Khelfaoui, Mahdi, y Yves Gingras. “What’s in a Name? Scholarly Journal Title Changes and the Quest for International Visibility (1965–2020).” Journal of the Association for Information Science and Technology, publicado en línea el 3 de marzo de 2025. https://doi.org/10.1002/asi.24989
En las últimas seis décadas, las revistas académicas han experimentado un proceso de des-nacionalización y anglicización de sus títulos con el objetivo de incrementar su visibilidad internacional y facilitar su indexación en bases de datos científicas de prestigio, como Web of Science y Scopus. Este fenómeno responde a la creciente presión por la internacionalización de la ciencia y la necesidad de cumplir con los estándares globales de evaluación de la investigación, en los que el idioma inglés juega un papel predominante.
El análisis realizado a partir de datos de Web of Science revela que la tendencia a modificar los títulos de las revistas no ha sido homogénea en todos los países ni en todas las disciplinas. En algunos periodos, ciertos países han mostrado una mayor predisposición a realizar estos cambios, influenciados por políticas científicas nacionales y la estructura de sus sistemas de educación superior e investigación. Durante los años 80, con la expansión del concepto de internacionalización en la ciencia, se observó un aumento en los cambios de título, que se intensificó aún más en la década de los 90 con la consolidación del uso de indicadores cuantitativos, como el factor de impacto, para medir la calidad y el reconocimiento de las publicaciones.
Uno de los efectos más notables de esta estrategia ha sido la sustitución progresiva de los idiomas nacionales por el inglés en la publicación de artículos científicos. Si bien este cambio ha permitido que las revistas accedan a una audiencia global y atraigan a investigadores de distintos países, también ha generado preocupaciones sobre la pérdida de diversidad lingüística en la producción del conocimiento. En muchos casos, esta transformación ha llevado al desplazamiento de revistas que anteriormente cumplían un papel clave en la difusión de investigaciones en contextos locales o regionales.
Además, el proceso de anglicización ha modificado la composición de la autoría y la audiencia de las revistas. Al hacer sus publicaciones más accesibles a un público internacional, muchas revistas han atraído colaboraciones con investigadores extranjeros y han ampliado su base de lectores. Sin embargo, este cambio también ha significado que algunos investigadores que no dominan el inglés enfrenten barreras adicionales para publicar y difundir sus trabajos en su propio idioma.
Si bien la estrategia de cambio de nombre ha contribuido a mejorar la posición de las revistas en el mercado global de publicaciones científicas, ha tenido un costo en términos de diversidad lingüística y de acceso equitativo a la producción y difusión del conocimiento. Este fenómeno plantea preguntas sobre el equilibrio entre la internacionalización y la preservación de la identidad cultural y lingüística en la ciencia.
A medida que la evaluación de la investigación sigue dependiendo de métricas como el factor de impacto y la indexación en bases de datos anglófonas, es probable que la tendencia continúe. Sin embargo, iniciativas recientes buscan valorar la producción científica en otros idiomas y promover modelos de publicación más inclusivos, que reconozcan la importancia de las lenguas nacionales en la generación y transmisión del conocimiento.
Padula, Danielle. «Optimizing Journal Technical Checks to Improve Peer Review and Publishing Efficiency.» Scholastica Blog. Última modificación el 28 de febrero de 2024.
Las revisiones técnicas en revistas académicas garantizan que los manuscritos cumplan requisitos básicos de calidad, ética y formato antes de pasar a revisión por pares. Un proceso estandarizado agiliza tiempos, mejora la evaluación y previene errores. Además, simplificar instrucciones y automatizar validaciones optimiza el flujo editorial.
Antes de enviar artículos a revisión por pares y eventual publicación, las revistas académicas deben realizar revisiones técnicas o controles de calidad. Estas revisiones tienen como objetivo garantizar que los manuscritos cumplen con los requisitos básicos de información, políticas editoriales y normativas éticas del journal. De esta manera, se decide si el artículo puede avanzar a revisión por pares o si debe ser rechazado directamente (desk reject). Además, algunos aspectos técnicos pueden revisarse en fases posteriores del proceso editorial, especialmente cuando los manuscritos están más cerca de su aceptación definitiva.
Contar con un proceso estandarizado de revisiones técnicas aporta múltiples beneficios: asegura que los artículos cumplen con estándares éticos y formales, acelera la revisión por pares al evitar que trabajos incompletos avancen y permite que los revisores se concentren en evaluar el contenido científico sin distraerse por aspectos técnicos o formales. Además, ayuda a prevenir retrasos en la publicación derivados de errores o carencias detectadas demasiado tarde.
Cada revista debe adaptar su lista de chequeo técnico según su disciplina y sus procedimientos editoriales, pero hay aspectos comunes a tener en cuenta. Primero, la relevancia del artículo y la integridad de la presentación son fundamentales: comprobar que el título y el resumen son claros y precisos, que los datos de autoría son completos y correctos, que se ha incluido información sobre financiación y que se han proporcionado las palabras clave y la carta de presentación cuando sea necesario. Esto asegura que la contribución encaja dentro del alcance temático de la revista y cumple con los elementos básicos para su evaluación.
