A lawyer reviews and annotates legal documents during a courtroom proceeding.
Mach, Jessica. “Lawyer Who Used AI-Fabricated Citations Hit With $31,150 in Costs to LSO.” Law Times, junio de 2026.
Un tribunal disciplinario de la Law Society of Ontario impuso una sanción económica de 31.150 dólares canadienses al abogado Shahryar Mazaheri, después de comprobar que presentó documentos legales elaborados con inteligencia artificial que incluían citas jurisprudenciales inexistentes o incorrectas.
Un caso disciplinario en la provincia canadiense de Ontario ha vuelto a poner el foco en los riesgos del uso no supervisado de la inteligencia artificial en el ámbito jurídico. La Law Society of Ontario sancionó a un abogado, Shahryar Mazaheri, con el pago de 31.150 dólares canadienses en costas, tras comprobar que había presentado escritos legales que contenían citas jurisprudenciales generadas por IA que no existían en la realidad.
El incidente se produjo cuando el abogado utilizó herramientas de inteligencia artificial para preparar documentación en un procedimiento legal, sin realizar una verificación adecuada de las fuentes citadas. Como resultado, se incluyeron referencias a casos judiciales ficticios o incorrectamente atribuidos, lo que comprometió la integridad del proceso y obligó al tribunal a revisar en profundidad el material presentado.
La decisión del organismo regulador subraya que el problema no es el uso de herramientas de IA en sí mismo, sino la falta de supervisión profesional y verificación crítica. El tribunal dejó claro que los abogados pueden apoyarse en tecnologías emergentes, pero siguen teniendo una obligación estricta de garantizar la exactitud de toda la información presentada ante la justicia.
Además de la sanción económica, el caso se ha convertido en un precedente relevante en Canadá, ya que evidencia cómo la incorporación acelerada de la IA generativa en profesiones reguladas está generando nuevos desafíos éticos y legales. Entre las preocupaciones destacadas están la facilidad con la que estos sistemas pueden “alucinar” datos, la tentación de confiar excesivamente en ellos y la necesidad de establecer protocolos claros de validación.
El caso ha sido citado en debates más amplios sobre la regulación de la inteligencia artificial en profesiones como el derecho, la medicina o la contabilidad, donde la responsabilidad profesional no puede delegarse en sistemas automatizados. En este contexto, la resolución refuerza una idea clave: la IA puede asistir, pero la responsabilidad final sigue siendo humana y profesional.
En conjunto, el episodio marca un punto de inflexión en la relación entre tecnología y práctica jurídica, anticipando un escenario en el que los colegios profesionales deberán definir con mayor precisión los límites, usos permitidos y deberes de diligencia cuando se empleen herramientas de IA en entornos críticos.
Un problema creciente en bibliotecas y servicios de referencia: la proliferación de títulos de libros y citas académicas inventadas por sistemas de inteligencia artificial, que los usuarios toman como reales.
Imagina a un lector ávido que un día hojea una vista previa de libros de verano en su periódico local. Entre los títulos listados aparece una novela de una de sus escritoras favoritas, Isabel Allende. Intrigado, este lector acude a su biblioteca local para comprobar si tienen alguna copia de la novela, titulada Sueños de la costa, en su catálogo. Aquí está el problema: Sueños de la costa en realidad no existe; formaba parte de un artículo generado por inteligencia artificial que incluía varios libros inexistentes de autores famosos como Allende , y que causó revuelo durante el verano.
Y aunque la famosa lista de libros del verano recibió mucha atención mediática, también hay casos en los que sistemas de IA han “alucinado” la existencia de otros libros nunca escritos. Y, como era de esperar, esto se ha convertido en un enorme dolor de cabeza para los bibliotecarios (y, presumiblemente, para los libreros) encargados de buscar libros que no existen. Una bibliotecaria citada en el artículo afirmó que llevaba recibiendo solicitudes de libros inexistentes desde hace tres años, pero que el problema se había agravado a principios de este año.
Estas “alucinaciones” de la IA generan situaciones en las que los bibliotecarios reciben solicitudes de obras que no existen, a menudo atribuidas a autores reales o incluidas en listas de lectura publicadas en medios de comunicación. El fenómeno se ha intensificado con el uso masivo de chatbots, que producen referencias con apariencia convincente pero sin base real verificable.
El texto explica que esta situación está generando una carga adicional de trabajo para los profesionales de bibliotecas, que deben dedicar tiempo a verificar la existencia de cada solicitud, algo que antes era mucho más sencillo porque las referencias solían ser auténticas. Ahora, los sistemas de IA pueden generar títulos plausibles, completos con autores, editoriales y citas falsas, lo que dificulta la detección inmediata del error. Esta dinámica está afectando especialmente a bibliotecas públicas y servicios de referencia académica, donde los usuarios confían cada vez más en respuestas automatizadas sin contrastarlas.
