Tay, Aaron. AI Search Is Rebundling Everything Libraries Know About Discovery: Ten established traditions, an emerging eleventh, and why libraries need to have a more holistic view of discovery. Aaron Tay’s Musings about Librarianship (Substack), 18 de julio de 2026. https://aarontay.substack.com/p/eleven-ways-of-looking-at-academic
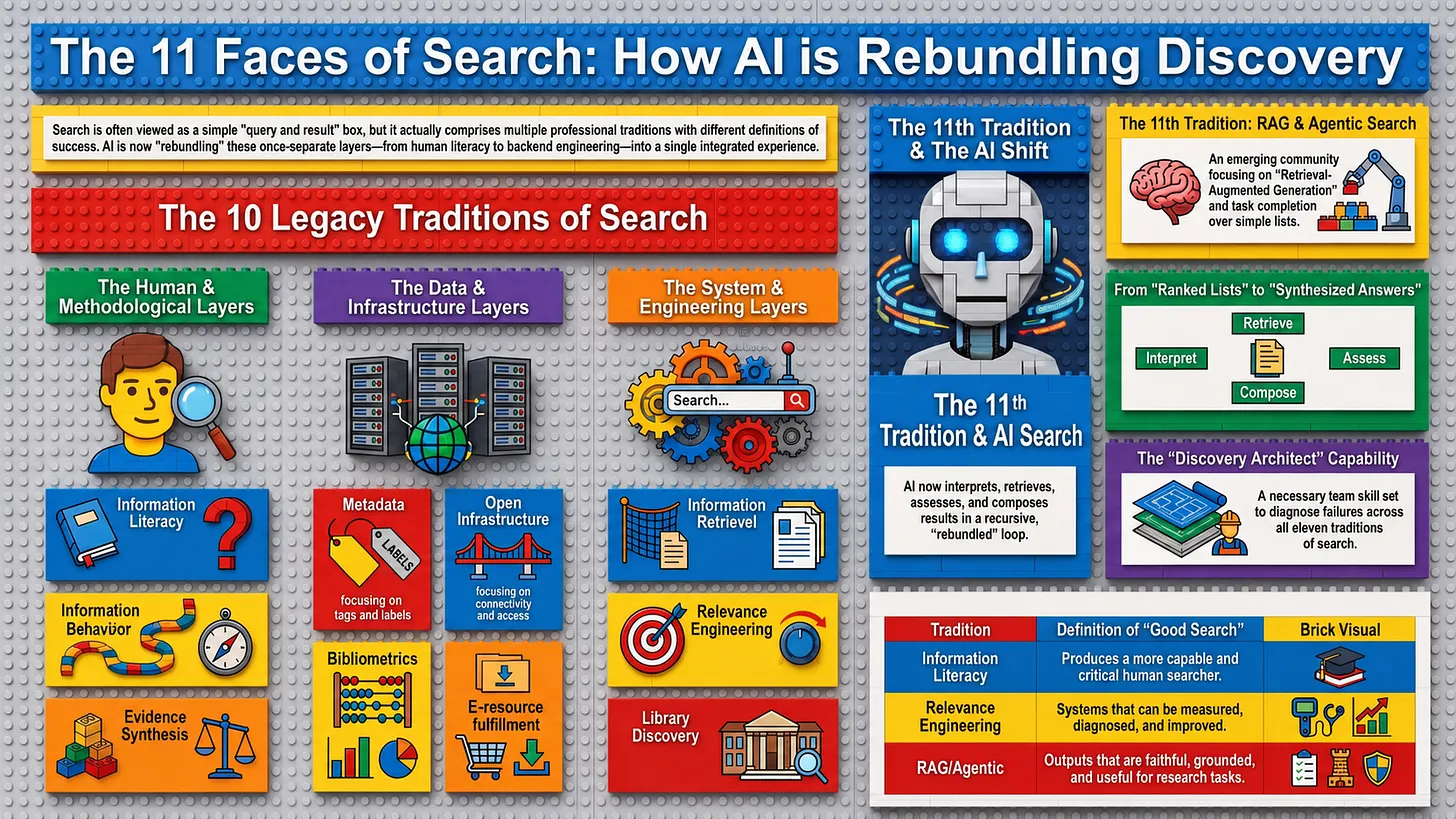
Aaron Tay plantea que la búsqueda académica nunca ha sido una actividad única y homogénea, sino un conjunto de perspectivas desarrolladas por comunidades profesionales y de investigación diferentes. Inspirándose en el conocido ensayo de Lorcan Dempsey Thirteen Ways of Looking at Libraries, Discovery, and the Catalog, el autor propone que la búsqueda científica puede entenderse desde diez tradiciones consolidadas y una undécima emergente.