En segundo lugar, es crucial verificar que el manuscrito respeta las políticas editoriales y éticas del journal. Esto incluye declaraciones de originalidad, permisos para material reproducido, posibles conflictos de interés y el uso adecuado de herramientas de detección de plagio. También se revisan aspectos como la disponibilidad de los datos utilizados, la mención de fuentes públicas de datos (con DOI cuando proceda), y la declaración sobre el uso de inteligencia artificial en la elaboración del manuscrito. Si el estudio involucra ensayos clínicos, humanos o animales, también deben comprobarse los permisos éticos, consentimiento informado, aprobaciones institucionales y cumplimiento de guías de reporte reconocidas (como CONSORT o PRISMA).
Otro punto clave de la revisión técnica es evaluar de manera preliminar la calidad del contenido. Esto implica verificar que el lenguaje sea claro y profesional, que no haya errores graves de redacción, y que las figuras, tablas y fórmulas sean legibles y cumplan con las normas del journal. También debe revisarse que los métodos estadísticos estén correctamente descritos y que los resultados incluyan métricas adecuadas, como intervalos de confianza o valores p.
Por último, se debe revisar la estructura y el formato del manuscrito, aunque es recomendable no exigir un nivel excesivo de detalle en esta fase inicial. Se trata de asegurar aspectos básicos como que el texto respete los límites de palabras, que las figuras y tablas estén numeradas y etiquetadas correctamente, y que los materiales suplementarios estén bien identificados.
Para optimizar el proceso de revisiones técnicas, es esencial buscar un equilibrio: deben ser lo suficientemente exhaustivas para evitar que manuscritos inadecuados lleguen a revisión por pares, pero no tan minuciosas que ralenticen los tiempos de decisión inicial. Una buena estrategia es limitar al máximo los requisitos formales innecesarios en los manuscritos, como tipografías específicas o estilos de cita, sobre todo si la revista cuenta con herramientas de producción que automatizan esos aspectos tras la aceptación. Asimismo, es fundamental ofrecer a los autores instrucciones claras y simplificadas, organizadas de manera accesible y coherente, con ejemplos, plantillas y formularios estandarizados.
Finalmente, otra vía de optimización es aprovechar las funcionalidades de los formularios de envío de manuscritos en los sistemas de gestión editorial. Configurando campos obligatorios, validaciones automáticas (por ejemplo, de ORCID, afiliaciones institucionales o fuentes de financiación) y casillas de aceptación de políticas éticas, se minimizan errores y omisiones desde el momento del envío, reduciendo así la carga del equipo editorial en las revisiones técnicas.
En resumen, una lista de chequeo técnico bien diseñada y un proceso ágil permiten mejorar la experiencia tanto del equipo editorial como de los autores y revisores, favoreciendo tiempos de publicación más cortos y una mayor calidad en los procesos editoriales.
Académicos de la Universidad de Míchigan advierten que el aumento en los costos de suscripción a revistas académicas está afectando la investigación. Según la Asociación de Bibliotecas de Investigación, los precios de estas publicaciones han aumentado un 8,5 % anual entre 1986 y 2001, lo que dificulta el acceso a estudios fundamentales.
El aumento constante en los costos de suscripción y publicación de revistas académicas ha generado preocupaciones significativas en la comunidad investigadora, ya que estos incrementos pueden obstaculizar el acceso al conocimiento y limitar la difusión de nuevos hallazgos científicos.
Expertos como Cindy Lustig, profesora de psicología, señalan que los editores priorizan las ganancias sobre la accesibilidad. Además, investigadoras como Chloe Brookes temen que el incremento de costos genere un sesgo en la producción de conocimiento. Kara Zivin, profesora de psiquiatría en Salud Pública, advierte que los altos costos pueden desincentivar a jóvenes investigadores a publicar en revistas de acceso abierto.
Además, los cargos por procesamiento de artículos (APC, por sus siglas en inglés) en revistas de acceso abierto han alcanzado cifras elevadas. Por ejemplo, publicar en revistas de alto impacto puede costar hasta 10.000 euros por artículo, una cantidad que excede los costos reales de publicación y aumenta las ganancias de las grandes editoriales.
El aumento de los costos no solo afecta a las instituciones, sino que también tiene implicaciones directas en la diversidad y calidad de la investigación. Investigadores de países con menos recursos pueden enfrentar barreras financieras para publicar sus trabajos, lo que limita la representación de diversas perspectivas en la literatura científica. Además, la presión por publicar en revistas de alto impacto ha fomentado la proliferación de «revistas depredadoras» que, a cambio de una tarifa, publican artículos sin una revisión rigurosa, comprometiendo la calidad y credibilidad de la investigación científica
Ante este panorama, han surgido diversas iniciativas para contrarrestar los efectos negativos del modelo tradicional de publicación. El movimiento hacia el acceso abierto busca democratizar el acceso al conocimiento científico, permitiendo que los resultados de la investigación estén disponibles de manera gratuita para la comunidad global. Sin embargo, la transición hacia este modelo presenta desafíos, como la necesidad de financiamiento sostenible y la resistencia de algunas editoriales a modificar sus estructuras de negocio
La universidad ha implementado estrategias para mitigar estos efectos, como la alianza Big Ten Academic Alliance y el préstamo interbibliotecario. Sin embargo, Alan Piñon, director de comunicación de la biblioteca, advierte que, si los costos siguen subiendo, podrían reducirse las suscripciones a ciertos materiales. También resalta la importancia de preservar la información para futuras generaciones.