Esta no es la única forma en que la IA ha complicado la vida de los bibliotecarios. También está el hecho de que ciertos actores sin escrúpulos utilizan la IA para generar libros rápidamente con fines de lucro, aunque sin la parte “divertida”. El auge de los libros generados por IA ha planteado preguntas existenciales para escritores y editores; como era de esperar, también ha supuesto un dolor de cabeza para los bibliotecarios. El siglo XXI ha visto avances tecnológicos que han facilitado la vida de escritores y editores, pero algunas de esas mismas herramientas también pueden volver el mundo del libro más inquietante cuando son usadas por actores malintencionados.
Finalmente, el artículo sitúa este problema dentro de un contexto más amplio de impacto de la inteligencia artificial en el ecosistema del libro y la información. Además de las bibliotecas, también se ven afectados autores, editores y plataformas de venta, ya que proliferan libros generados por IA, duplicados o fraudulentos. El texto subraya la importancia de reforzar la alfabetización informacional y el pensamiento crítico, así como la necesidad de que las instituciones tecnológicas mejoren los sistemas de verificación para evitar la propagación de información ficticia que parece real.
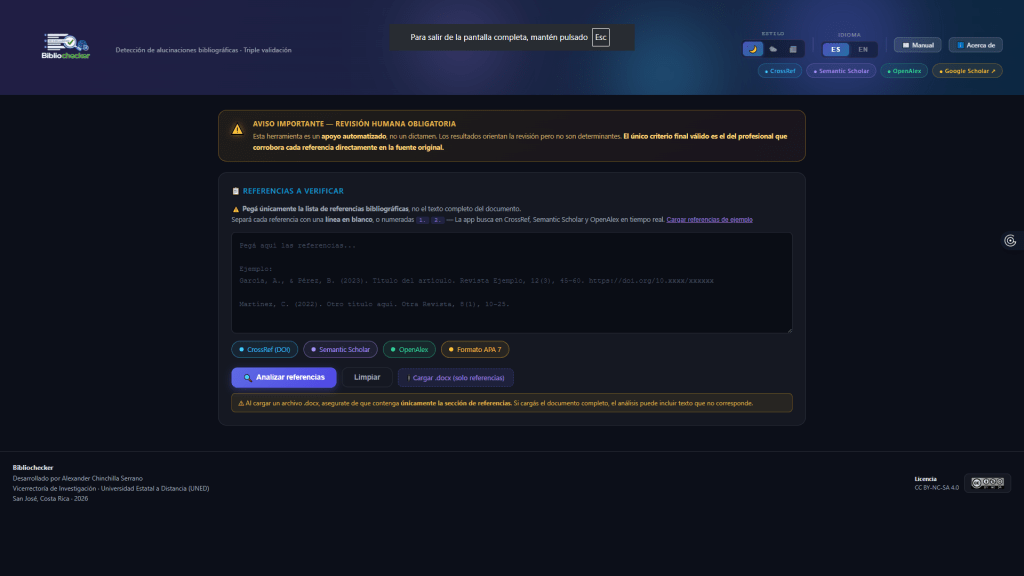
Bibliochecker ejemplifica cómo las nuevas herramientas de verificación automatizada pueden convertirse en aliadas estratégicas para preservar la integridad académica frente a los errores y alucinaciones producidas por la inteligencia artificial generativa.
En un contexto académico marcado por el uso creciente de sistemas de inteligencia artificial generativa como ChatGPT, Gemini o Claude, una de las preocupaciones más relevantes dentro de la investigación científica es la proliferación de “alucinaciones bibliográficas”, es decir, referencias inventadas o parcialmente incorrectas que los modelos generan al construir citas aparentemente plausibles pero inexistentes. Frente a este problema surge Bibliochecker, una herramienta web diseñada específicamente para verificar la autenticidad y consistencia de referencias bibliográficas generadas o asistidas por inteligencia artificial.
Bibliochecker se presenta como una aplicación accesible directamente desde el navegador, sin necesidad de instalación ni registro, lo que facilita su uso inmediato por parte de investigadores, estudiantes, bibliotecarios, editores científicos y revisores académicos. Su objetivo principal consiste en detectar posibles errores, inconsistencias o invenciones en listas bibliográficas, especialmente aquellas elaboradas mediante herramientas de IA. La plataforma automatiza la verificación cruzando la información proporcionada con bases de datos académicas consolidadas como CrossRef, Semantic Scholar y OpenAlex, lo que permite comprobar la existencia real de un documento, validar identificadores DOI y contrastar la coherencia entre título, autoría y fecha de publicación.
Una de sus fortalezas radica en la flexibilidad del ingreso de datos. El usuario puede introducir referencias de tres formas distintas: pegando directamente texto copiado desde documentos Word o PDF, cargando archivos en formato .docx que contengan exclusivamente la sección bibliográfica o utilizando ejemplos predeterminados para familiarizarse con el funcionamiento del sistema. La herramienta identifica automáticamente cada referencia incluso cuando estas aparecen en texto corrido o sin separación entre líneas, aplicando patrones inspirados en la normativa APA 7 para detectar estructuras bibliográficas.
