
Copiar de un autor es plagio, copiar de muchos es investigación
Isabel Allende «Afrodita»
Copiar de un autor es plagio, copiar de muchos es investigación
Isabel Allende «Afrodita»

Vara, Vauhini. “How to Tell AI Writing.” The Atlantic, mayo de 2026. Disponible en: The Atlantic
Se analiza una cuestión cada vez más relevante: si realmente es posible identificar cuándo un texto ha sido escrito por inteligencia artificial. La autora parte de una constatación evidente: a medida que los modelos lingüísticos mejoran, los métodos tradicionales de detección resultan menos fiables. Los detectores automáticos producen numerosos falsos positivos y falsos negativos, lo que dificulta establecer con certeza el origen de un texto.
En las encuestas, la gente afirma de forma consistente que desconfía de los textos generados por IA. Sin embargo, eso no ha impedido que cada vez más personas la utilicen en la vida cotidiana: para redactar correos de trabajo y mensajes personales, elaborar listas de la compra o incluso escribir guiones para discutir con sus parejas. La escritura generada por IA también se está infiltrando en los espacios literarios más prestigiosos: secciones de opinión de periódicos, libros y revistas literarias. Estos textos son perfectamente limpios, sin una coma fuera de lugar; de extensión uniforme, con párrafos equilibrados y un tono característico que resulta al mismo tiempo desenfadado y grandilocuente.
La capacidad de la IA para producir textos fluidos y gramaticalmente correctos resulta irresistible, ya sea para redactar una frase ingeniosa en una solicitud de empleo o una ocurrencia para una aplicación de citas. Los textos generados por IA pueden engañar fácilmente a los lectores, especialmente cuando estos solo leen por encima. El resultado es una perfección prefabricada: textos que no pueden discutirse realmente porque carecen de un proceso deliberativo subyacente. Aunque parezcan plausibles a primera vista, un análisis más profundo revela que todo está ligeramente desajustado: el tono es plano, algunas palabras resultan extrañas, la estructura carece de lógica, faltan partes esenciales del argumento y abundan los errores fácticos. Incluso existen tutoriales para eliminar de la escritura las señales que delatan el uso de IA: evitar los guiones largos, los dos puntos o las ya sospechosas construcciones del tipo «No es X; es Y». Para la autora, ese es precisamente el problema fundamental de la escritura generada por IA: bajo una superficie pulida y convincente, a menudo no existe un razonamiento auténtico.
Un estudio realizado por investigadores de la Universidad de Stanford y la Universidad Carnegie Mellon encontró que los principales modelos de IA respaldan las ideas de sus usuarios un 49 % más que los seres humanos durante una conversación. Además, los participantes valoraban las respuestas más complacientes como de mayor calidad y afirmaban que esa actitud aumentaba la probabilidad de volver a utilizar la IA. Según la autora, este tipo de comunicación está empezando a rodearnos por todas partes. Su expansión parece inevitable. Incluso quienes no utilizan IA comenzarán a parecerse a ella en su manera de expresarse. Un estudio preliminar del Instituto Max Planck para el Desarrollo Humano encontró que, en conversaciones espontáneas como las de los pódcast, las personas ya muestran un aumento apreciable en el uso de palabras que ChatGPT genera con frecuencia, como delve («profundizar»), comprehend («comprender»), boast («presumir»), swift («rápido») o meticulous («meticuloso»).
Vara sostiene que muchas personas que utilizan habitualmente herramientas como ChatGPT desarrollan una especie de «instinto» para reconocer ciertos patrones característicos de la escritura generada por IA. No se trata de una prueba científica, sino de una percepción basada en la experiencia acumulada tras leer grandes cantidades de contenido producido por estos sistemas. Entre los indicios más frecuentes se encuentran una estructura excesivamente ordenada, transiciones demasiado fluidas entre párrafos y una tendencia a resumir constantemente las ideas ya expuestas.
También se cuestiona algunos de los supuestos signos distintivos que suelen mencionarse en internet. Elementos como el uso de determinados signos de puntuación, ciertas palabras de moda o expresiones recurrentes pueden aparecer igualmente en textos humanos. Por ello, la autora advierte contra la tentación de convertir cualquier rasgo estilístico en una prueba definitiva de autoría artificial. Lo relevante no es un único indicador, sino la acumulación simultánea de varios patrones.
Otro aspecto importante es la progresiva normalización de la escritura asistida por IA. Cada vez más autores emplean estas herramientas para revisar, reorganizar o mejorar borradores propios. Esta situación difumina la frontera entre texto humano y texto artificial, haciendo que la pregunta ya no sea únicamente quién escribió un texto, sino en qué medida intervino la inteligencia artificial en su elaboración.
El artículo también plantea una reflexión cultural más amplia. La proliferación de contenidos generados por IA está modificando nuestra percepción de la autenticidad y de la autoría. La sensación de que «algo suena a ChatGPT» se está convirtiendo en una nueva forma de alfabetización digital, basada más en la experiencia lectora que en herramientas tecnológicas. Sin embargo, la autora concluye que, conforme los modelos continúen evolucionando, incluso esa intuición humana podría perder eficacia, obligándonos a replantear cómo valoramos la originalidad y la creatividad en la era de la inteligencia artificial.

Cabrera Huaycochea, Daril. 2025. Declaración del uso de inteligencia artificial en la redacción de artículos académicos y tesis: Hacia un estándar ético y transparente para la producción científica en la era de los modelos de lenguaje de gran escala. ResearchGate. Consultado el 30 de mayo de 2026.
