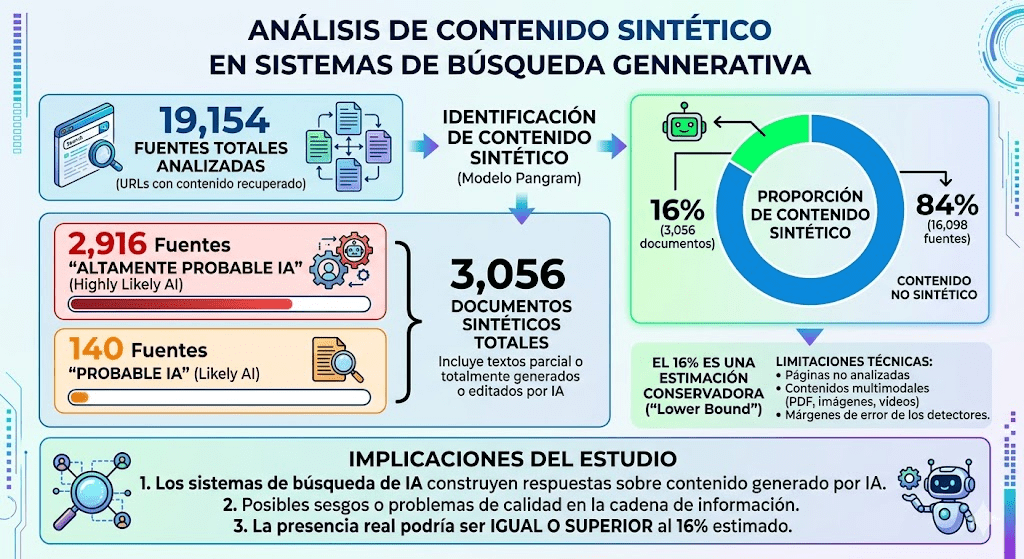
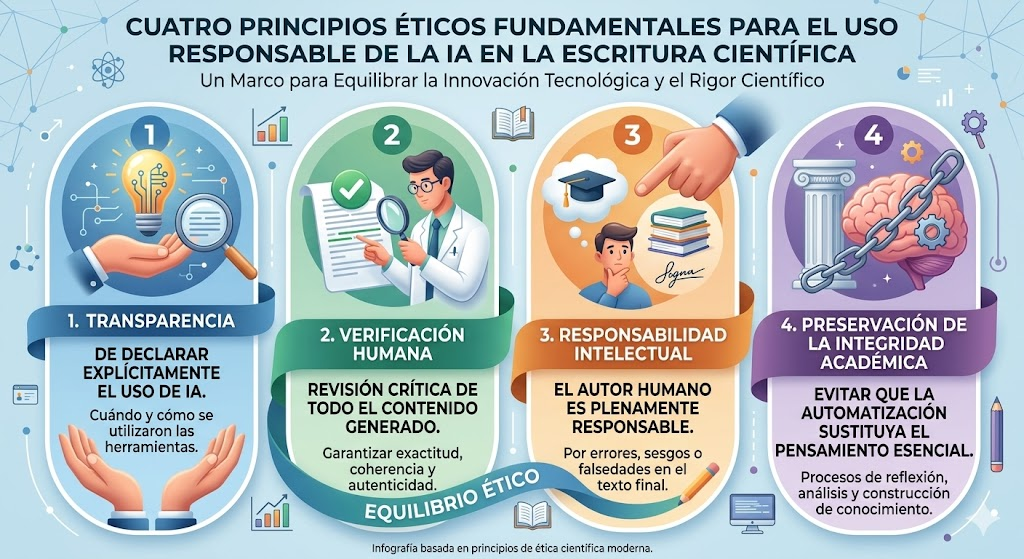
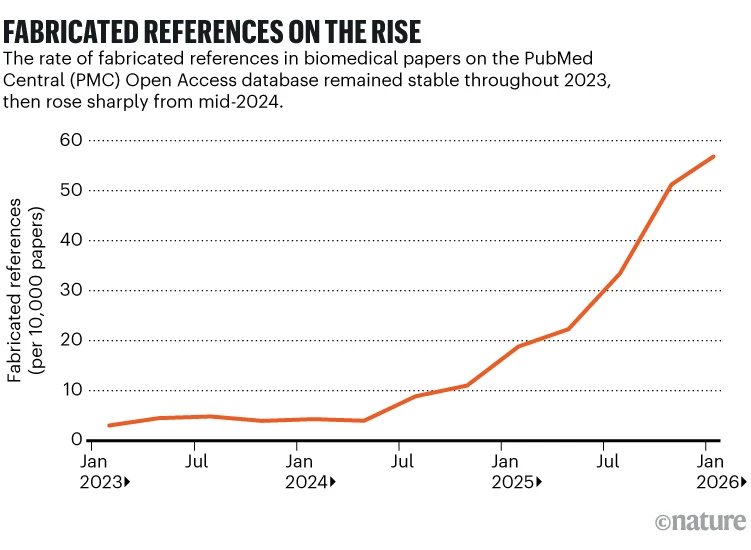
Cabrera Huaycochea, Daril. 2025. Declaración del uso de inteligencia artificial en la redacción de artículos académicos y tesis: Hacia un estándar ético y transparente para la producción científica en la era de los modelos de lenguaje de gran escala. ResearchGate. Consultado el 30 de mayo de 2026.
