%), Grammarly (62%) y Gemini (83%).
EasyessayAI: Fue la menos efectiva. Turnitin siguió detectando altas tasas de IA en los textos procesados: Copilot (80%), ChatGPT (65%), Gemini (63%) y Grammarly (56%).
Efecto de la longitud del texto: El estudio demostró que Turnitin es mucho más preciso detectando textos puramente de IA cuando el documento es más corto (500-1000 palabras frente a las 4000 de la primera fase).
Dahl, Josh. “Guest Post — Is Growth Always Good News? 2026 Article Submission Surges”. The Scholarly Kitchen, 13 de mayo de 2026. Disponible en: The Scholarly Kitchen
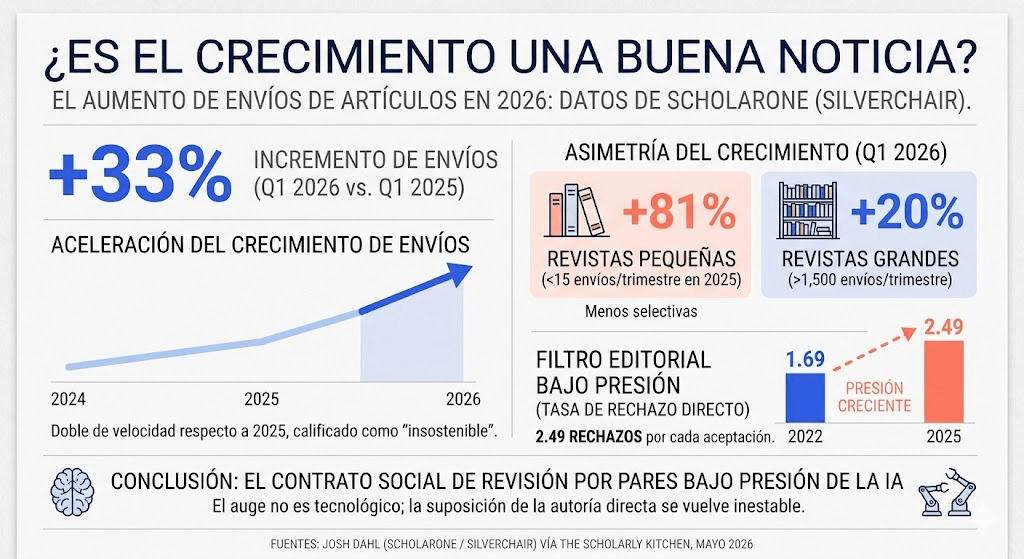
Una cuestión que está generando creciente preocupación en la comunicación científica: el espectacular aumento de manuscritos enviados a las revistas cientificas durante 2026 y el papel que la inteligencia artificial podría estar desempeñando en este fenómeno. Basándose en datos de la plataforma ScholarOne Manuscripts, una de las mayores infraestructuras mundiales de gestión editorial, Dahl revela que durante el primer trimestre de 2026 las revistas recibieron un 33 % más de artículos que en el mismo período del año anterior. Lo más llamativo no es únicamente la magnitud del crecimiento, sino su aceleración: mientras que en 2025 el incremento había sido del 17 %, en 2026 prácticamente se duplicó. Para muchos editores y responsables de revistas, esta tendencia empieza a parecer insostenible.
El autor evita interpretar automáticamente estos datos como una señal positiva. A primera vista, podría pensarse que estamos asistiendo a una expansión saludable de la actividad investigadora mundial. Más investigadores, más proyectos y más artículos podrían indicar un fortalecimiento del sistema científico. Sin embargo, Dahl advierte que los datos permiten otra lectura menos optimista. La proliferación de herramientas de inteligencia artificial generativa ha reducido drásticamente el esfuerzo necesario para producir textos académicos, lo que podría estar favoreciendo una avalancha de manuscritos elaborados con ayuda de sistemas automatizados. El problema no sería únicamente la cantidad de artículos, sino la posible disminución de la calidad media y el aumento de trabajos producidos con escasa supervisión intelectual.
Uno de los hallazgos más reveladores del análisis es que el crecimiento no se distribuye de forma homogénea entre las revistas. Las publicaciones más pequeñas y menos selectivas son las que están experimentando los mayores aumentos. Las revistas que recibían menos de quince artículos por trimestre registraron incrementos cercanos al 81 %, mientras que las grandes publicaciones, con más de 1.500 envíos trimestrales, crecieron aproximadamente un 20 %. Este patrón no demuestra por sí mismo que exista una invasión de manuscritos generados por IA, pero sí resulta compatible con esa hipótesis. Los autores que buscan publicar rápidamente podrían estar orientando sus envíos hacia revistas con menos recursos editoriales y menores barreras de entrada, precisamente aquellas que tienen más dificultades para detectar problemas metodológicos, éticos o de autoría.