La expansión de los modelos de lenguaje de gran escala, como GPT, Claude o Gemini, ha transformado profundamente la producción académica, facilitando tareas como la redacción, la síntesis bibliográfica y la revisión textual. Sin embargo, este avance tecnológico no ha ido acompañado de normas homogéneas para declarar su utilización, generando importantes desafíos éticos relacionados con la transparencia, la autoría y la evaluación del mérito académico. El artículo de analiza esta problemática y propone un marco estandarizado para la declaración del uso de inteligencia artificial en artículos científicos y tesis.
El autor examina las políticas adoptadas por algunas de las principales instituciones y editoriales científicas internacionales, entre ellas arXiv, Elsevier, Nature y el Comité de Ética en Publicaciones (COPE). Aunque existen diferencias en los procedimientos, todas coinciden en dos principios fundamentales: las herramientas de inteligencia artificial no pueden ser consideradas autoras de trabajos académicos y cualquier utilización relevante debe ser declarada de manera explícita. Estas organizaciones subrayan que la responsabilidad sobre la exactitud, integridad y ética de los contenidos recae siempre en los autores humanos.
Uno de los principales aportes del trabajo es la formulación de una taxonomía de cuatro niveles de declaración. El Nivel 1 corresponde a trabajos elaborados sin IA generativa; el Nivel 2 contempla el uso de herramientas para corrección gramatical y estilística; el Nivel 3 incluye la generación de borradores, síntesis o análisis supervisados por los autores; y el Nivel 4 se refiere a aquellos casos en los que la IA participa de forma sustancial en la estructura argumentativa o conceptual del trabajo. El objetivo de esta clasificación no es juzgar moralmente los distintos usos de la tecnología, sino ofrecer un marco de transparencia que permita comprender el grado de intervención tecnológica en cada investigación.
El artículo también proporciona modelos prácticos de declaración para revistas científicas y tesis universitarias. Estas plantillas buscan facilitar la adopción de estándares comunes que permitan describir qué herramientas se utilizaron, en qué fases del proceso participaron y qué mecanismos de revisión humana se aplicaron posteriormente. Según el autor, la normalización de estas declaraciones contribuiría a reducir la ambigüedad normativa y fomentaría una cultura de integridad académica basada en la transparencia y la responsabilidad.
Se presta especial atención al contexto latinoamericano, donde identifica importantes desafíos relacionados con la desigualdad en el acceso a tecnologías avanzadas, la obsolescencia de los reglamentos universitarios y los sesgos lingüísticos de los modelos entrenados principalmente en inglés. Ante esta situación, propone que las universidades actualicen sus normativas y distingan claramente entre el uso declarado de la inteligencia artificial y el fraude académico por ocultamiento u omisión. La conclusión central del trabajo es que el verdadero debate no debe centrarse en prohibir o permitir la IA, sino en garantizar que su utilización sea transparente, verificable y compatible con los principios fundamentales de la integridad científica.

Bransford, Nathan. 2026. “A Literary A.I. Scandal Arrives: This Week in Books.” Nathan Bransford Blog, mayo de 2026. https://nathanbransford.com/blog/2026/05/a-literary-a-i-scandal-arrives-this-week-in-books
El artículo de Nathan Bransford aborda un caso que ha sacudido al mundo editorial: la sospecha de que un relato premiado en un certamen literario internacional podría haber sido generado total o parcialmente por inteligencia artificial. Este hecho ha encendido las alarmas en el sector cultural, no tanto por un caso aislado, sino por lo que representa como síntoma de una transformación más profunda en la literatura contemporánea.
Un relato escrito por una persona que se declara entusiasta de la IA, con todas las huellas típicas de escritura generada por IA, ganó un prestigioso premio de Granta. Esto, como era de esperar, está generando una gran cantidad de lamentos y preocupaciones en el mundo de la escritura. El texto se centra en la controversia en torno al relato The Serpent in the Grove, cuya calidad estilística y ciertos patrones narrativos han despertado dudas entre críticos y lectores. Elementos como repeticiones estructurales, metáforas excesivamente pulidas o una uniformidad estilística inusual han alimentado la hipótesis de una posible autoría algorítmica. El problema de fondo, subraya el artículo, es que no existen herramientas fiables para distinguir con certeza entre escritura humana y texto generado por IA, lo que deja a los concursos literarios en una posición extremadamente vulnerable.
Bransford insiste en que este caso expone una grieta estructural en el sistema de validación literaria: la confianza. Los jurados trabajan bajo la presunción de autenticidad del autor, pero esa base empieza a resquebrajarse en un contexto donde los modelos de lenguaje pueden producir narrativas sofisticadas en segundos. Incluso los sistemas de detección de IA ofrecen resultados contradictorios, lo que agrava la incertidumbre y abre la puerta a controversias difíciles de resolver.
En ausencia de herramientas fiables de detección de IA y de pruebas de culpabilidad, la autora considera que se tiene más que temer de las cacerías de brujas impulsadas por la IA y de las falsas acusaciones (que afectarán de manera desproporcionada a escritores idiosincráticos y ya marginados) que del uso de la IA por parte de los escritores, incluso cuando se utilice de forma integral.