El sistema permite activar distintos módulos de comprobación según las necesidades del usuario. El módulo de CrossRef verifica en tiempo real la validez del DOI y compara metadatos asociados; Semantic Scholar realiza búsquedas por similitud textual del título y verifica autoría y año; OpenAlex consulta su base académica abierta para confirmar coincidencias; mientras que un verificador específico examina si la referencia cumple con requisitos formales del estilo APA 7, revisando aspectos como el formato de autores, la correcta ubicación del año entre paréntesis, el uso de puntuación normativa o la presencia obligatoria del DOI en artículos científicos. Además, el sistema incorpora enlaces a Google Scholar para facilitar comprobaciones manuales complementarias.
Cada referencia analizada recibe un diagnóstico estructurado en cuatro categorías claramente diferenciadas. La categoría “Válida” indica que la obra fue localizada en las bases de datos sin inconsistencias detectadas. La categoría “Sospechosa” señala discrepancias parciales, como diferencias entre nombres de autores, títulos ligeramente distintos o inconsistencias cronológicas. La categoría “Problema” representa casos más graves, donde el DOI no existe o el documento no aparece en ninguna base académica consultada, sugiriendo una alta probabilidad de invención o error generado por IA. Finalmente, el estado “Sin DOI” identifica referencias donde no ha sido posible realizar validación automática mediante identificadores persistentes, algo frecuente en libros, tesis o documentos no indexados formalmente.
Otro elemento destacable es la posibilidad de exportar un reporte completo en formato HTML, generando una tabla estructurada con todos los resultados obtenidos. Este informe puede compartirse, archivarse o imprimirse, facilitando procesos editoriales, revisión académica o auditoría bibliográfica previa a la publicación de artículos científicos. La herramienta también incorpora distintos modos visuales —oscuro, claro y editorial sobrio— que mejoran la experiencia de uso en distintos contextos de trabajo.
Desde una perspectiva más amplia, Bibliochecker responde a una necesidad emergente dentro del ecosistema de la comunicación científica contemporánea: la verificación crítica de contenidos generados por inteligencia artificial. A medida que investigadores y estudiantes incorporan sistemas generativos en tareas de redacción académica, aumenta el riesgo de incluir citas falsas que comprometan la integridad científica. En este escenario, herramientas como Bibliochecker no sustituyen el criterio profesional humano, pero sí actúan como filtros preliminares de enorme valor para fortalecer la calidad documental y reducir errores antes de la difusión pública del conocimiento.
La propia plataforma insiste en una advertencia metodológica fundamental: sus resultados constituyen un apoyo automatizado y nunca un dictamen definitivo. Incluso una referencia marcada como válida puede contener errores que escapan a la detección automática, mientras que referencias catalogadas como sospechosas pueden corresponder a simples inconsistencias de metadatos o documentos no indexados en las bases consultadas. En otras palabras, Bibliochecker representa un ejemplo significativo del nuevo paradigma de colaboración entre inteligencia artificial y revisión humana experta, particularmente relevante para bibliotecas académicas, editoriales científicas y profesionales de la gestión de información digital.
Bove, Tristan. “AI Hallucinations in Research, Legal Filings, and Books Are Growing and Getting Harder to Fix.” Fortune, 24 de mayo de 2026. Fortune
El artículo analiza un problema cada vez más preocupante en la era de la inteligencia artificial: la incorporación de información falsa generada por sistemas de IA en documentos científicos, jurídicos, periodísticos y editoriales. Estas falsas afirmaciones, conocidas como “alucinaciones” de la IA, no son simples errores aislados, sino contenidos inventados que se presentan con apariencia de veracidad y que pueden terminar integrándose en el conocimiento académico y profesional.
El texto se centra especialmente en el caso de Maxim Topaz, investigador especializado en aplicaciones de IA para la salud. Durante la revisión de un artículo científico suyo, descubrió que una herramienta de inteligencia artificial había introducido una referencia bibliográfica inexistente sin advertirlo. Este incidente le llevó a investigar la magnitud del problema junto con otros colegas. Los resultados fueron alarmantes: tras analizar cerca de 2,5 millones de artículos biomédicos y alrededor de 97 millones de citas bibliográficas, identificaron más de 4.000 referencias falsas distribuidas en casi 3.000 trabajos científicos. Además, la frecuencia de estas referencias ficticias se ha multiplicado rápidamente desde la popularización de las herramientas de IA generativa.
El estudio revela que la presencia de referencias inexistentes en la literatura biomédica ha crecido de forma exponencial. Mientras que en 2023 aproximadamente uno de cada 2.828 artículos contenía alguna cita falsa, en 2025 la proporción había aumentado hasta uno de cada 458 trabajos. Los datos preliminares de 2026 muestran una tendencia todavía más preocupante, con una incidencia cercana a un artículo problemático por cada 277 publicados. Los investigadores consideran que estas cifras probablemente representan solo una parte del problema real, ya que muchas referencias falsas aún no han sido detectadas.