En la última década, entidades comerciales depredadoras de todo el mundo han industrializado la producción, venta y difusión de investigaciones académicas falsas, socavando la literatura en la que se basan desde médicos hasta ingenieros para tomar decisiones sobre vidas humanas.
Resulta extremadamente difícil determinar con exactitud la magnitud del problema. Hasta la fecha se han retirado unos 55.000 artículos académicos por diversos motivos, pero los científicos y las empresas que analizan la literatura científica en busca de indicios de fraude calculan que circulan muchos más artículos falsos, posiblemente hasta varios cientos de miles. Estas investigaciones falsas pueden confundir a los investigadores legítimos, que deben vadear densas ecuaciones, pruebas, imágenes y metodologías sólo para descubrir que son inventadas.
Incluso cuando se descubren los artículos falsos -generalmente por detectives aficionados en su tiempo libre-, las revistas académicas suelen tardar en retractarse, lo que permite que los artículos manchen lo que muchos consideran sacrosanto: la vasta biblioteca mundial de trabajos académicos que introducen nuevas ideas, revisan otras investigaciones y discuten hallazgos.
Cuando Adam Day ejecutó el programa Papermill Alarm de su empresa en los 5,7 millones de artículos publicados en 2022 en la base de datos OpenAlex, descubrió un número preocupante de artículos potencialmente falsos, especialmente en biología, medicina, informática, química y ciencia de los materiales. Papermill Alarm señala los artículos que contienen similitudes textuales con falsificaciones conocidas.
Estos documentos falsos están frenando una investigación que ha ayudado a millones de personas con medicamentos y terapias que salvan vidas, desde el cáncer hasta el COVID-19. Los datos de los analistas muestran que los campos relacionados con el cáncer y la medicina están especialmente afectados, mientras que áreas como la filosofía y el arte lo están menos. Algunos científicos han abandonado el trabajo de su vida porque no pueden seguir el ritmo ante la cantidad de documentos falsos que deben rechazar.
El problema refleja una mercantilización mundial de la ciencia. Las universidades, y quienes financian la investigación, llevan mucho tiempo utilizando la publicación regular en revistas académicas como requisito para ascensos y seguridad laboral, dando lugar al mantra «publicar o perecer».
Pero ahora, los estafadores se han infiltrado en la industria editorial académica para dar prioridad a los beneficios sobre la erudición. Equipados con destreza tecnológica, agilidad y vastas redes de investigadores corruptos, están produciendo artículos sobre todo tipo de temas, desde genes oscuros hasta la inteligencia artificial en medicina.
Estos artículos se incorporan a la biblioteca mundial de la investigación más rápido de lo que pueden ser eliminados. Cada semana se publican en todo el mundo unos 119.000 artículos académicos y ponencias en congresos, lo que equivale a más de 6 millones al año. Los editores calculan que, en la mayoría de las revistas, alrededor del 2% de los artículos presentados -pero no necesariamente publicados- son probablemente falsos, aunque esta cifra puede ser mucho mayor en algunas publicaciones.
Aunque ningún país es inmune a esta práctica, es particularmente pronunciada en las economías emergentes, donde los recursos para hacer ciencia de buena fe son limitados y donde los gobiernos, deseosos de competir a escala mundial, impulsan incentivos particularmente fuertes de «publicar o perecer».
Como resultado, existe una economía sumergida en línea para todo lo relacionado con las publicaciones académicas. Se venden autores, citas e incluso directores de revistas académicas. Este fraude es tan frecuente que tiene su propio nombre: «fábricas de artículos», una expresión que recuerda a las «fábricas de trabajos del curso», en las que los estudiantes hacen trampas consiguiendo que otra persona escriba un trabajo de clase por ellos.
El impacto en los editores es profundo. En los casos más sonados, los artículos falsos pueden perjudicar los resultados de una revista. Importantes índices científicos -bases de datos de publicaciones académicas en las que se basan muchos investigadores para realizar su trabajo- pueden excluir de la lista a las revistas que publiquen demasiados artículos dudosos. Cada vez se critica más que los editores legítimos podrían hacer más por rastrear y poner en la lista negra a las revistas y autores que publican regularmente artículos falsos que, a veces, son poco más que frases encadenadas generadas por inteligencia artificial.
El resultado es una crisis profundamente arraigada que ha llevado a muchos investigadores y responsables políticos a reclamar una nueva forma de evaluar y recompensar a académicos y profesionales de la salud en todo el mundo.