El artículo también amplía la discusión hacia el impacto cultural más amplio de la inteligencia artificial en la escritura. La literatura, tradicionalmente considerada una de las formas más humanas de expresión creativa, se enfrenta ahora a una tecnología capaz de imitar estilos, voces y emociones con una precisión creciente. Esto genera una crisis de identidad en el mundo literario: ¿qué significa ser autor en la era de la IA?
Bransford sugiere que este episodio no será un caso aislado, sino el inicio de una serie de conflictos similares en premios, editoriales y plataformas de publicación. La frontera entre creación humana y producción algorítmica se vuelve cada vez más difusa, y con ella se tambalea uno de los pilares fundamentales de la cultura escrita: la autenticidad.

Peters, Jay. 2026. “AI Research Papers Are Getting Better, and It’s a Big Problem for Scientists.” The Verge, mayo de 2026. https://www.theverge.com/ai-artificial-intelligence/930522/ai-research-papers-slop-peer-review-problem
Se analiza una creciente preocupación dentro de la comunidad científica internacional: la expansión de artículos académicos generados parcial o totalmente mediante inteligencia artificial y el impacto que este fenómeno está teniendo sobre el sistema de revisión por pares. Lo que hace apenas dos años se identificaba fácilmente como “AI slop” —textos plagados de errores, referencias inventadas y frases incoherentes— ha evolucionado rápidamente hacia trabajos aparentemente sofisticados, bien redactados y difíciles de detectar incluso para expertos. Investigadores y editores científicos advierten que la automatización masiva de la escritura académica amenaza con saturar los mecanismos tradicionales de validación científica.
El reportaje explica que los modelos de lenguaje actuales son capaces de producir artículos completos en cuestión de minutos utilizando bases de datos públicas, gráficos automatizados y síntesis bibliográficas generadas algorítmicamente. Herramientas agentivas de IA permiten ya redactar hipótesis, construir marcos teóricos, producir análisis estadísticos e incluso responder automáticamente a comentarios de revisores. El problema no reside únicamente en la existencia de errores, sino en la enorme escala de producción. Según varios investigadores citados, la IA puede generar trabajos mucho más rápido de lo que los científicos humanos pueden leerlos o evaluarlos.
Uno de los aspectos más preocupantes es el deterioro progresivo del sistema de revisión por pares, históricamente considerado uno de los pilares de la credibilidad científica. Revisores y editores describen un entorno cada vez más difícil de gestionar debido al incremento de manuscritos redundantes, superficiales o engañosos. El artículo señala que muchos de estos textos utilizan lenguaje técnico convincente y estructuras académicas correctas, pero aportan escaso valor científico real. Esto obliga a los revisores a invertir más tiempo verificando datos, referencias y metodologías. La carga de trabajo se multiplica mientras la calidad media de las contribuciones disminuye.
La situación ha llevado a plataformas científicas a adoptar medidas drásticas. El repositorio científico arXiv anunció recientemente que prohibirá durante un año a los autores que publiquen trabajos con evidencia clara de contenido generado por IA no verificado, incluyendo referencias inventadas o comentarios residuales dejados por modelos lingüísticos. Además, quienes sean sancionados deberán demostrar posteriormente que sus investigaciones han sido aceptadas en publicaciones revisadas por pares antes de poder volver a subir artículos a la plataforma. Esta decisión refleja la preocupación institucional por preservar la confianza y la integridad académica en un contexto de creciente automatización textual.
El artículo también subraya que la crisis no puede entenderse únicamente como un problema tecnológico, sino como una consecuencia de las propias dinámicas estructurales del sistema académico contemporáneo. La presión por publicar, conseguir financiación y mantener productividad científica favorece comportamientos donde la cantidad de publicaciones se valora más que la calidad o la originalidad. La IA amplifica estas dinámicas al reducir drásticamente el coste y el tiempo necesarios para producir artículos. Algunos expertos comparan la situación con una “tragedia de los comunes”: cada investigador obtiene beneficios individuales al aumentar su productividad mediante IA, pero colectivamente el ecosistema científico se degrada debido a la saturación y pérdida de confianza.
Otro problema destacado es la aparición de errores sofisticados difíciles de detectar. Investigaciones recientes muestran que incluso conferencias científicas de alto prestigio han aceptado trabajos con referencias completamente inventadas generadas por IA. Estos fallos no siempre resultan evidentes porque los modelos producen citas plausibles, nombres verosímiles y estructuras metodológicas aparentemente coherentes. El riesgo no es solo la publicación de investigaciones deficientes, sino la contaminación progresiva del propio ecosistema científico con datos falsos, referencias inexistentes y conocimiento difícilmente verificable.
Paradójicamente, mientras algunos sectores intentan frenar el “AI slop”, otros comienzan a utilizar inteligencia artificial para aliviar precisamente la crisis de revisión. Algunos proyectos experimentales, como los desarrollados en conferencias de inteligencia artificial, ya emplean sistemas automatizados capaces de revisar miles de artículos en menos de un día. Sus defensores argumentan que la IA puede detectar errores técnicos y debilidades metodológicas con gran rapidez, aunque críticos advierten de que esto puede generar revisiones homogéneas, sesgadas y fácilmente manipulables mediante ajustes estilísticos. El debate gira así en torno a una paradoja creciente: utilizar IA para controlar los problemas creados por la propia IA.