El artículo destaca asimismo que los mecanismos de filtrado editorial ya están reaccionando a esta presión. Entre 2022 y 2025, los rechazos iniciales sin revisión por pares (desk rejections) aumentaron un 72 %, mientras que el número total de decisiones editoriales creció un 43 %. En otras palabras, los editores están rechazando proporcionalmente más trabajos antes de enviarlos a revisión externa. Esta tendencia sugiere que las revistas están absorbiendo una creciente cantidad de manuscritos considerados inadecuados, irrelevantes o insuficientemente elaborados. El sistema editorial continúa funcionando como filtro, pero lo hace a costa de una carga de trabajo cada vez mayor.
Para Dahl, el verdadero problema no es tecnológico, sino social. El sistema de revisión por pares se construyó sobre una premisa fundamental: que el investigador es el autor intelectual del texto que presenta, comprende plenamente su contenido y puede defender cada afirmación, referencia y conclusión. La inteligencia artificial ha introducido una zona de ambigüedad que desafía ese supuesto. Entre una simple corrección gramatical y la generación completa de borradores existe un amplio espectro de usos de la IA para el que todavía no existen normas claras ni consensos sólidos. La frontera entre asistencia legítima y delegación excesiva de la escritura se vuelve cada vez más difusa.
El autor pone como ejemplo el problema de las referencias bibliográficas inventadas por los modelos de lenguaje. Un investigador puede utilizar una herramienta de IA para redactar parte de un artículo y recibir citas aparentemente válidas que en realidad no existen. Aunque no haya intención deliberada de fraude, el manuscrito acaba incorporando información falsa. Este tipo de situaciones revela una brecha entre los actuales sistemas de responsabilidad científica y las nuevas prácticas de escritura asistida por inteligencia artificial. Los mecanismos tradicionales de autoría y rendición de cuentas fueron diseñados para un entorno en el que la producción textual era completamente humana.
Otro aspecto destacado es la dimensión psicológica del fenómeno. Dahl sostiene que el uso de IA para redactar textos académicos no genera la misma percepción moral que prácticas claramente fraudulentas como la contratación de empresas que venden artículos científicos. Muchos investigadores consideran que utilizar IA para escribir partes de un manuscrito es simplemente una herramienta de productividad. El razonamiento suele ser que las ideas, los datos y la investigación siguen siendo propios, aunque la redacción haya sido parcialmente automatizada. Esta normalización puede resultar más problemática que el fraude deliberado porque es mucho más fácil de escalar y puede afectar a miles de investigadores que no se consideran deshonestos.
Las consecuencias se extienden también al sistema de revisión por pares. Cada nuevo artículo enviado requiere revisores y tiempo editorial. Sin embargo, la disponibilidad de revisores lleva años disminuyendo. La fatiga asociada a la evaluación científica ya era un problema antes de la explosión de la IA, pero el incremento del 33 % en los envíos amenaza con agravar una situación que muchos consideran crítica. De hecho, datos complementarios citados en la discusión del artículo indican que las tasas de respuesta de revisores han descendido significativamente durante los últimos años. Esto significa que el sistema recibe más manuscritos precisamente cuando dispone de menos capacidad para evaluarlos rigurosamente.
Particularmente vulnerables aparecen las revistas pequeñas, gestionadas frecuentemente por editores a tiempo parcial, comités voluntarios o sociedades científicas con recursos limitados. Son estas publicaciones las que están absorbiendo la mayor parte del crecimiento de envíos y las que disponen de menos infraestructura para afrontar el problema. Dahl considera que esta situación pone de manifiesto una debilidad estructural del ecosistema editorial académico: la insuficiente inversión histórica en capacidades editoriales y mecanismos de control en los márgenes del sistema científico.
La conclusión del artículo es que el aumento de envíos no debe interpretarse únicamente como un desafío tecnológico ni resolverse exclusivamente mediante detectores de IA o herramientas automáticas de control. Lo que está en juego es la propia arquitectura de confianza sobre la que se construye la comunicación científica. La explosión de manuscritos en 2026 funciona como una prueba de estrés que obliga a replantear cuestiones fundamentales: cómo redefinir la responsabilidad de los autores en la era de la IA, cómo sostener la participación de los revisores y cómo proteger a las revistas más vulnerables frente a una presión creciente. Más que una crisis de software, Dahl ve en estos datos una señal de que el contrato social que sustenta la revisión por pares necesita ser revisado y adaptado a un entorno donde la producción científica ya no es exclusivamente humana.