Al igual que los sitios web tendenciosos disfrazados de información objetiva están acabando con el periodismo basado en pruebas y amenazando las elecciones, la ciencia falsa está acabando con la base de conocimientos sobre la que se asienta la sociedad moderna.
El programa tiene como meta explorar un enfoque más justo y sostenible en los precios de acceso abierto (OA), considerando las diferencias económicas dentro de la región.
Wiley ha lanzado un programa piloto de precios con el objetivo de ofrecer opciones de publicación más equitativas para los investigadores en América Latina. Este programa, que comenzó el 21 de enero de 2025, proporciona descuentos en los costos de publicación (APC) para autores de 33 países de la región, incluidos México, Sudamérica y el Caribe. Los descuentos están basados en el Índice de Poder Adquisitivo (PPI) de cada país, utilizando datos del Programa de Comparación Internacional del Banco Mundial. El programa piloto, que tendrá una duración de 12 meses, incluye una revisión a medio término para ajustar las acciones futuras.
Además, Wiley sigue ofreciendo exenciones y descuentos a autores de países de Research4Life y mantiene acuerdos de acceso abierto con diversas instituciones de América Latina.
Trueblood, Jennifer S., et al. “The Misalignment of Incentives in Academic Publishing and Implications for Journal Reform.” Proceedings of the National Academy of Sciences of the United States of America 122, no. 5 (2025): e2401231121. https://www.pnas.org/doi/10.1073/pnas.2401231121
Se analiza el conflicto entre los dos principales objetivos de la publicación académica: la difusión del conocimiento y el reconocimiento científico. Aunque ambos pueden fomentar investigaciones profundas, la presión por maximizar métricas de publicación puede distorsionar las prioridades académicas. Los editores comerciales han aprovechado esta dinámica para obtener grandes beneficios, utilizando revisores no remunerados, estableciendo barreras económicas a la difusión de investigaciones y cobrando altas tarifas por el acceso abierto. El estudio explora modelos alternativos de publicación científica y plantea posibles reformas en la evaluación académica, señalando que el éxito de estos nuevos enfoques dependerá de su impacto en los actuales sistemas de acreditación, que priorizan métricas como citas e índices de impacto.
Strzelecki, Artur. «‘As of My Last Knowledge Update’: How is Content Generated by ChatGPT Infiltrating Scientific Papers Published in Premier Journals?» Learned Publishing 38, no. 1 (2025). https://doi.org/10.1002/leap.1650
El artículo examina cómo el contenido generado por ChatGPT aparece en artículos revisados por pares en revistas de prestigio sin ser declarado por los autores. Utilizando el método SPAR4SLR, se identificaron fragmentos generados por IA en publicaciones indexadas en bases de datos científicas
El uso no declarado de contenido generado por ChatGPT en artículos científicos es un problema emergente, con ejemplos de textos generados por IA que han pasado desapercibidos en revistas académicas de prestigio. Esto ha sido detectado en publicaciones como Resources Policy, Surfaces and Interfaces y Radiology Case Reports, que finalmente fueron retiradas. La falta de transparencia sobre el uso de IA en la creación de contenido científico plantea desafíos para el proceso de revisión por pares y la aceptación de manuscritos en revistas científicas.
Este artículo propone investigar cómo identificar los artículos parcialmente generados por ChatGPT, cómo se citan en otros trabajos y cómo responden los editores a este tipo de contenido. La investigación busca mejorar las políticas editoriales y la calidad de los artículos publicados, enfocándose no solo en correcciones lingüísticas, sino en la creación de contenido generado por IA.
A través de búsquedas en Google Scholar, se ha identificó contenido generado por ChatGPT mediante frases recurrentes que este modelo utiliza, como «as of my last knowledge update» y «I don’t have access to». Estas frases fueron inicialmente utilizadas para encontrar artículos que contenían texto generado por la IA. Además, se identificaron otros términos frecuentes como «regenerate response», que aparecían en artículos científicos sin justificación, señalando que el contenido había sido generado o manipulado por el modelo de IA.
Utilizando el método SPAR4SLR, comúnmente empleado en revisiones sistemáticas de literatura, el autor analizó artículos indexados en las bases de datos Web of Science y Scopus, identificando secciones que presentan indicios de haber sido creadas íntegramente por ChatGPT.
Los principales hallazgos del estudio son:
Presencia no declarada de contenido generado por IA: Se detectaron artículos en revistas de renombre que contienen material producido por modelos de lenguaje como ChatGPT, sin que los autores hayan reconocido su uso.
Citas académicas: Varios de estos artículos ya han sido citados en otras investigaciones publicadas en revistas indexadas, lo que amplifica la difusión de contenido generado por IA en la literatura científica.
Disciplinas afectadas: Aunque la mayoría de los artículos identificados pertenecen a las áreas de medicina e informática, también se encontraron en campos como ciencias ambientales, ingeniería, sociología, educación, economía y gestión.
