Hrynaszkiewicz, Iain. “Redefining Publishing: Why We’re Moving Beyond the Article.” Research Information, October 2, 2025. Research Information
El artículo de Iain Hrynaszkiewicz plantea una crítica de fondo al modelo tradicional de comunicación científica, centrado casi exclusivamente en el artículo académico y en el prestigio de la revista donde se publica. Según el autor, este sistema ya no refleja cómo se produce realmente la ciencia contemporánea ni cómo debería evaluarse. La investigación actual es más colaborativa, abierta, interdisciplinar y distribuida en múltiples fases, mientras que los mecanismos de reconocimiento siguen premiando sobre todo el resultado final: el paper. Esta desconexión genera incentivos distorsionados y dificulta valorar contribuciones esenciales como los datos, el código, los protocolos, la mentoría o la ciencia en etapas tempranas.
Para explicar que el cambio es posible, el texto recuerda innovaciones previas que transformaron la comunicación académica. Entre ellas destacan los identificadores persistentes como el DOI, que estabilizaron las citas digitales; ORCID, que permite identificar autores de forma inequívoca; la taxonomía CRediT, que reconoce distintos tipos de contribución; y el auge de los preprints y de la compartición de datos. Todas estas herramientas surgieron para resolver carencias del sistema y prosperaron gracias a la cooperación entre editoriales, universidades, financiadores e infraestructuras técnicas. El mensaje central es que la evolución de la ciencia depende menos de actores aislados y más de consensos colectivos sostenidos en el tiempo.
En ese contexto, el autor presenta la iniciativa de PLOS para replantear el ecosistema editorial mediante un proyecto de dieciocho meses financiado por fundaciones filantrópicas. Su propuesta principal es el denominado knowledge stack o “pila de conocimiento”: un sistema donde los distintos productos de investigación —datos, software, métodos, hipótesis, resultados parciales, revisiones y artículos finales— sean visibles, enlazables, atribuibles y evaluables como partes de un mismo proceso. Esto supone pasar de una lógica centrada en un único documento final a otra basada en un registro completo y continuo de la actividad científica.
El artículo también subraya que la ciencia abierta no debe entenderse solo como una obligación normativa impuesta por agencias financiadoras, sino como una oportunidad estratégica para universidades y centros de investigación. Compartir métodos, datos y resultados mejora la transparencia, facilita la reproducibilidad y fortalece la integridad científica. Además, puede aumentar la visibilidad institucional, acelerar descubrimientos y favorecer la competitividad internacional. Desde esta perspectiva, abrir la ciencia no es solo una cuestión ética, sino también una ventaja organizativa y reputacional.
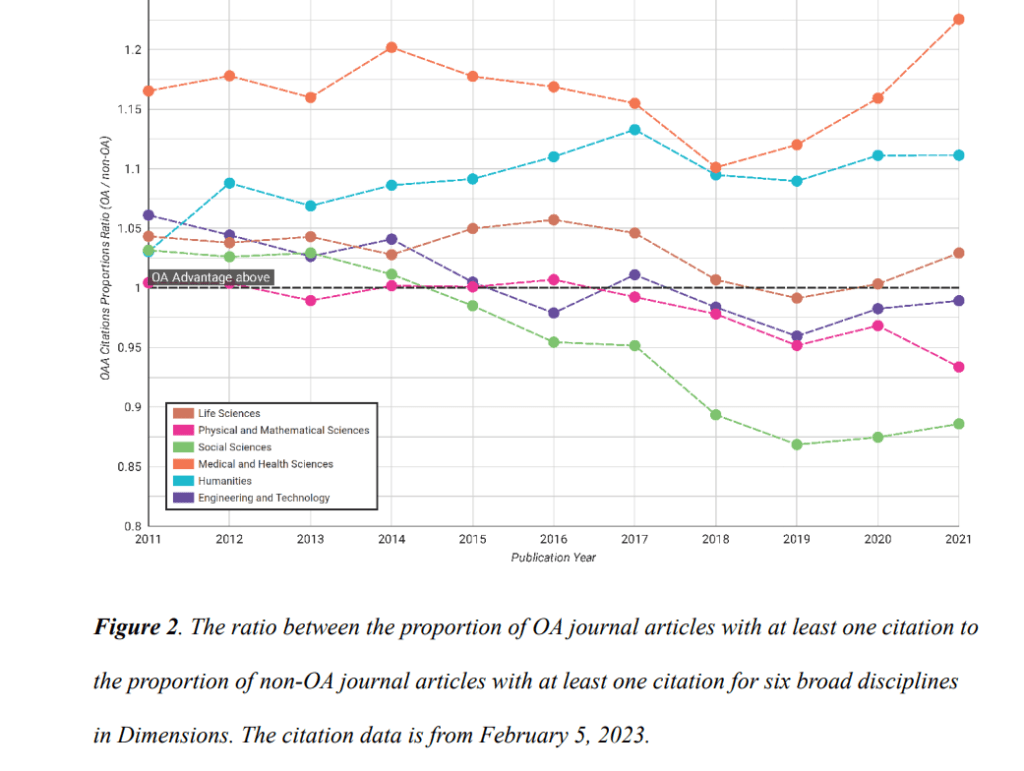
Otro aspecto relevante del texto es su mirada comparada sobre distintas regiones del mundo. El autor observa que Europa y Reino Unido avanzan más rápidamente en políticas de evaluación responsable y ciencia abierta, mientras que Asia y Norteamérica muestran progresos más desiguales o descentralizados. Aun así, en casi todos los contextos persiste la dependencia del artículo de revista como medida principal del mérito académico. Las inercias culturales, la presión competitiva por financiación y la dificultad de comparar disciplinas frenan reformas más profundas. Incluso quienes desean cambiar el sistema temen perjudicar a investigadores jóvenes si se apartan demasiado pronto de las reglas vigentes.
Finalmente, Hrynaszkiewicz concluye que el futuro de la publicación científica pasa por reconocer el conjunto del ciclo investigador y no solo su desenlace editorial. Un sistema más rico en metadatos, señales de impacto, trazabilidad de contribuciones y conexiones entre outputs permitiría premiar la colaboración, el riesgo intelectual, los resultados negativos y las prácticas responsables. No obstante, advierte que para lograr un cambio real se necesita adopción masiva: no basta con que una editorial innove, sino que deben sumarse financiadores, instituciones, infraestructuras y comunidades científicas de todo el mundo. En suma, el artículo defiende una transformación estructural del modelo académico, desde la cultura del paper hacia una ecología más abierta, justa y representativa del trabajo científico real.