Las reacciones en comunidades académicas y tecnológicas reflejan una mezcla de alarma, resignación y escepticismo. En foros como Reddit, numerosos investigadores consideran que el problema no se limita a los modelos lingüísticos, sino a un sistema científico que ya estaba sobrecargado antes de la llegada de la IA generativa. Algunos usuarios sostienen que el verdadero riesgo es que el volumen de textos automatizados haga imposible distinguir entre investigación genuina y producción mecánica. Otros creen que la crisis obligará a replantear prácticas fundamentales de evaluación científica, desde la verificación de referencias hasta la exigencia de compartir datos experimentales completos.
La inteligencia artificial no solo está transformando la manera de escribir artículos científicos, sino que está alterando profundamente los mecanismos de validación del conocimiento académico. La revisión por pares, concebida históricamente como filtro de calidad y garantía de rigor, enfrenta ahora un escenario donde la producción automatizada amenaza con superar la capacidad humana de evaluación. El desafío ya no consiste únicamente en detectar textos generados por IA, sino en redefinir qué significa producir conocimiento fiable en una época dominada por la automatización intelectual.
Cheng, Adam, Aaron Calhoun y Gabriel Reedy. “Artificial Intelligence-Assisted Academic Writing: Recommendations for Ethical Use.” Advances in Simulation 10, n.º 1 (2025): 22. https://doi.org/10.1186/s41077-025-00350-6
Se analiza de manera profunda el impacto de las herramientas de inteligencia artificial generativa —especialmente los grandes modelos de lenguaje como ChatGPT— en la escritura académica y científica. Los autores, Adam Cheng, Aaron Calhoun y Gabriel Reedy, abordan una cuestión central en el ecosistema universitario contemporáneo: cómo aprovechar las capacidades de la IA sin comprometer la integridad académica, la calidad científica ni la autoría intelectual.
El texto parte de una constatación evidente: desde la aparición pública de ChatGPT en 2022, el uso de herramientas de IA generativa se ha extendido rápidamente entre investigadores, estudiantes y docentes. Estas aplicaciones permiten resumir información, redactar borradores, corregir estilo, traducir textos, generar ideas e incluso estructurar artículos científicos completos. Sin embargo, los autores advierten que esta expansión se ha producido más rápido que la creación de marcos éticos y normativos claros. La comunidad académica se encuentra así ante un escenario ambiguo, en el que conviven enormes posibilidades de mejora de la productividad intelectual con riesgos serios para la credibilidad científica.
Uno de los aspectos más relevantes del artículo es la identificación de los principales peligros asociados al uso indiscriminado de la IA en la escritura académica. Los autores subrayan que los modelos generativos pueden producir “alucinaciones”, es decir, afirmaciones aparentemente verosímiles pero falsas, además de referencias bibliográficas inventadas o inexactas. Este fenómeno resulta especialmente problemático en contextos científicos, donde la verificabilidad y el rigor documental constituyen pilares fundamentales. También se aborda el riesgo de plagio involuntario, la reproducción de sesgos presentes en los datos de entrenamiento y la tendencia a generar textos estilísticamente homogéneos que pueden empobrecer la diversidad discursiva y crítica de la producción científica.
El artículo dedica una parte importante a examinar cómo las editoriales académicas y las revistas científicas están reaccionando frente a la irrupción de la IA generativa. Los autores señalan que muchas publicaciones científicas ya exigen transparencia explícita sobre el uso de herramientas de IA en la redacción de manuscritos. Algunas revistas prohíben considerar a la IA como autora de un trabajo, argumentando que carece de responsabilidad ética y legal sobre el contenido producido. Otras instituciones, en cambio, aceptan el uso de IA como herramienta auxiliar, siempre que exista supervisión humana y se informe claramente de su utilización. Este debate refleja una transformación profunda de los criterios tradicionales de autoría, originalidad y responsabilidad intelectual en la ciencia contemporánea.
Los autores no adoptan una postura tecnófoba. Por el contrario, reconocen que la IA puede aportar beneficios reales cuando se utiliza de manera crítica y controlada. El artículo describe tres grandes categorías de uso éticamente aceptable de la inteligencia artificial en la escritura académica. La primera es el apoyo lingüístico y editorial: mejorar gramática, claridad, estilo o traducción de textos, especialmente útil para investigadores que escriben en una lengua distinta de la materna. La segunda categoría incluye la organización y síntesis de información, como la generación de esquemas, resúmenes preliminares o estructuras de artículos. Finalmente, la tercera categoría contempla el apoyo creativo y cognitivo, por ejemplo en la generación de ideas iniciales o en la reformulación de conceptos complejos. En todos los casos, los autores insisten en que la supervisión humana es imprescindible y que la IA nunca debe sustituir el juicio crítico del investigador.