La preocupación principal radica en que la ciencia funciona como una cadena acumulativa de evidencias. Un artículo cita investigaciones previas, las revisiones sistemáticas sintetizan múltiples estudios y, posteriormente, las guías clínicas y protocolos médicos se basan en esas revisiones para orientar decisiones terapéuticas. Cuando una referencia inexistente se introduce en ese proceso, existe el riesgo de contaminar toda la cadena de conocimiento. En ámbitos como la medicina, esto podría afectar indirectamente a decisiones sobre diagnósticos, tratamientos o políticas sanitarias.
El artículo también destaca que el problema no se limita al ámbito científico. Casos recientes muestran cómo libros, informes periodísticos y documentos legales han incorporado citas o afirmaciones inventadas por sistemas de IA. En el sector jurídico, por ejemplo, se han documentado cientos de resoluciones y escritos legales que incluyen referencias erróneas generadas por modelos de lenguaje. Del mismo modo, algunos autores y periodistas han publicado obras que contenían citas inexistentes o atribuciones incorrectas producidas durante procesos de investigación asistidos por inteligencia artificial.
Otro aspecto especialmente inquietante es que la mayoría de estos errores no parecen ser fraudes deliberados. En muchos casos, los investigadores utilizan herramientas de IA para tareas aparentemente inocuas, como mejorar la redacción, corregir el estilo o formatear referencias. Sin embargo, los sistemas pueden introducir información falsa de manera silenciosa, lo que hace que incluso expertos familiarizados con las limitaciones de la IA puedan pasar por alto los errores. La confianza excesiva en estas herramientas aumenta el riesgo de que información incorrecta llegue a publicarse.
El artículo concluye señalando que la solución no consiste en abandonar la inteligencia artificial, sino en establecer procedimientos rigurosos de verificación. Los autores defienden que cualquier contenido generado o asistido por IA debe ser revisado cuidadosamente antes de incorporarse a publicaciones científicas, decisiones legales o productos informativos. La verdadera amenaza no es la existencia de errores ocasionales, sino que estos errores pasen desapercibidos y se integren en el registro permanente del conocimiento humano, dificultando posteriormente su corrección.
Allaham, Mowafak, and Nicholas Diakopoulos. 2026. Synthetic Sources?: Auditing Generative Search Engine Citations for Evidence of AI-Generated Sources. arXiv:2605.23684, May 2026. https://arxiv.org/abs/2605.23684
El artículo analiza un problema emergente en la ecosfera informativa contemporánea: la aparición de “fuentes sintéticas” en los sistemas de búsqueda generativa, es decir, referencias o citas que no provienen de documentos humanos tradicionales verificables, sino que podrían haber sido generadas parcial o totalmente por modelos de inteligencia artificial. Los autores se centran en cómo los motores de búsqueda basados en IA —que combinan recuperación de información con generación de texto— pueden introducir nuevos tipos de distorsión en la cadena de citación científica y periodística.
El trabajo parte de una preocupación central: los sistemas de búsqueda generativa no solo responden preguntas, sino que también construyen aparentes evidencias mediante citas, enlaces o referencias que parecen legítimas. Sin embargo, estas referencias pueden no corresponder a documentos reales, o pueden ser reconstrucciones plausibles generadas por el modelo. Esto plantea un riesgo crítico para la integridad del ecosistema informativo, ya que el usuario puede asumir que una cita es verificable cuando en realidad es una “alucinación documentada” o una fuente fabricada.
Metodológicamente, el estudio propone un enfoque de auditoría para examinar las respuestas de diferentes sistemas de búsqueda generativa. Los autores diseñan un conjunto de procedimientos para analizar la trazabilidad de las citas: verifican si los enlaces conducen a documentos reales, si las fuentes son consistentes con el contenido citado y si existen patrones recurrentes de generación de referencias inexistentes. Este enfoque permite clasificar las citas en diferentes categorías, incluyendo fuentes auténticas, fuentes parcialmente verificables y fuentes completamente sintéticas.
Los resultados muestran que una proporción significativa de las citas generadas por sistemas de IA no puede ser rastreada directamente a publicaciones reales o presenta inconsistencias importantes entre el contenido citado y la fuente original. Esto sugiere que los sistemas de búsqueda generativa pueden producir un tipo de “autoridad simulada”, donde la apariencia de rigor académico o periodístico no está respaldada por una verificación documental sólida.