La búsqueda identificó 1.362 artículos científicos en los que se confirma inequívocamente que porciones del texto fueron generadas por ChatGPT. La cantidad de artículos fue tal que podría realizarse un análisis manual, artículo por artículo. La mayoría de los resultados obtenidos por Google Scholar se vinculan con publicaciones de revistas no indexadas en bases de datos científicas de calidad como Web of Science y Scopus, o en plataformas que publican preprints, como arXiv, researchsquare, SSRN y otras. Sin embargo, una porción menor de los resultados pertenece a editores reconocidos como grandes publicadores científicos con gran influencia en los lectores. Muchos de los artículos identificados fueron publicados en revistas que están indexadas en las bases de datos Web of Science y Scopus y tienen indicadores de calidad como el Factor de Impacto y CiteScore derivados de la cantidad de citas.
El estudio subraya la necesidad de una discusión ética y metodológica sobre el uso de modelos de lenguaje como ChatGPT en la producción de trabajos académicos. La falta de transparencia en la utilización de estas herramientas puede comprometer la integridad científica y plantea interrogantes sobre la autoría y la originalidad en la investigación.
Este análisis invita a la comunidad académica a reflexionar sobre las implicaciones del uso de inteligencia artificial en la redacción científica y a establecer directrices claras que aseguren la transparencia y la calidad en las publicaciones.
Se analiza el impacto de Dialnet Métricas en la evaluación de la producción científica en Biblioteconomía y Documentación, destacando cómo combina métricas tradicionales y datos alternativos, como visualizaciones y recomendaciones. Además, se examinan las revistas de mayor impacto y los autores más citados en el campo, proporcionando una herramienta clave para medir la influencia académica en revistas en español.
Dialnet ha calculado las citas emitidas por 600 revistas en los últimos 5 años, considerando un total de 59.725 citas. Se incluyeron revistas internacionales para completar la cobertura global. La tasa de autorreferenciación es de 0,16, y el índice de coautoría en el ámbito de Documentación es de 1,9. A continuación, se presenta una tabla con las revistas más destacadas según su índice de impacto:
Revistas con mayor impacto en Dialnet Métricas 2023
La tabla muestra un conjunto de 24 revistas académicas destacadas en el campo de la documentación, clasificados según su índice de impacto en los últimos 5 años. Este índice refleja la relevancia y el reconocimiento de cada revista dentro de la comunidad académica, medido a través del número de citas recibidas y artículos publicados.
Índice de coautoría y tasa de autorreferenciación: El índice de coautoría en el campo de Documentación es de 1,9, lo que indica una colaboración significativa entre autores en estas revistas. Además, la tasa de autorreferenciación es baja (0,16), lo que sugiere que las revistas citan fuentes externas en lugar de autorreferirse excesivamente, lo cual es un signo positivo para la diversidad y calidad de las publicaciones.
Revistas de alto impacto: Las revistas más destacadas en la tabla son El profesional de la información (con un impacto de 2,75), seguida por Revista española de documentación científica (0,94) y Revista general de información y documentación (0,60). Estas revistas tienen un alto número de citas, lo que indica que son fuentes clave en el campo de la documentación.
Revistas especializadas: Otras publicaciones, como Anuario ThinkEPI (0,52) y Hipertext.net (0,48), aunque con un impacto ligeramente menor, siguen siendo relevantes y ofrecen contribuciones importantes, especialmente en temas de documentación digital y comunicación interactiva.
Revistas con menor impacto: Al final de la lista, encontramos revistas con un impacto de casi nulo, como Anuari de l’Observatori de Biblioteques, Llibres i Lectura y Mi biblioteca, que tienen un índice de impacto menor a 0,01. Esto podría deberse a un menor volumen de citas y a una cobertura más local o específica.
Diversidad en la cobertura: La tabla muestra una diversidad de enfoques, desde revistas más generales de biblioteconomía y documentación hasta publicaciones especializadas en áreas como patrimonio documental, sistemas de información y archivo. Esto refleja la variedad de temas que abarca el campo de la documentación.