Cada una de ellas interpreta el mismo proceso de búsqueda desde objetivos distintos: unas priorizan la alfabetización informacional, otras el comportamiento de los usuarios, la recuperación de información, la bibliometría, la infraestructura científica, la organización del conocimiento o la ingeniería de relevancia. El problema, sostiene Tay, no es la ausencia de conocimiento sobre la búsqueda académica, sino la fragmentación de ese conocimiento entre comunidades que apenas comparten lenguaje, métodos de evaluación o marcos conceptuales.
El autor describe cómo cada tradición aporta una pieza esencial del ecosistema de descubrimiento. Los especialistas en alfabetización informacional consideran que una buena búsqueda es aquella que forma usuarios críticos capaces de evaluar fuentes y detectar sesgos, especialmente en un contexto donde las respuestas generadas por IA pueden parecer convincentes sin ser necesariamente fiables. Los investigadores del comportamiento informacional, por su parte, entienden la búsqueda como un proceso dinámico en el que las necesidades del usuario evolucionan mientras explora información, reformula consultas y redefine sus objetivos. Los expertos en revisiones sistemáticas y síntesis de evidencia ponen el énfasis en la exhaustividad, la transparencia y la reproducibilidad de las estrategias de búsqueda, considerando que estas forman parte del propio método científico y deben ser documentadas y auditadas rigurosamente.
Uno de los argumentos centrales del artículo es que la irrupción de la inteligencia artificial está desdibujando las fronteras tradicionales entre estas disciplinas. En los sistemas clásicos existían capas relativamente independientes: los metadatos, la recuperación de documentos, el ordenamiento de resultados, el acceso al texto completo o la evaluación crítica podían estudiarse por separado. Los sistemas de búsqueda basados en IA, en cambio, integran continuamente interpretación de preguntas, recuperación de información, selección de evidencias, generación de respuestas y razonamiento automatizado. La IA no elimina estas capas, sino que las reorganiza en arquitecturas mucho más complejas donde interactúan de forma constante. Como consecuencia, comprender cómo funciona realmente un sistema de búsqueda requiere conocimientos que hasta ahora estaban distribuidos entre comunidades muy distintas.
Ante esta nueva realidad, Tay propone el surgimiento de una nueva capacidad organizativa que denomina «discovery architect» o arquitecto del descubrimiento, aunque insiste en que no debe entenderse necesariamente como un nuevo puesto de trabajo, sino como una competencia colectiva que deberían desarrollar las bibliotecas académicas. Este equipo tendría una visión transversal del ecosistema completo de búsqueda científica, capaz de comprender metadatos, infraestructuras abiertas, algoritmos de recuperación, modelos de IA, sistemas de acceso, grafos de conocimiento y herramientas de descubrimiento. Su función consistiría en diagnosticar correctamente por qué un sistema de búsqueda falla: si el problema reside en la cobertura documental, en los metadatos, en la desambiguación de entidades, en el algoritmo de recuperación, en el ranking, en la selección de evidencias o en la generación de respuestas por parte del modelo. Más que resolver directamente todos esos problemas, debería ser capaz de identificar qué tipo de conocimiento especializado resulta necesario en cada caso.
