Mohan, Deepanshu. “In a Ranking-Obsessed System, What Exactly Are Universities Measuring?” The Wire, marzo 2025. https://thewire.in/education/ranking-universities-education-system-research
En la educación superior actual, los rankings universitarios globales, como los QS World University Rankings by Subject, han dejado de ser simples clasificaciones para convertirse en herramientas de gran influencia. Estos rankings moldean percepciones, guían decisiones políticas y afectan tanto la elección de los estudiantes como las prioridades de inversión de los gobiernos.
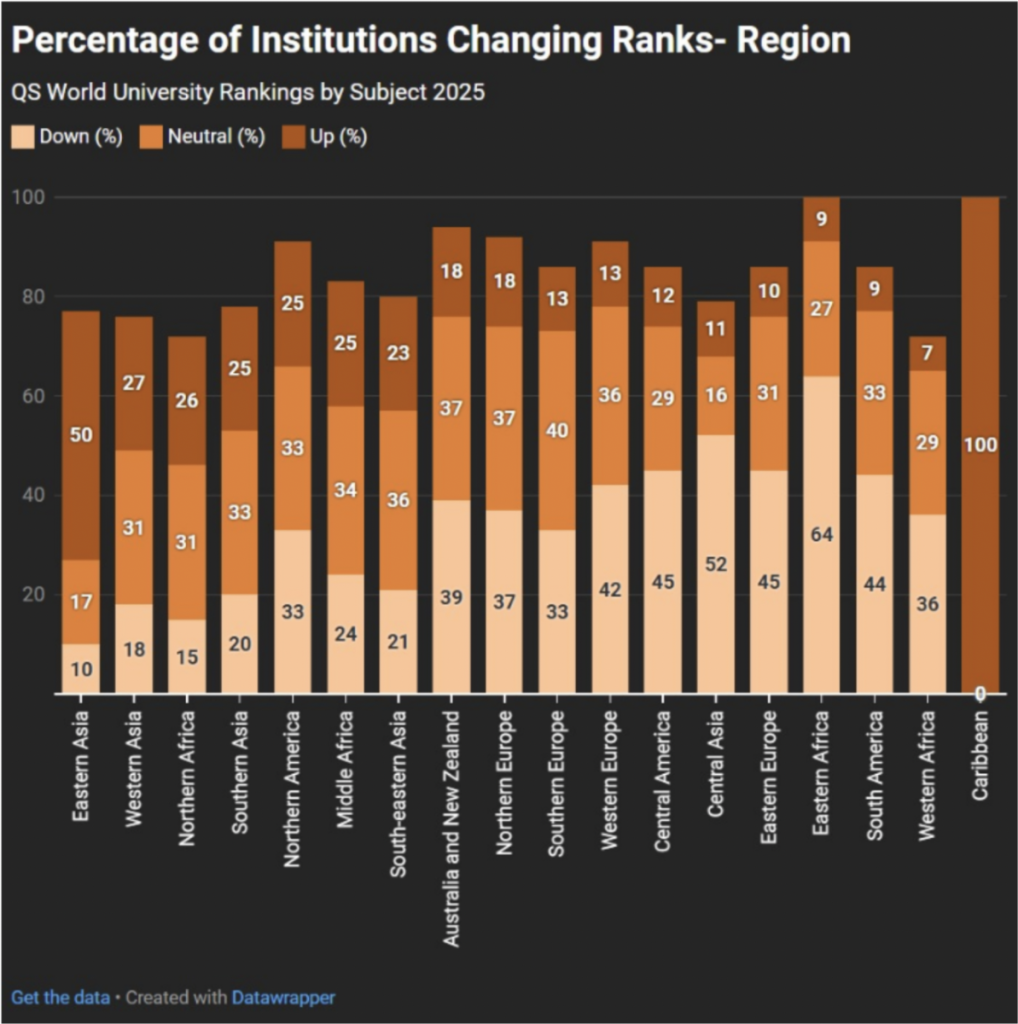
La edición de 2025 de los QS Rankings by Subject, publicada el 12 de marzo, evaluó más de 55 disciplinas en cinco grandes áreas del conocimiento, lo que refleja la creciente especialización académica. Se incorporaron 171 nuevas instituciones, evidenciando una expansión significativa, sobre todo en áreas estratégicas como medicina, ciencias de la computación y ciencia de materiales. Por ejemplo, las universidades clasificadas en informática pasaron de 601 en 2020 a 705 en 2024. Este crecimiento no solo revela un mayor interés académico, sino también una fuerte competencia entre universidades por visibilidad y prestigio en sectores con alto potencial de financiación e innovación.