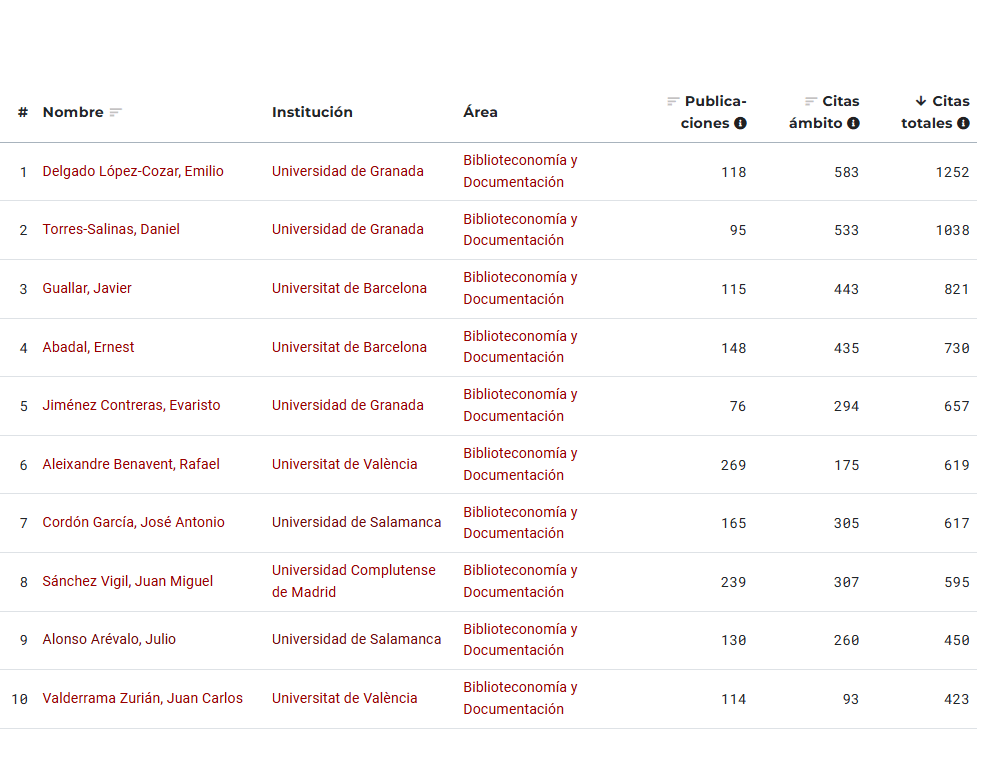
investigadores más citados en el ámbito de la Biblioteconomía y Documentación:
La tabla presenta un listado de investigadores clasificados por el número total de citas recibidas en publicaciones dentro del ámbito de la biblioteconomía y documentación. Además, se muestran las citas totales, las citas en el ámbito específico, y algunos índices como el Índice H y el Índice H5, que reflejan la productividad y el impacto de sus publicaciones a lo largo del tiempo.
Tabla de investigadores más citados:
Autores más citados en Biblioteconomía Documentación 2023
Estos 10 investigadores representan a las instituciones académicas más relevantes en el campo de la biblioteconomía y la documentación en España. La Universidad de Granada y la Universitat de Barcelona destacan como dos de las principales fuentes de investigación en este ámbito. Los altos índices de citas de estos investigadores demuestran no solo su producción académica, sino también la relevancia y el impacto de sus estudios dentro de la disciplina. Sin duda, sus trabajos han contribuido significativamente al avance del conocimiento en biblioteconomía y documentación, y siguen siendo fundamentales para las futuras investigaciones en este campo.
Emilio Delgado López-Cozar (Universidad de Granada):
Citas en ámbito: 583 Citas totales: 1252
Emilio Delgado López-Cózar es un destacado académico español en Biblioteconomía y Documentación, Catedrático en la Universidad de Granada. Su investigación se centra en la evaluación de la ciencia, la metodología de la investigación y las métricas científicas. Ha desarrollado sistemas para medir el rendimiento de revistas y científicos, y es conocido por su análisis de métricas alternativas. Su impacto académico es significativo, con miles de citas y un alto índice h.
Daniel Torres-Salinas (Universidad de Granada):
Citas en ámbito: 533 Citas totales: 1038
Daniel Torres-Salinas es un destacado académico de la Universidad de Granada, especializado en Biblioteconomía y Documentación, con enfoque en evaluación de la ciencia y Bibliometría. Su investigación abarca la evaluación de la investigación universitaria, libros científicos y nuevas métricas, con un impacto significativo reflejado en sus numerosas citas y publicaciones en revistas de prestigio.
Javier Guallar (Universitat de Barcelona):
Citas en ámbito: 443 Citas totales: 821
Javier Guallar. Es profesor e investigador en la Facultad de Información y Medios Audiovisuales de la Universidad de Barcelona, doctor en Información y Documentación por la UB y en Comunicación por la UPF. Especializado en curación de contenidos, es autor de libros y artículos sobre el tema, editor de colecciones académicas, y fue subdirector de la revista «El Profesional de la Información». También es conocido por su trabajo en evaluación de revistas científicas y por desarrollar el sistema de curación de contenidos de las 4S’s
Ernest Abadal (Universitat de Barcelona):
Citas en ámbito: 435 Citas totales: 730
Ernest Abadal es Catedrático de la Facultad de Información y Medios Audiovisuales de la Universitat de Barcelona y actualmente Vicerrector Adjunto al Rector y de PDI. Doctor en Ciencias de la Información, su investigación se centra en el acceso abierto, la ciencia abierta y las publicaciones digitales. Ha dirigido proyectos de investigación sobre acceso abierto a la ciencia en España y es coordinador del Grupo de Investigación Consolidado «Cultura y contenidos digitales». Es autor de numerosas publicaciones y ha ocupado diversos cargos académicos y de gestión en la UB.
Evaristo Jiménez Contreras (Universidad de Granada):
Citas en ámbito: 294 Citas totales: 657
Evaristo Jiménez Contreras es Catedrático de Bibliometría en la Universidad de Granada y miembro del grupo de investigación EC3. Su trayectoria se centra en la evaluación de la ciencia, bibliometría y comunicación científica. Ha dirigido numerosas tesis doctorales sobre análisis bibliométricos en diversas disciplinas. Es autor de publicaciones influyentes sobre la evolución de la actividad investigadora en España y el impacto de las políticas de evaluación.