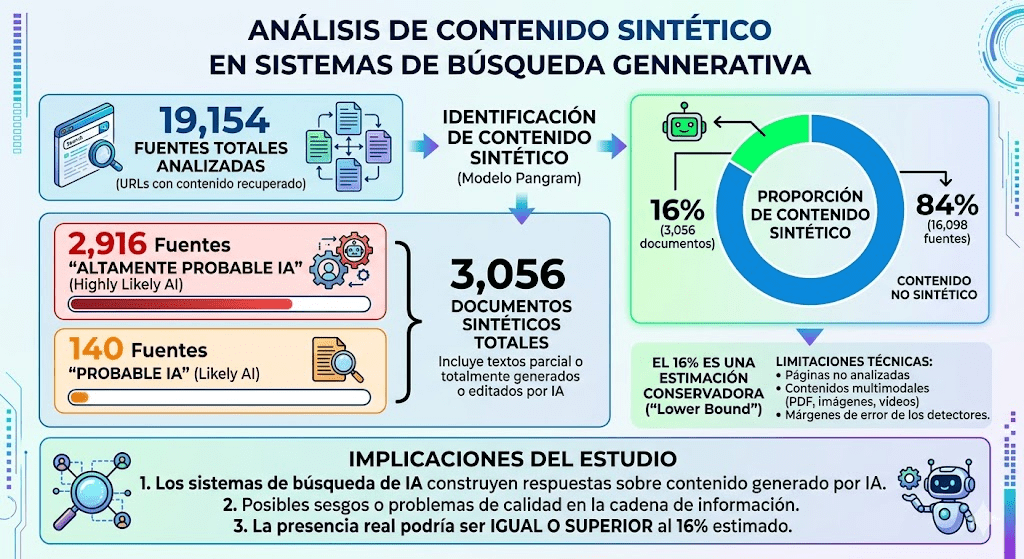
El estudio analiza en total 19.154 fuentes (URLs con contenido recuperado) que han sido citadas por distintos sistemas de búsqueda generativa. Estas fuentes representan el conjunto de documentos que los modelos consultan y utilizan como apoyo para construir sus respuestas a los usuarios. En este corpus amplio, los investigadores intentan determinar no solo qué dominios se citan, sino también la naturaleza del contenido que contienen.
Dentro de este conjunto, el sistema de detección de contenido generado por inteligencia artificial —en este caso, el modelo Pangram— identifica dos categorías principales de contenido sintético. Por un lado, 2.916 fuentes son clasificadas como “Highly Likely AI”, es decir, textos con una alta probabilidad de haber sido generados por modelos de lenguaje o sistemas automáticos. Por otro lado, 140 fuentes adicionales se clasifican como “Likely AI”, lo que indica una probabilidad significativa, aunque algo menos concluyente, de haber sido producidas o fuertemente asistidas por IA.
Al sumar ambas categorías, el estudio concluye que existen 3.056 documentos sintéticos en total dentro de las fuentes analizadas. Esta cifra no implica únicamente textos completamente generados por IA, sino también aquellos que pueden haber sido parcialmente producidos o editados mediante herramientas de inteligencia artificial, lo que amplía el concepto de “contenido sintético” utilizado en el análisis.
En términos proporcionales, estos 3.056 documentos representan aproximadamente un 16% del total de fuentes examinadas. Este dato es especialmente relevante porque indica que una parte no menor de las fuentes utilizadas por los sistemas de búsqueda generativa podría estar influida por procesos automatizados de generación de texto, lo que introduce posibles sesgos o problemas de calidad en la cadena de información.
El estudio subraya además que esta cifra debe interpretarse como una estimación conservadora o “lower bound”, es decir, un límite inferior. Esto significa que el 16% probablemente no refleja la totalidad real del fenómeno, ya que existen limitaciones técnicas importantes: no todas las páginas pudieron ser analizadas, algunos contenidos multimodales (como PDFs, imágenes o vídeos) quedaron fuera, y además los detectores de IA tienen márgenes de error inherentes.
En consecuencia, los autores advierten que la presencia real de contenido sintético en las citas podría ser igual o incluso superior al 16% estimado. Este resultado sugiere que los sistemas de búsqueda basados en IA están construyendo sus respuestas sobre un ecosistema informativo donde el contenido generado por IA ya es una fracción significativa y potencialmente creciente del total de fuentes disponibles en la web.
El artículo también discute las implicaciones teóricas y prácticas de este fenómeno. En primer lugar, plantea un desafío epistemológico: la noción tradicional de citación como mecanismo de validación del conocimiento se ve erosionada cuando las citas pueden ser generadas artificialmente. En segundo lugar, advierte sobre el impacto en la confianza pública en sistemas de información, especialmente en contextos de alta sensibilidad como salud, política o investigación académica. Finalmente, los autores proponen la necesidad de nuevos marcos de transparencia y auditoría para sistemas de búsqueda generativa. Esto incluye mecanismos automáticos de verificación de fuentes, estándares de trazabilidad de citas y políticas de diseño que eviten la generación de referencias no comprobables. El objetivo general es preservar la integridad del ecosistema informativo en un entorno donde la frontera entre contenido generado y contenido documentado se vuelve cada vez más difusa.