La expansión de los modelos de lenguaje de gran escala, como GPT, Claude o Gemini, ha transformado profundamente la producción académica, facilitando tareas como la redacción, la síntesis bibliográfica y la revisión textual. Sin embargo, este avance tecnológico no ha ido acompañado de normas homogéneas para declarar su utilización, generando importantes desafíos éticos relacionados con la transparencia, la autoría y la evaluación del mérito académico. El artículo de analiza esta problemática y propone un marco estandarizado para la declaración del uso de inteligencia artificial en artículos científicos y tesis.
El autor examina las políticas adoptadas por algunas de las principales instituciones y editoriales científicas internacionales, entre ellas arXiv, Elsevier, Nature y el Comité de Ética en Publicaciones (COPE). Aunque existen diferencias en los procedimientos, todas coinciden en dos principios fundamentales: las herramientas de inteligencia artificial no pueden ser consideradas autoras de trabajos académicos y cualquier utilización relevante debe ser declarada de manera explícita. Estas organizaciones subrayan que la responsabilidad sobre la exactitud, integridad y ética de los contenidos recae siempre en los autores humanos.
Uno de los principales aportes del trabajo es la formulación de una taxonomía de cuatro niveles de declaración. El Nivel 1 corresponde a trabajos elaborados sin IA generativa; el Nivel 2 contempla el uso de herramientas para corrección gramatical y estilística; el Nivel 3 incluye la generación de borradores, síntesis o análisis supervisados por los autores; y el Nivel 4 se refiere a aquellos casos en los que la IA participa de forma sustancial en la estructura argumentativa o conceptual del trabajo. El objetivo de esta clasificación no es juzgar moralmente los distintos usos de la tecnología, sino ofrecer un marco de transparencia que permita comprender el grado de intervención tecnológica en cada investigación.
El artículo también proporciona modelos prácticos de declaración para revistas científicas y tesis universitarias. Estas plantillas buscan facilitar la adopción de estándares comunes que permitan describir qué herramientas se utilizaron, en qué fases del proceso participaron y qué mecanismos de revisión humana se aplicaron posteriormente. Según el autor, la normalización de estas declaraciones contribuiría a reducir la ambigüedad normativa y fomentaría una cultura de integridad académica basada en la transparencia y la responsabilidad.
Se presta especial atención al contexto latinoamericano, donde identifica importantes desafíos relacionados con la desigualdad en el acceso a tecnologías avanzadas, la obsolescencia de los reglamentos universitarios y los sesgos lingüísticos de los modelos entrenados principalmente en inglés. Ante esta situación, propone que las universidades actualicen sus normativas y distingan claramente entre el uso declarado de la inteligencia artificial y el fraude académico por ocultamiento u omisión. La conclusión central del trabajo es que el verdadero debate no debe centrarse en prohibir o permitir la IA, sino en garantizar que su utilización sea transparente, verificable y compatible con los principios fundamentales de la integridad científica.