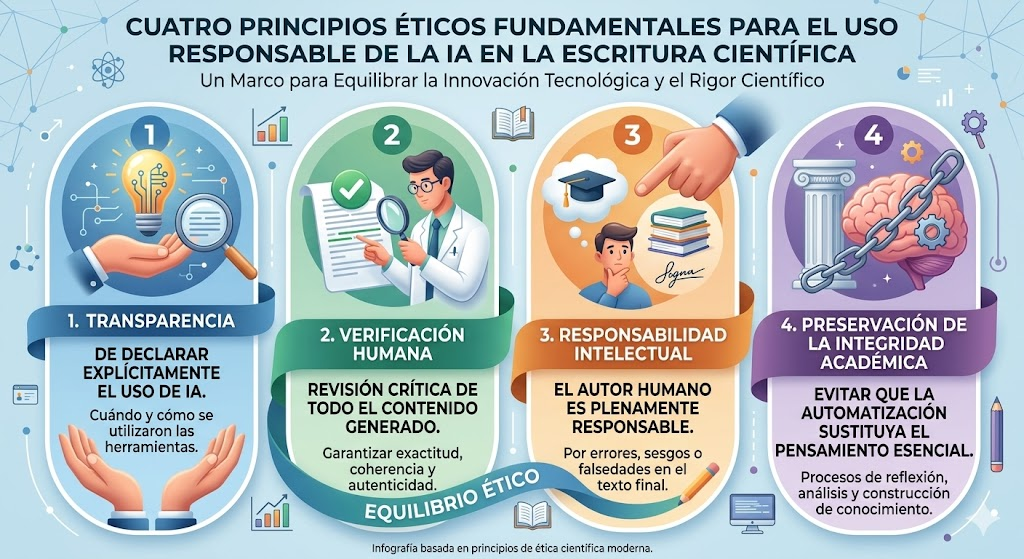
Uno de los aportes más importantes del trabajo es la formulación de cuatro principios éticos fundamentales para orientar el uso responsable de la IA en la escritura científica.
El artículo también plantea una reflexión más profunda sobre la naturaleza misma de la escritura académica. Los autores advierten que escribir no es simplemente producir texto, sino un proceso intelectual de elaboración de pensamiento, argumentación y aprendizaje. Si los investigadores delegan excesivamente estas funciones en sistemas automáticos, existe el riesgo de una “descapacitación académica”, es decir, una pérdida progresiva de habilidades críticas, analíticas y argumentativas. Esta preocupación conecta con debates actuales sobre alfabetización en IA, pensamiento crítico y el papel de las universidades en una sociedad crecientemente automatizada.
Otro aspecto relevante es que el artículo se centra especialmente en el ámbito de la simulación sanitaria y la investigación en salud, aunque sus conclusiones son extrapolables a prácticamente cualquier disciplina académica. Los autores consideran que el entorno científico necesita desarrollar urgentemente políticas institucionales claras, programas de formación en uso ético de IA y nuevas competencias de alfabetización digital que permitan a estudiantes e investigadores comprender tanto el potencial como las limitaciones de estas tecnologías. La IA deja de ser vista únicamente como una herramienta técnica y pasa a convertirse en un desafío cultural, educativo y epistemológico.
En conjunto, el trabajo constituye una de las aportaciones más relevantes y equilibradas sobre inteligencia artificial y escritura académica publicadas recientemente. Frente a posiciones extremas —ya sea de entusiasmo acrítico o de rechazo absoluto—, el artículo propone una vía intermedia basada en el uso responsable, transparente y supervisado de la IA. Los autores defienden que estas tecnologías pueden enriquecer el trabajo académico siempre que permanezcan subordinadas a la capacidad humana de análisis, interpretación y juicio ético. En definitiva, el texto plantea que el verdadero reto no es decidir si la IA debe utilizarse o no en la investigación científica, sino aprender a integrarla de forma que fortalezca, y no debilite, la integridad intelectual y la calidad del conocimiento producido.

Naddaf, Miryam. “Surge in Fake Citations Uncovered by Audit of 2.5 Million Biomedical-Science Papers.” Nature, 8 de mayo de 2026. https://doi.org/10.1038/d41586-026-00748-w.
El artículo publicado en Nature por la periodista científica Miryam Naddaf analiza uno de los problemas más inquietantes surgidos en la comunicación científica contemporánea: el rápido aumento de citas bibliográficas falsas o inventadas en artículos académicos biomédicos. El trabajo se basa en una auditoría masiva de 2,5 millones de artículos científicos y cerca de 97 millones de referencias bibliográficas, cuyos resultados muestran que el fenómeno se ha disparado desde 2023, coincidiendo con la expansión del uso de herramientas de inteligencia artificial generativa.
La investigación detectó casi 3.000 artículos biomédicos que contenían referencias imposibles de rastrear en bases de datos académicas reconocidas. Estas citas falsas incluían títulos inexistentes, DOI erróneos o referencias atribuidas a publicaciones que nunca llegaron a existir. Según el estudio, 2.564 artículos presentaban una o dos referencias inventadas, mientras que 246 trabajos acumulaban tres o más citas falsas, lo que revela que el problema ya no es anecdótico, sino estructural.
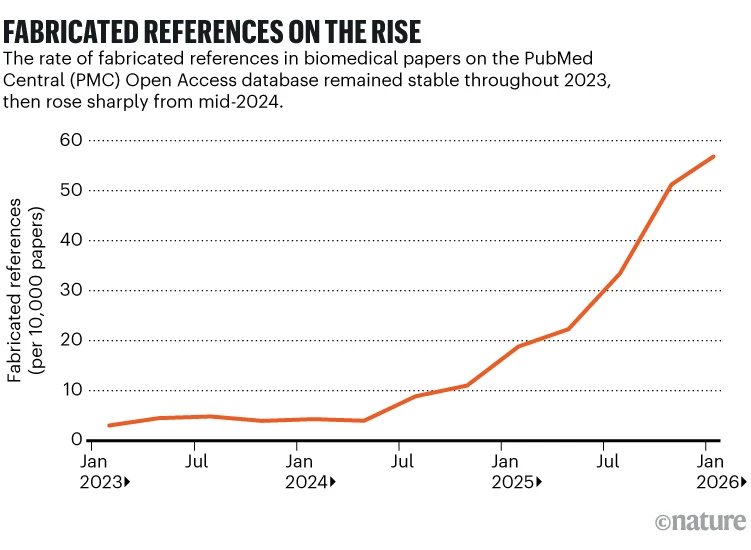
Uno de los aspectos más alarmantes es la velocidad con la que el fenómeno está creciendo. El análisis mostró que en 2025 había doce veces más artículos con referencias fabricadas que en 2023. Los investigadores consideran que este incremento coincide claramente con la generalización de modelos de lenguaje generativo capaces de producir textos académicos convincentes, pero también propensos a “alucinar” información bibliográfica. Estas herramientas pueden inventar títulos, autores o revistas que parecen plausibles, dificultando enormemente la detección manual de errores.
