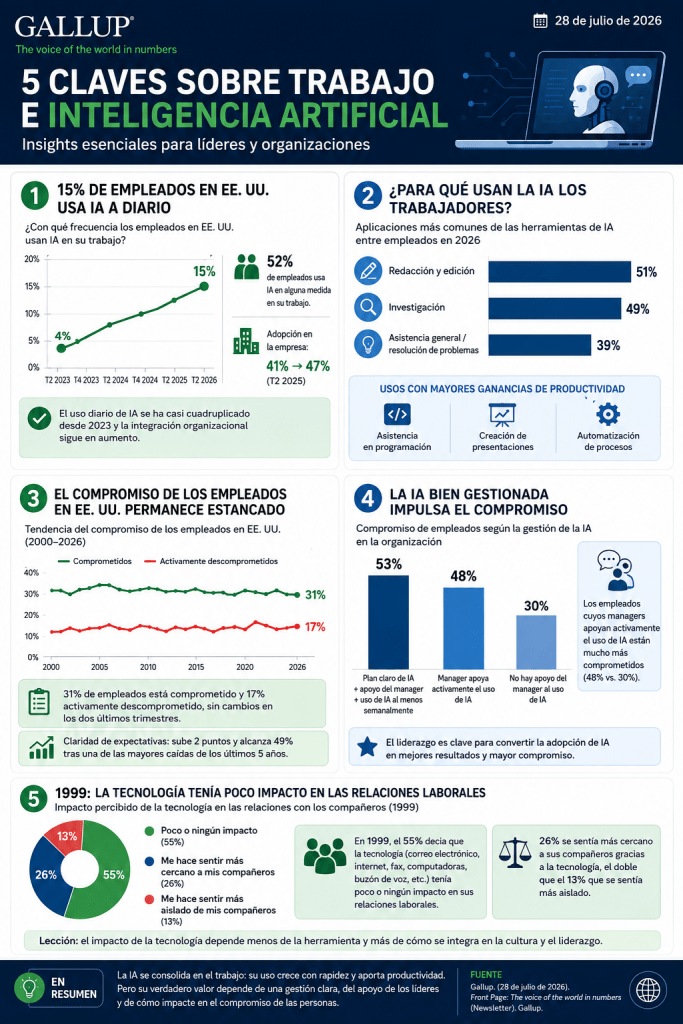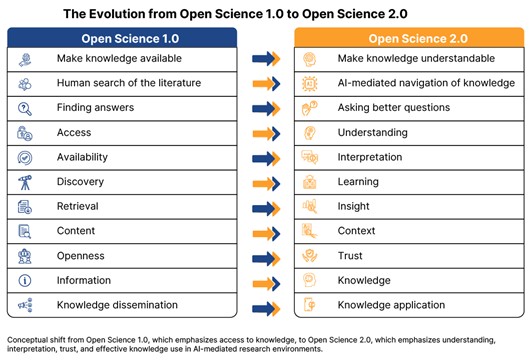
Ghildiyal, Ashutosh. Open Science 2.0: Building Understanding in an AI-Mediated World. The Scholarly Kitchen, 14 de julio de 2026. Disponible en: The Scholarly Kitchen – Open Science 2.0: Building Understanding in an AI-Mediated World
El artículo plantea que la ciencia abierta se encuentra en un punto de inflexión provocado por la rápida incorporación de la inteligencia artificial en los procesos de búsqueda, análisis e interpretación del conocimiento científico. Durante las dos últimas décadas, el movimiento de Ciencia Abierta ha centrado sus esfuerzos en eliminar las barreras de acceso mediante políticas de acceso abierto, repositorios institucionales, datos abiertos y licencias que facilitan la reutilización de la información. Sin embargo, el autor sostiene que este paradigma resulta insuficiente en un escenario donde los investigadores, estudiantes y ciudadanos ya no acceden directamente a los artículos científicos, sino que interactúan con asistentes inteligentes capaces de sintetizar, reinterpretar y responder preguntas a partir de millones de documentos. En consecuencia, la prioridad deja de ser únicamente garantizar el acceso al conocimiento para asegurar también que dicho conocimiento pueda ser comprendido, contextualizado e interpretado correctamente.
La propuesta de «Open Science 2.0» representa una evolución conceptual de la ciencia abierta tradicional. En este nuevo enfoque, la apertura continúa siendo un requisito imprescindible, pero ya no constituye el objetivo final. El verdadero desafío consiste en construir un ecosistema científico donde la información sea inteligible tanto para las personas como para las inteligencias artificiales, preservando al mismo tiempo el significado, la procedencia, la calidad y la confianza. Según el autor, la IA está modificando profundamente la forma en que se descubre y consume la investigación científica: los usuarios consultan modelos conversacionales que sintetizan cientos de artículos en segundos, lo que implica que gran parte del proceso de lectura crítica puede quedar oculto tras respuestas aparentemente simples. Esto obliga a replantear las infraestructuras de comunicación científica para incorporar mecanismos que permitan verificar las fuentes, comprender el contexto y mantener la trazabilidad de la información utilizada por los sistemas inteligentes.
Otro aspecto fundamental del artículo es la importancia creciente de la confianza. El autor advierte que, en un entorno mediado por IA, la calidad científica ya no dependerá únicamente de que un artículo haya superado la revisión por pares, sino también de la capacidad de demostrar el origen de los datos, la transparencia de los modelos empleados, la integridad de las evidencias y la posibilidad de rastrear cómo una inteligencia artificial ha construido una determinada respuesta. La confianza pasa a convertirse en un elemento estructural de la comunicación académica, exigiendo nuevos estándares de metadatos, sistemas de atribución más completos y mecanismos que permitan identificar con claridad las fuentes originales utilizadas por las plataformas de IA.
El texto también subraya que la comunicación científica debe abandonar un modelo centrado exclusivamente en la publicación para orientarse hacia la construcción de comprensión. Publicar artículos de libre acceso sigue siendo importante, pero resulta insuficiente si esos contenidos no pueden ser interpretados correctamente por comunidades científicas, responsables políticos, periodistas, educadores o ciudadanos. En este contexto, adquieren especial relevancia las explicaciones accesibles, los resúmenes estructurados, los datos enriquecidos semánticamente, las visualizaciones, las ontologías y otras herramientas que permitan convertir la información científica en conocimiento útil y reutilizable. La IA puede facilitar este proceso, pero solo si dispone de contenidos bien estructurados y acompañados de suficiente contexto para evitar interpretaciones erróneas o simplificaciones excesivas.
El artículo concluye que la próxima etapa de la ciencia abierta exige una colaboración mucho más estrecha entre investigadores, bibliotecas, universidades, editores científicos, desarrolladores de inteligencia artificial y responsables de políticas públicas. La misión ya no consiste únicamente en liberar artículos del pago por suscripción, sino en diseñar un ecosistema donde el conocimiento conserve su significado, pueda verificarse, genere confianza y sea comprensible tanto para las personas como para las máquinas. En esta visión, la Ciencia Abierta 2.0 no sustituye los principios tradicionales de apertura, sino que los amplía incorporando dimensiones como la interpretación, el aprendizaje, la comunicación efectiva y la gobernanza de la información en una realidad donde la inteligencia artificial se ha convertido en el principal intermediario entre la producción científica y sus usuarios.