Rafael Aleixandre Benavent (Universitat de València):
Citas en ámbito: 175 Citas totales: 619
Rafael Aleixandre Benavent es investigador vinculado al Consejo Superior de Investigaciones Científicas (CSIC) y a la Universidad de Valencia. Su trabajo se centra en bibliometría, informetría, cienciometría y evaluación de la investigación. Es autor de numerosas publicaciones sobre comunicación científica, análisis bibliométricos y evaluación del impacto científico
José Antonio Cordón García (Universidad de Salamanca):
Citas en ámbito: 305 Citas totales: 617
José Antonio Cordón García es Catedrático de la Universidad de Salamanca, especializado en Biblioteconomía y Documentación. Su investigación se centra en fuentes de información, industria editorial, historia del libro y lectura digital. Dirige el Grupo de Investigación E-LECTRA y el Máster en Patrimonio Textual y Humanidades Digitales. Ha recibido el Premio Nacional de Investigación 2012 en Edición y Sociedad del Conocimiento, y ha publicado extensamente sobre edición y lectura digital
Juan Miguel Sánchez Vigil (Universidad Complutense de Madrid):
Citas en ámbito: 307 Citas totales: 595
Juan Miguel Sánchez Vigil es Catedrático de la Universidad Complutense de Madrid, especializado en Documentación Fotográfica y Editorial. Doctor en Ciencias de la Información, Historia del Arte y Geografía e Historia, ha ocupado cargos de gestión académica. Su investigación se centra en fotografía, edición y documentación, con numerosas publicaciones y dirección de tesis doctorales. Es editor, fotógrafo y documentalista gráfico, y ha recibido reconocimientos por su labor en el campo de la edición y la sociedad del conocimiento.
Julio Alonso Arévalo (Universidad de Salamanca):
Citas en ámbito: 260 Citas totales: 450
Julio Alonso Arévalo es bibliotecario responsable de la Biblioteca de Traducción y Documentación de la Universidad de Salamanca. Licenciado en Geografía e Historia, es experto en acceso abierto y edición digital. Es editor del repositorio E-LIS, coordinador de la lista InfoDoc y creador del blog «Universo abierto». Ha publicado sobre e-books, gestión del conocimiento y nuevas tecnologías en bibliotecas, recibiendo el Premio Nacional de Investigación en Edición y Sociedad de la Información en España en 2013.
Juan Carlos Valderrama Zurián (Universitat de València):
Citas en ámbito: 93 Citas totales: 423
Juan Carlos Valderrama Zurián es Doctor en Medicina y Profesor Titular de la Facultad de Medicina en la Universitat de València. Su investigación se centra en drogodependencias, gestión del conocimiento y estudios epidemiológicos, con énfasis en población inmigrante, abuso de esteroides y prevención de VIH/VHC. Ha publicado numerosos artículos en revistas nacionales e internacionales sobre adicciones y bibliometría. Actualmente lidera el proyecto DATAUSE UV, enfocado en la gestión y transferencia del conocimiento emergente.
Gemma Conroy, «How ChatGPT and Other AI Tools Could Disrupt Scientific Publishing», Nature 622, n.o 7982 (10 de octubre de 2023): 234-36, https://doi.org/10.1038/d41586-023-03144-w.
La inteligencia artificial generativa tiene el potencial de transformar profundamente la publicación científica, pero su integración debe gestionarse cuidadosamente. Solo a través de un enfoque responsable y ético será posible maximizar sus beneficios mientras se mitigan los riesgos asociados.
Las herramientas de inteligencia artificial generativa, como ChatGPT, están revolucionando la publicación científica al transformar la forma en que se redactan y revisan manuscritos, informes de revisión por pares y solicitudes de subvenciones. Estas herramientas ofrecen beneficios significativos, como mayor eficiencia y equidad, pero también plantean preocupaciones relacionadas con la precisión, la ética y la calidad de las publicaciones. Por ejemplo, investigadores no nativos en inglés pueden superar barreras lingüísticas con la ayuda de estas tecnologías, mientras que el tiempo necesario para redactar documentos se reduce considerablemente. Sin embargo, estas mismas herramientas presentan riesgos asociados a inexactitudes y posibles usos indebidos.
Uno de los mayores cambios que trae la inteligencia artificial es la posible transformación del formato de los artículos científicos. En el futuro, los artículos podrían presentarse como documentos interactivos que permiten al lector explorar los datos y resultados de manera personalizada, en lugar de depender de los formatos estáticos actuales. Asimismo, la IA podría facilitar la realización de meta-análisis más amplios y detallados al procesar grandes volúmenes de literatura científica, algo que excede las capacidades humanas tradicionales. Esto abriría nuevas posibilidades para descubrir patrones y tendencias en la investigación.