La metodología utilizada para detectar las referencias falsas combinó inteligencia artificial y verificación documental automatizada. Los investigadores compararon títulos citados con los DOI y PubMed ID asociados, además de contrastar cada referencia con grandes bases bibliográficas como PubMed, Crossref, OpenAlex y Google Scholar. Cuando una referencia no aparecía en ninguno de esos sistemas, era clasificada como potencialmente fabricada. Este procedimiento permitió construir uno de los mayores estudios de integridad bibliográfica realizados hasta la fecha.
El artículo subraya que las consecuencias del problema van mucho más allá de simples errores de citación. Las referencias falsas contaminan la literatura científica, dificultan la verificación del conocimiento y erosionan la confianza en el sistema de publicación académica. En disciplinas biomédicas, donde los artículos pueden influir en decisiones clínicas, tratamientos o políticas sanitarias, una bibliografía inventada puede tener repercusiones especialmente graves.
Además, el texto pone de manifiesto las limitaciones actuales del sistema de revisión por pares. Los revisores rara vez tienen tiempo suficiente para comprobar individualmente cada referencia citada en un manuscrito. Como consecuencia, muchos artículos con bibliografía falsa logran superar los controles editoriales y llegar a la publicación. Los autores del estudio consideran urgente incorporar sistemas automáticos de verificación bibliográfica antes incluso de iniciar la revisión por pares.
Otro aspecto destacado es que el problema no siempre implica fraude deliberado. Algunos investigadores utilizan modelos de IA para generar borradores o ayudar en la redacción y pueden no detectar que determinadas referencias han sido inventadas automáticamente por el sistema. Esto crea una nueva zona gris en la ética científica contemporánea: artículos firmados por autores humanos, pero parcialmente construidos mediante herramientas capaces de producir información inexistente con apariencia académica legítima.
El artículo también recoge la preocupación creciente de especialistas en integridad científica, quienes advierten que las citas falsas podrían ser solo la parte visible de un problema más amplio relacionado con la automatización de la escritura académica. Algunos expertos hablan ya de una “contaminación” progresiva de la literatura científica y alertan de que el prestigio de revistas y sistemas de evaluación podría verse seriamente afectado si no se desarrollan mecanismos de control más rigurosos.
El reportaje de Nature conecta este fenómeno con la transformación más profunda del ecosistema científico en la era de la inteligencia artificial generativa. La facilidad para producir textos complejos, revisiones bibliográficas y manuscritos completos está alterando las dinámicas tradicionales de autoría, revisión y validación del conocimiento. El desafío ya no consiste únicamente en detectar errores, sino en redefinir cómo garantizar la fiabilidad del conocimiento científico en un contexto donde las máquinas pueden producir contenido académico aparentemente verosímil a gran escala.

Dahl, Josh. “Guest Post — Is Growth Always Good News? 2026 Article Submission Surges.” The Scholarly Kitchen, 13 de mayo de 2026. The Scholarly Kitchen
Se analiza el extraordinario aumento de manuscritos enviados a revistas científicas durante el primer trimestre de 2026 y plantea una cuestión fundamental para el ecosistema académico: si este crecimiento representa una expansión saludable de la investigación mundial o, por el contrario, una señal de deterioro estructural provocada por el uso masivo de herramientas de inteligencia artificial generativa.
El texto parte de un dato especialmente significativo: la plataforma ScholarOne Manuscripts registró un incremento del 33 % en los envíos de artículos respecto al mismo periodo de 2025. Lo más preocupante no es únicamente el volumen absoluto, sino la aceleración del crecimiento, ya que el aumento interanual prácticamente se duplicó respecto al año anterior, pasando del 17 % al 33 %. Dahl interpreta este fenómeno como un indicador de tensión extrema en el sistema editorial científico, especialmente en aquellas revistas con menos recursos para detectar trabajos problemáticos o de baja calidad.
Uno de los aspectos centrales del análisis es la relación entre el auge de la inteligencia artificial y el incremento de manuscritos enviados. El autor sostiene que los datos por sí solos no permiten demostrar que el crecimiento proceda directamente de textos generados mediante IA, pero sí revelan patrones compatibles con ello. Según Dahl, muchas revistas están recibiendo trabajos elaborados parcialmente con herramientas generativas, lo que multiplica la producción textual y reduce las barreras técnicas para redactar artículos académicos. Este fenómeno estaría alterando profundamente la economía de la publicación científica y la dinámica tradicional de la autoría académica.