El funcionamiento y la fiabilidad de Google AI Overviews, el sistema de respuestas generadas por inteligencia artificial que aparece directamente en los resultados de búsqueda. El informe se centra en una cuestión clave del ecosistema digital actual: hasta qué punto estos resúmenes automáticos pueden considerarse fiables cuando están mediando entre los usuarios y la información en la web.
La investigación parte de una evaluación técnica realizada con metodologías de benchmarking, que sugiere que, aunque el sistema muestra un alto nivel de acierto general, sigue produciendo un volumen significativo de errores debido a la naturaleza probabilística de los modelos de lenguaje.
Uno de los hallazgos principales es que los AI Overviews alcanzan aproximadamente entre un 90% y 91% de precisión en tareas evaluadas, lo que en términos relativos puede parecer un rendimiento elevado. Sin embargo, el artículo subraya que esta cifra adquiere otra dimensión cuando se aplica a la escala masiva de Google, que procesa billones de consultas anuales. En este contexto, incluso un margen de error del 9–10% se traduce en millones de respuestas incorrectas difundidas diariamente, lo que plantea un problema estructural de fiabilidad en la infraestructura informativa global.
El texto también profundiza en la naturaleza del error en los sistemas de inteligencia artificial generativa. A diferencia de los motores de búsqueda tradicionales, que devuelven enlaces a fuentes externas, los AI Overviews sintetizan respuestas directamente. Este proceso implica que los modelos no “verifican” la verdad de la información, sino que generan textos basados en patrones estadísticos de lenguaje. Como resultado, pueden producir afirmaciones plausibles pero incorrectas, especialmente cuando las fuentes subyacentes son ambiguas, contradictorias o de baja calidad.
Otro aspecto relevante del análisis es el impacto epistemológico de este tipo de tecnología. El artículo señala que la integración de respuestas generadas por IA en la parte superior de los resultados de búsqueda transforma la relación entre usuarios e ინფორმაცია: en lugar de acceder a múltiples fuentes para contrastar información, los usuarios reciben una síntesis única que puede ocultar la diversidad o el conflicto entre datos. Esto introduce una tensión entre eficiencia y verificación, ya que la rapidez del acceso a la información puede debilitar los procesos de comprobación crítica.
El informe plantea implicaciones más amplias para el ecosistema digital y la confianza pública en la información en línea. Aunque Google defiende que el sistema mejora continuamente y reduce errores, el estudio sugiere que la escala del problema sigue siendo significativa. En consecuencia, el artículo concluye que la cuestión central no es solo la precisión técnica del sistema, sino su impacto en la arquitectura del conocimiento digital: la forma en que la inteligencia artificial reconfigura qué información se ve, cómo se interpreta y en qué medida puede considerarse fiable en un entorno informativo cada vez más mediado por algoritmos.
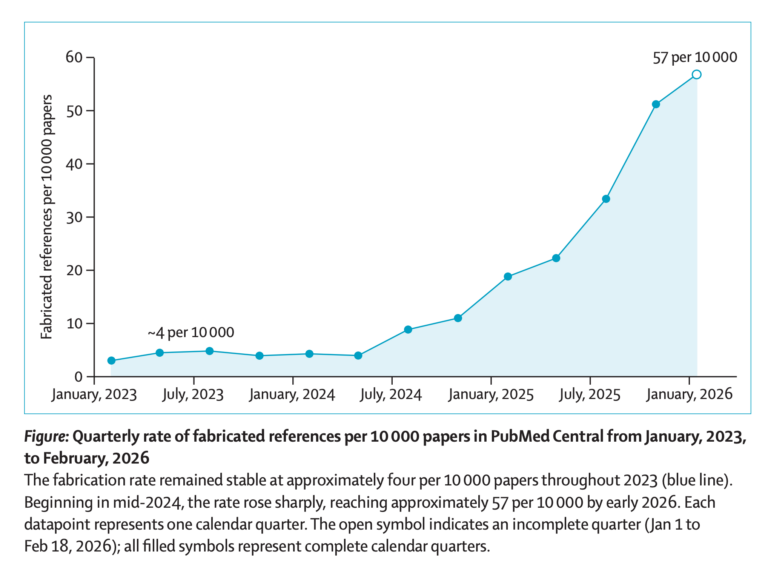
Un análisis reciente difundido por Retraction Watch advierte de un crecimiento muy acusado de las referencias bibliográficas falsas dentro de la literatura biomédica indexada en PubMed. El estudio, presentado en forma de carta en The Lancet, examinó cerca de 2,5 millones de artículos científicos y concluyó que las citas inventadas se han multiplicado por doce en apenas dos años.
Los investigadores detectaron que aproximadamente uno de cada 277 artículos publicados en las primeras siete semanas de 2026 incluía al menos una referencia a un trabajo inexistente. La comparación histórica muestra una escalada preocupante: en 2025 la proporción era de uno entre 458, mientras que en 2023 era de uno entre 2.828. Esto sugiere que el fenómeno no es marginal, sino creciente y sistemático.