Según Aaron Tay, las once maneras de entender la búsqueda académica representan diferentes disciplinas y comunidades profesionales que analizan el descubrimiento de información desde perspectivas complementarias. Son las siguientes:
- Alfabetización informacional (Information Literacy)
Considera la búsqueda como una competencia que debe aprenderse y desarrollarse. El objetivo es que los usuarios sepan formular preguntas, elegir fuentes adecuadas, evaluar críticamente la información y utilizarla de forma ética.
- Comportamiento informacional (Information Behaviour)
Estudia cómo las personas buscan información en situaciones reales. Analiza las necesidades de información, las estrategias de búsqueda, la incertidumbre, la exploración y cómo evolucionan las consultas durante el proceso.
- Recuperación de información (Information Retrieval – IR)
Se centra en los algoritmos y modelos que permiten localizar los documentos más relevantes para una consulta. Incluye aspectos como la indexación, el ranking, la relevancia, la recuperación semántica y la evaluación de los sistemas de búsqueda.
- Recuperación interactiva de información (Interactive Information Retrieval – IIR)
Examina la interacción entre el usuario y el sistema de búsqueda. Estudia cómo las interfaces, la reformulación de consultas y la retroalimentación mejoran los resultados obtenidos.
- Revisiones sistemáticas y síntesis de evidencia (Systematic Searching / Evidence Synthesis)
Concibe la búsqueda como un componente esencial del método científico. Da prioridad a la exhaustividad, la reproducibilidad, la transparencia y la documentación detallada de las estrategias de búsqueda.
- Bibliometría y cienciometría (Bibliometrics / Scientometrics)
Utiliza la búsqueda para analizar la producción científica, las citas, las redes de colaboración, el impacto de las publicaciones y la evolución de las disciplinas.
- Organización del conocimiento (Knowledge Organization)
Se ocupa de cómo se describen y estructuran los recursos mediante metadatos, vocabularios controlados, tesauros, clasificaciones, ontologías y grafos de conocimiento para facilitar su descubrimiento.
- Bibliotecas y sistemas de descubrimiento (Library Discovery Systems)
Analiza las plataformas que integran catálogos, bases de datos, repositorios y recursos electrónicos, así como las decisiones sobre cobertura, relevancia y experiencia de usuario en los servicios bibliotecarios.
- Infraestructura de comunicación científica (Scholarly Communication Infrastructure)
Observa la búsqueda desde el punto de vista de las infraestructuras que hacen posible el descubrimiento: identificadores persistentes (DOI, ORCID), índices, repositorios, bases de datos, acceso abierto y metadatos interoperables.
- Motores de búsqueda académicos y plataformas comerciales (Academic Search Engines and Discovery Platforms)
Estudia cómo servicios como Google Scholar, Scopus, Web of Science, Semantic Scholar o Dimensions construyen sus índices, seleccionan contenidos y ordenan los resultados mediante algoritmos propios.
- Arquitectura del descubrimiento impulsada por IA (Discovery Architecture / AI Discovery) (la perspectiva emergente propuesta por Tay)
El autor advierte que esta capacidad de diagnóstico será insuficiente si las bibliotecas no exigen mayor transparencia a los proveedores de plataformas de búsqueda basadas en IA. Reclama acceso a registros de consultas, información sobre la cobertura de los índices, documentación de los criterios de clasificación, mecanismos para evaluar la relevancia de los resultados y posibilidades de auditar las distintas fases del proceso de recuperación y generación de respuestas. Sin esa apertura, afirma Tay, incluso reuniendo a especialistas de todas las disciplinas implicadas, cualquier análisis sobre el funcionamiento de estos sistemas seguirá siendo en gran medida especulativo. El artículo concluye anunciando una segunda parte dedicada a analizar dónde reside realmente la inteligencia de los nuevos sistemas de búsqueda: en los grandes modelos de lenguaje, en los mecanismos de recuperación documental o en la combinación de ambos mediante arquitecturas híbridas.