El artículo destaca además un incremento notable de los “desk rejections” o rechazos editoriales preliminares. Entre 2022 y 2025 estos rechazos crecieron un 72 %, muy por encima del crecimiento total de decisiones editoriales. Esto significa que los equipos editoriales están dedicando cada vez más tiempo a filtrar trabajos que consideran insuficientes, irrelevantes o problemáticos antes incluso de enviarlos a revisión por pares. Para Dahl, este dato evidencia que el sistema de control de calidad está sometido a una presión creciente y que la carga de trabajo editorial se está desplazando hacia fases previas del proceso de evaluación.
Otro elemento especialmente relevante es la reflexión sobre el “contrato social” de la revisión por pares. El autor sostiene que el problema principal no es tecnológico, sino epistemológico y ético. Tradicionalmente, el sistema científico se basaba en la idea de que el investigador era plenamente responsable del contenido que enviaba: conocía las fuentes, defendía los argumentos y comprendía la metodología empleada. Sin embargo, con la IA generativa esa relación entre autor y texto se vuelve difusa. Dahl plantea que actualmente no existe un consenso claro sobre qué nivel de asistencia artificial resulta aceptable y cuál compromete la integridad académica.
El texto utiliza como ejemplo el problema de las referencias bibliográficas inventadas por modelos de lenguaje. Un investigador puede generar un borrador mediante IA y no detectar que algunas citas son ficticias. En este caso, el autor no falsifica deliberadamente la información, pero termina enviando un manuscrito con errores graves. Dahl argumenta que las declaraciones tradicionales de autoría y responsabilidad no están preparadas para afrontar este nuevo escenario, donde los límites entre asistencia técnica y creación intelectual son cada vez más ambiguos.
La reflexión conecta con un debate más amplio sobre la sostenibilidad de la revisión por pares en un contexto de crecimiento acelerado de publicaciones. El artículo se relaciona con otras discusiones recientes de The Scholarly Kitchen sobre la saturación editorial y la capacidad del sistema científico para absorber el volumen actual de investigación. En textos complementarios publicados en 2026 se insiste en que la revisión por pares atraviesa una crisis de capacidad, con revisores agotados, plazos más cortos y expectativas cada vez más difíciles de cumplir.
Asimismo, Dahl sugiere que el fenómeno no puede entenderse únicamente desde la tecnología. El crecimiento de manuscritos también refleja las presiones estructurales del modelo académico contemporáneo: la lógica del “publish or perish”, la evaluación basada en métricas, la expansión global de la investigación y la creciente competencia por financiación y reconocimiento profesional. En este contexto, la IA actúa como acelerador de dinámicas ya existentes más que como causa exclusiva del problema.
En conjunto, el artículo ofrece una mirada crítica y muy actual sobre la transformación del ecosistema editorial científico. Más que condenar la inteligencia artificial, plantea la necesidad urgente de redefinir las normas de autoría, responsabilidad y validación del conocimiento académico. Dahl concluye implícitamente que el desafío fundamental no consiste solo en detectar textos generados por IA, sino en reconstruir la confianza y los mecanismos de legitimación sobre los que históricamente se ha sostenido la comunicación científica.

Mashable. “How to Defend Yourself Against AI Cheating Accusations.” Mashable, 2026. https://mashable.com/article/how-to-defend-yourself-ai-cheating-accusations
El artículo aborda un problema creciente en el ámbito educativo: las acusaciones de uso indebido de inteligencia artificial en trabajos académicos, muchas veces basadas en herramientas de detección poco fiables. Señala que estos sistemas pueden generar falsos positivos, lo que implica que estudiantes que no han utilizado IA pueden ser injustamente señalados. En este contexto, la defensa no debe centrarse únicamente en negar la acusación, sino en aportar pruebas concretas del proceso de trabajo y de la autoría real del contenido.
El artículo analiza en profundidad un fenómeno cada vez más frecuente en entornos educativos: las acusaciones de plagio o fraude académico basadas en el supuesto uso de herramientas de inteligencia artificial generativa. A medida que tecnologías como los chatbots se popularizan, muchas instituciones han comenzado a utilizar detectores automáticos para identificar textos presuntamente generados por IA. Sin embargo, el texto subraya que estas herramientas presentan importantes limitaciones técnicas y metodológicas, ya que no pueden determinar con certeza absoluta el origen de un contenido. Esto genera un escenario problemático en el que estudiantes pueden ser acusados injustamente a partir de resultados probabilísticos o poco transparentes, lo que plantea dudas sobre la equidad y la fiabilidad de estos sistemas de evaluación.
Ante esta situación, el artículo propone una serie de estrategias para que los estudiantes puedan defenderse de manera eficaz. La más importante es demostrar el proceso de creación del trabajo. Frente a la sospecha de generación automática, la mejor evidencia es la trazabilidad del esfuerzo intelectual: borradores, esquemas previos, notas manuscritas, versiones intermedias y, especialmente, el historial de edición en herramientas digitales. Plataformas como Google Docs o Microsoft Word permiten visualizar cómo evoluciona un texto a lo largo del tiempo, lo que constituye una prueba sólida de autoría humana. Este énfasis en el proceso responde a un cambio de paradigma: en un entorno donde el producto final puede ser imitado por máquinas, lo que adquiere valor es la construcción progresiva del conocimiento.