Se cuestiona si los rankings realmente miden mérito académico o si premian a quienes mejor entienden y manipulan su lógica. En países como Arabia Saudita o Singapur, se observa un crecimiento desproporcionado en la reputación académica sin una mejora equivalente en las citas, lo que sugiere posibles prácticas de gestión reputacional poco éticas.
Fuente: Clasificación Mundial de Universidades QS por Materias 2025
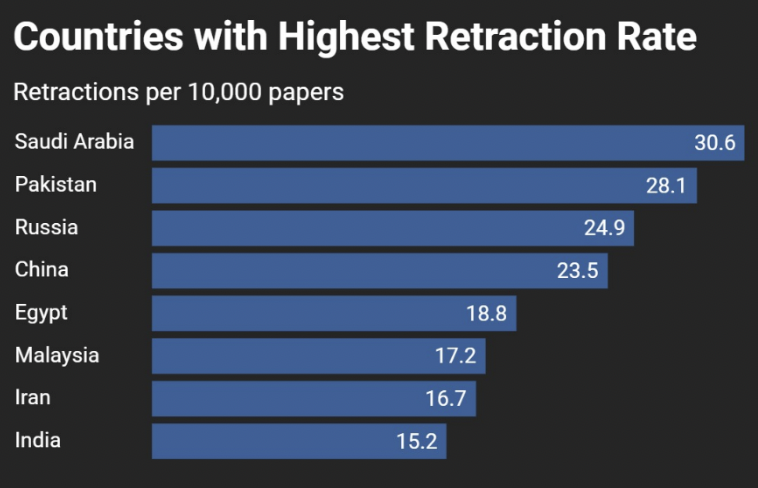
Se ha identificado una correlación preocupante entre el aumento de publicaciones y el incremento en retracciones de artículos científicos, especialmente en países como China, India, Pakistán, Arabia Saudita, Egipto e Irán. Esto sugiere que la presión por publicar y escalar posiciones ha conducido en algunos casos a malas prácticas científicas como la fabricación o duplicación de resultados. Arabia Saudita, por ejemplo, duplicó su producción científica entre 2019 y 2024, pero también registró un fuerte aumento en retracciones. En India, la producción aumentó más de un 56% en cinco años, pero también se han visto afectadas por problemas de calidad y control.
Fuente: Número total de trabajos de investigación según Scopus: artículos y revisiones.
Se destaca el ascenso de instituciones de Asia Occidental y países árabes como Arabia Saudita, Emiratos Árabes Unidos y Catar, gracias a inversiones en I+D. Sin embargo, también se cuestiona si este progreso refleja mejoras reales o estrategias diseñadas para escalar en el ranking, como el aumento artificial de citaciones o encuestas de reputación manipuladas.
India ha sido uno de los países con mayor crecimiento en los rankings globales, especialmente en áreas STEM (ciencia, tecnología, ingeniería y matemáticas). Este ascenso se ha vinculado a políticas como la iniciativa Institutions of Eminence (IoE), que busca crear universidades de élite. Sin embargo, esta estrategia ha generado críticas por concentrar recursos en pocas instituciones, mientras muchas universidades estatales sufren abandono, falta de financiación y precariedad.
Los rankings se basan ahora en indicadores como la reputación académica (40 %), la reputación entre empleadores (10 %), las citas de investigación por artículo (20 %) y el índice H (20 %), respaldados además por la puntuación de la red internacional de investigación. Uno de los problemas principales es que el QS otorga casi el 50% del peso a encuestas de reputación académica y empresarial, lo que deja margen para maniobras estratégicas de autopromoción institucional y visibilidad controlada. A esto se suma el fenómeno de las “citas en anillo” y la contratación de académicos con alta visibilidad para inflar métricas.
Además, estos rankings influyen profundamente en la formulación de políticas educativas, especialmente en economías emergentes. Estar en el top 200 puede significar más financiación, mayor atracción de estudiantes internacionales y prestigio diplomático. Sin embargo, esta influencia genera comportamientos orientados a mejorar la posición en rankings antes que a desarrollar auténtica calidad educativa.
En conclusión, los rankings como QS y THE, aunque útiles para comparaciones internacionales, también pueden ser engañosos. Favorecen la visibilidad y los indicadores cuantitativos sobre la calidad docente, el compromiso social o la equidad. La carrera por ascender en estas clasificaciones puede fomentar reformas superficiales y cosméticas, en lugar de una transformación estructural del sistema educativo.