No obstante, el uso de herramientas de IA generativa no está exento de riesgos. Estas tecnologías, al basarse en patrones más que en la verificación de hechos, pueden generar errores, referencias falsas o incluso artículos fraudulentos. Además, su accesibilidad podría fomentar prácticas poco éticas, como la proliferación de “fábricas de artículos”, donde se crean y venden manuscritos o posiciones de autoría. Por otro lado, las herramientas actuales para detectar textos generados por IA no son lo suficientemente fiables, lo que dificulta la identificación de fraudes y plantea un desafío significativo para los editores y revisores.
En el ámbito ético, el desarrollo de estas tecnologías también genera preocupaciones sobre plagio y derechos de autor. Muchos modelos de IA se entrenan con datos recopilados de Internet sin garantizar el consentimiento ni respetar restricciones de uso, lo que ha llevado a críticas que describen a la IA generativa como “plagio automatizado”. Además, las preocupaciones sobre la confidencialidad en la revisión por pares han llevado a algunas instituciones a prohibir el uso de estas herramientas en procesos sensibles como la evaluación de becas.
La equidad es otro aspecto clave. Mientras que herramientas como ChatGPT podrían nivelar el campo de juego para investigadores que no hablan inglés como lengua nativa, la posible monetización de estas tecnologías podría limitar su acceso a científicos de instituciones con menos recursos. Esto podría agravar las desigualdades ya existentes en la academia, especialmente si las herramientas avanzadas se vuelven prohibitivamente caras.
Para abordar estos desafíos, es esencial equilibrar la innovación con la integridad. Las revistas científicas deben establecer directrices claras sobre el uso de la IA, mientras que los gobiernos y las instituciones deben regular su implementación para garantizar una adopción ética y equitativa. Por su parte, los investigadores deben mantener habilidades críticas en redacción y análisis para no depender exclusivamente de estas herramientas en un entorno académico en rápida evolución.
Con el aumento de la popularidad de la inteligencia artificial generativa (IA), varios editores académicos han establecido acuerdos con empresas tecnológicas que buscan utilizar contenido académico para entrenar los grandes modelos de lenguaje (LLMs) que sustentan sus herramientas de IA. Estos acuerdos han resultado altamente lucrativos, generando millones de dólares para los editores involucrados.
Roger Schonfeld, co-creador de un nuevo rastreador de acuerdos y vicepresidente de bibliotecas, comunicación académica y museos en Ithaka S+R, una firma de consultoría en educación superior con sede en Nueva York, comenta: “Estábamos observando anuncios de estos acuerdos y comenzamos a pensar que esto está empezando a convertirse en un patrón”. Schonfeld y su equipo lanzaron en octubreGenerative AI Licensing Agreement Tracker, una herramienta destinada a recoger los acuerdos que se están realizando entre editores y compañías de tecnología.
El rastreador tiene como objetivo no solo documentar cada acuerdo individual, sino también identificar y analizar las tendencias generales que emergen de estos acuerdos. Al proporcionar una fuente centralizada de información, el tracker facilita que la comunidad académica y tecnológica comprendan mejor cómo se está utilizando el contenido académico para el desarrollo de IA generativa.
Este fenómeno refleja una creciente intersección entre la publicación académica y el desarrollo de tecnologías avanzadas de IA. Los editores, al vender derechos de uso de sus artículos para entrenar modelos de lenguaje, están aprovechando nuevas oportunidades de ingresos, mientras que las empresas de tecnología aseguran el acceso a vastas cantidades de datos necesarios para mejorar la precisión y capacidad de sus sistemas de IA.
El seguimiento de estos acuerdos es crucial para mantener la transparencia en cómo se utiliza el contenido académico y para asegurar que se respeten los derechos de los autores y las instituciones educativas. Además, este rastreador puede ayudar a identificar posibles implicaciones éticas y legales relacionadas con el uso de investigaciones académicas en el entrenamiento de inteligencias artificiales.
Principales acuerdos:
Taylor & Francis firmó un acuerdo de 10 millones de dólares con Microsoft
Wiley generó 23 millones de dólares en un acuerdo con una empresa no revelada y espera otros 21 millones este año.
Otros grandes editores, como Elsevier y Springer Nature, no han comentado sobre acuerdos similares.
También los editores están creando nuevas posiciones y programas, como el «Wiley AI Partnerships», para formalizar colaboraciones con empresas de tecnología. Esto refleja que estos acuerdos no son excepcionales, sino parte de una estrategia a largo plazo.
Los acuerdos entre editores académicos y empresas de IA están transformando la publicación científica, generando ingresos sustanciales y redefiniendo la relación entre autores, editores y tecnología. Sin embargo, el debate sobre la transparencia y las implicaciones éticas de estas prácticas sigue abierto.
Algunos académicos han mostrado preocupación por el uso de su contenido sin su conocimiento.
De Gruyter Brill creó una página informativa para explicar los acuerdos y abordar las inquietudes de los autores.
Cambridge University Press & Assessment adoptó un enfoque de participación voluntaria, contactando a 20.000 autores para obtener su consentimiento explícito.