El equipo estuvo liderado por Maxim Topaz, del Data Science Institute de la Universidad de Columbia. Para separar errores tipográficos o abreviaturas irregulares de verdaderas invenciones bibliográficas, los autores emplearon herramientas de inteligencia artificial capaces de contrastar títulos y registros reales. Esto permitió identificar con mayor precisión qué citas eran simplemente incorrectas y cuáles correspondían a documentos inexistentes.
Según el informe, el aumento más brusco comenzó a mediados de 2024, coincidiendo con la expansión masiva de herramientas de escritura asistida por IA generativa. El artículo relaciona este crecimiento con el uso inadecuado de modelos de lenguaje capaces de producir referencias aparentemente verosímiles, aunque inexistentes, si no se supervisan correctamente.
Las implicaciones son profundas para la comunicación científica. Las referencias falsas contaminan revisiones bibliográficas, dificultan la verificación de fuentes y erosionan la confianza en el sistema académico. El caso refuerza la necesidad de controles editoriales más estrictos, verificadores automáticos de citas y formación ética en el uso de IA para la redacción científica.
Se analiza una distinción clave en el ecosistema informativo contemporáneo: la diferencia entre la desinformación generada por inteligencia artificial y las llamadas “alucinaciones” de la IA. Aunque ambos fenómenos implican la producción de información falsa o engañosa, su origen y naturaleza son distintos.
La desinformación en IA suele estar vinculada a la intención humana: se genera o difunde contenido falso de manera deliberada para manipular, influir o engañar. En cambio, las alucinaciones son errores inherentes al funcionamiento de los modelos de lenguaje, que producen información incorrecta sin intención maliciosa, simplemente porque “rellenan” lagunas con contenido plausible pero no verificado.
El texto profundiza en las causas técnicas de las alucinaciones, señalando que estas surgen de limitaciones estructurales de los sistemas de IA. Los modelos funcionan mediante generación probabilística: predicen qué texto es más probable en función de patrones aprendidos, no de una verificación factual. Esto puede llevar a la invención de datos, citas académicas inexistentes o errores históricos. Factores como datos de entrenamiento incompletos o sesgados, así como limitaciones en la arquitectura de los modelos, contribuyen a este fenómeno. En esencia, la IA no “miente”, sino que construye respuestas verosímiles a partir de patrones, lo que puede resultar en afirmaciones erróneas presentadas con gran coherencia.
Por otro lado, la desinformación impulsada por IA se inscribe en dinámicas sociales más amplias. No depende tanto de fallos técnicos como de usos intencionados de la tecnología: desde la creación de contenidos engañosos mediante técnicas como el prompt engineering hasta su difusión masiva a través de redes sociales, bots o influencers. Este tipo de desinformación explota los sesgos cognitivos de los usuarios y puede tener consecuencias especialmente graves en ámbitos como la política, la salud o la opinión pública.
El artículo subraya que, aunque ambos fenómenos pueden parecer similares para el usuario —información falsa presentada de forma convincente—, requieren estrategias distintas de mitigación. Las alucinaciones demandan mejoras técnicas en los modelos, como mejores datos de entrenamiento o sistemas de verificación interna. La desinformación, en cambio, exige respuestas sociales, regulatorias y educativas, incluyendo alfabetización mediática y control de los canales de difusión.
Por último, se destaca que el auge de la inteligencia artificial ha intensificado el problema de la fiabilidad de la información. Estudios recientes muestran que una proporción significativa de respuestas generadas por IA puede ser incorrecta o engañosa, lo que pone en riesgo la integridad del ecosistema informativo. En este contexto, comprender la diferencia entre desinformación y alucinación no es solo una cuestión técnica, sino una competencia crítica para navegar en un entorno cada vez más mediado por algoritmos.
Se plantea una advertencia fundamental en la era de la inteligencia artificial generativa: la apariencia de seguridad en una respuesta no equivale a su veracidad. Los sistemas de IA están diseñados para producir textos coherentes, fluidos y convincentes, lo que genera una ilusión de autoridad que puede inducir a error.
Esta característica no es accidental, sino inherente a su funcionamiento: los modelos predicen qué respuesta “suena” correcta basándose en patrones estadísticos, no en una comprensión real de la verdad. Así, la confianza expresiva de la IA puede enmascarar errores, lagunas o incluso invenciones, lo que obliga a replantear cómo interpretamos y evaluamos sus respuestas.
El texto subraya que este fenómeno tiene profundas implicaciones educativas e informativas. Tradicionalmente, los humanos han asociado la confianza con la competencia, confiando más en quienes se expresan con seguridad. La IA explota involuntariamente este sesgo cognitivo: presenta información con una estructura clara y un tono firme, lo que reduce la tendencia del usuario a cuestionar su contenido. Sin embargo, como advierten diversos análisis, esta “brecha de confianza” puede llevar a aceptar respuestas incorrectas simplemente porque están bien formuladas. En contextos académicos o profesionales, esto puede erosionar el pensamiento crítico y fomentar una dependencia excesiva de sistemas automatizados.