El artículo también destaca la importancia de la competencia comunicativa del estudiante como elemento de defensa. Poder explicar con claridad las ideas desarrolladas, justificar las decisiones tomadas durante la redacción y responder a preguntas sobre el contenido son indicios clave de que el trabajo es propio. En este sentido, la comprensión profunda del texto se convierte en una forma de evidencia indirecta que complementa las pruebas documentales. La defensa, por tanto, no es únicamente técnica, sino también argumentativa y cognitiva.
Otro aspecto fundamental es la actitud ante la acusación. El artículo recomienda evitar respuestas impulsivas o confrontativas y, en su lugar, adoptar una postura serena y estratégica. Es esencial solicitar detalles concretos sobre la acusación: qué herramienta se ha utilizado, qué indicadores han llevado a esa conclusión y cuál es el margen de error del sistema. Este enfoque permite cuestionar de manera fundamentada la validez de las pruebas, especialmente teniendo en cuenta que muchos detectores de IA han sido criticados por su opacidad y su falta de rigor científico. En algunos casos, incluso expertos han señalado que estos sistemas pueden discriminar ciertos estilos de escritura o perfiles lingüísticos, lo que añade una dimensión ética al problema.
El texto también sitúa este conflicto en un contexto más amplio de transformación educativa. La irrupción de la inteligencia artificial está obligando a replantear los métodos de evaluación tradicionales, basados en productos finales fácilmente replicables por máquinas. Como respuesta, se propone un mayor énfasis en evaluaciones continuas, trabajos supervisados, defensas orales y actividades que requieran reflexión personal. En este nuevo escenario, la capacidad de documentar el proceso de aprendizaje y de demostrar pensamiento crítico se convierte en una competencia central.
Finalmente, el artículo advierte de la necesidad de que las instituciones educativas desarrollen políticas más claras, justas y transparentes en relación con el uso de la IA. Esto incluye no solo definir qué se considera un uso aceptable, sino también garantizar procedimientos de apelación justos en caso de acusaciones. En definitiva, el problema no se limita a la conducta de los estudiantes, sino que refleja una transición más amplia en la cultura académica, donde la tecnología desafía los criterios tradicionales de autoría, originalidad y evaluación del conocimiento.

Dahl, Roald. “The Great Automatic Grammatizator.” 1954. PDF. Accedido en 2026. https://gwern.net/doc/fiction/science-fiction/1953-dahl-thegreatautomaticgrammatizator.pdf
Relato de Roald Dahl en el que un ingeniero frustrado diseña una máquina capaz de generar literatura mediante reglas gramaticales y combinatorias. El invento se industrializa y permite producir textos en masa, sustituyendo progresivamente a los escritores humanos en el mercado editorial. La historia satiriza la deshumanización de la creatividad y anticipa debates actuales sobre la automatización de la escritura y la inteligencia artificial.
Adolph Knipe, un joven ingeniero que trabaja en una empresa tecnológica, pero que en realidad esconde una ambición frustrada: quiere ser escritor. Sin embargo, su experiencia con el rechazo editorial y su formación técnica le llevan a una idea radicalmente distinta de la literatura: en lugar de ver la escritura como un acto creativo humano, la concibe como un proceso mecánico basado en reglas combinatorias del lenguaje.
A partir de esta intuición, Knipe desarrolla la idea de construir una máquina capaz de generar textos automáticamente. Su jefe, Bohlen, inicialmente desconfiado, termina aceptando financiar el proyecto al percibir su enorme potencial económico. La lógica es clara: si la máquina puede producir relatos aceptables de forma continua y barata, podría revolucionar el mercado literario.
La máquina, denominada el “Gran Gramaticador Automático”, se basa en un sistema de reglas gramaticales y combinaciones de palabras que permite generar historias de manera sistemática. Aunque los textos resultantes no son de gran calidad literaria, sí son coherentes, comprensibles y, sobre todo, infinitamente reproducibles. Esto convierte al sistema en una herramienta extremadamente rentable.
El éxito del invento lleva a Knipe y Bohlen a dar un paso más ambicioso: intervenir directamente en el mundo editorial. Su estrategia consiste en convencer a escritores reales —incluidos autores reconocidos— para que firmen contratos en los que ceden el uso de su nombre a cambio de una compensación económica. A partir de ese momento, la máquina escribe los textos que se publican bajo esos nombres. El prestigio del autor humano se mantiene como marca, pero el contenido es producido por el sistema automatizado.
Este modelo de negocio se expande rápidamente. Muchos escritores aceptan, seducidos por la estabilidad económica y la ausencia de esfuerzo creativo. Poco a poco, la figura del autor individual empieza a diluirse, sustituida por una producción industrial de literatura firmada con nombres humanos pero generada por la máquina.
A medida que el sistema se consolida, la industria editorial se transforma por completo. La abundancia de textos producidos por el gramaticador hace que los libros se vuelvan un producto barato y masivo. La calidad literaria deja de ser un criterio central; lo importante es la cantidad, la rentabilidad y la eficiencia del sistema automatizado.
Sin embargo, esta expansión tiene un efecto colateral inquietante: los escritores que se niegan a participar en el sistema quedan progresivamente marginados. Sus obras ya no pueden competir en un mercado inundado por producción automática. El relato muestra así un proceso de desplazamiento silencioso de la creatividad humana por la lógica industrial de la máquina.
El desenlace adquiere un tono oscuro e irónico. El mundo literario queda dominado por el gramaticador, mientras la escritura humana sobrevive solo de forma residual o marginal. La autoría deja de ser un acto de creación individual para convertirse en una etiqueta comercial aplicada a productos generados automáticamente.