Otro aspecto relevante es que la calidad de las respuestas depende en gran medida de cómo se formula la pregunta. Los usuarios con mayor conocimiento previo o habilidades de “prompting” obtienen resultados más precisos y útiles, mientras que quienes carecen de estas competencias pueden recibir respuestas superficiales o incompletas. Esto introduce un nuevo tipo de desigualdad informativa: no todos los usuarios acceden al mismo nivel de calidad en la información generada por IA, lo que cuestiona la idea de que estas herramientas democratizan el conocimiento.
El artículo también insiste en que la IA no distingue adecuadamente entre niveles de certeza. Puede presentar hechos bien establecidos y afirmaciones especulativas con el mismo grado de seguridad, dificultando que el usuario discrimine entre información fiable y dudosa. Este “aplanamiento de la certeza” es especialmente problemático en ámbitos como la salud, la educación o la toma de decisiones, donde la precisión y el contexto son esenciales.
Por ello se propone una actitud crítica y reflexiva como respuesta a este desafío. La IA debe entenderse como una herramienta de apoyo, no como una autoridad definitiva. Verificar la información, contrastarla con fuentes fiables y mantener el juicio propio se convierten en habilidades clave en este nuevo entorno. En última instancia, el artículo no rechaza el uso de la inteligencia artificial, pero advierte que su integración en la vida cotidiana exige una alfabetización informacional más sofisticada, capaz de distinguir entre lo que suena convincente y lo que realmente es cierto.
El informe MAHA, publicado en mayo de 2025 y encargado a la secretaria de Salud y Servicios Humanos, Robert F. Kennedy Jr., contenía numerosas referencias a estudios que no existían o eran fabricados, lo que sugiere que partes significativas del texto podrían haber sido generadas mediante prompts a sistemas de generative AI (IA generativa)
El informe Make America Healthy Again (MAHA), un documento emblemático publicado por la Comisión MAHA bajo la administración de Donald Trump, centrado en la salud infantil y en causas de enfermedad crónica en Estados Unidos. Una investigación del propio medio reveló originalmente que al menos siete citas incluidas en la versión inicial del informe simplemente no existían en la literatura científica —es decir, atribuían estudios que no estaban publicados o que jamás fueron escritos por los autores listados— lo que llevó a una fuerte preocupación por la integridad científica del texto.
Ante esta revelación, la Casa Blanca y el Departamento de Salud y Servicios Humanos (HHS) procedieron a reemplazar las citas inexistentes en una nueva versión del informe publicada en el sitio oficial de la Casa Blanca. Cinco de las referencias falsas fueron sustituidas por trabajos completamente distintos, y dos por estudios reales de los mismos autores mencionados previamente, aunque con títulos y contenidos distintos. Por ejemplo, un estudio epidemiológico supuestamente escrito por la investigadora Katherine Keyes fue reemplazado por un enlace a un artículo de KFF Health News sobre un tema similar, y otras referencias vinculadas a publicidad de medicamentos en niños se cambiaron por artículos periodísticos y estudios más antiguos sobre tendencias en uso de psicofármacos. Aunque estas nuevas fuentes parecen corresponder a estudios legítimos, no está claro si respaldan de manera precisa las afirmaciones formuladas en el informe original.
Además de sustituir las citas inexistentes, la versión actualizada también modificó referencias que habían sido mal interpretadas en la versión previa. Por ejemplo, un estudio que se usó para sostener que la psicoterapia es tan eficaz como los medicamentos en el corto plazo fue reemplazado después de que uno de los autores originales señalará a NOTUS que su investigación no incluía psicoterapia dentro de los parámetros analizados. A pesar de los cambios, tanto la Casa Blanca como funcionarios de HHS minimizaron la gravedad de los errores, describiéndolos como problemas menores de formato que ya habían sido corregidos, y defendieron la sustancia general del informe. Voceros oficiales declararon que el documento sigue siendo una evaluación histórica y transformadora para entender la epidemia de enfermedades crónicas que afectan a los niños estadounidenses, y subrayaron que los ajustes no alteran sus conclusiones principales.
Sin embargo, la actualización y corrección de citas ha suscitado debates profundos sobre los estándares de rigor científico que deben aplicarse a informes gubernamentales de salud pública, especialmente cuando estos documentos se utilizan para formular políticas importantes. Organizaciones periodísticas, científicos y legisladores han cuestionado la confiabilidad de las referencias del MAHA report y han pedido mayor transparencia en cómo se elaboran y revisan estos textos, así como sobre el uso de tecnologías como la inteligencia artificial durante su redacción. La situación ilustra las tensiones entre la comunicación científica, la integridad académica y las prioridades políticas en la producción de informes de política pública.