Aaron Tay. “AI Academic Search and the Missing Benchmark Problem”. Aaron Tay’s Musings about Librarianship, 2026.
Uno de los problemas más importantes en la evaluación de los sistemas de búsqueda académica basados en inteligencia artificial: la ausencia de estándares de referencia sólidos y compartidos. Mientras proliferan herramientas como Elicit, Consensus, Scite, Scopus AI o los sistemas de “Deep Research”, existe una gran dificultad para determinar objetivamente cuál de ellas ofrece mejores resultados, ya que no disponemos de benchmarks ampliamente aceptados que permitan comparar su rendimiento de forma rigurosa.
Tay señala que la situación recuerda a los primeros años de otros campos de la inteligencia artificial, donde los avances tecnológicos fueron más rápidos que los mecanismos de evaluación. Muchas plataformas promocionan capacidades como la búsqueda semántica, la recuperación aumentada por generación (RAG), la identificación automática de literatura relevante o la elaboración de revisiones bibliográficas asistidas por IA. Sin embargo, los usuarios suelen disponer únicamente de demostraciones comerciales o ejemplos seleccionados por los propios desarrolladores, lo que dificulta conocer el rendimiento real de estas herramientas en contextos de investigación auténticos.
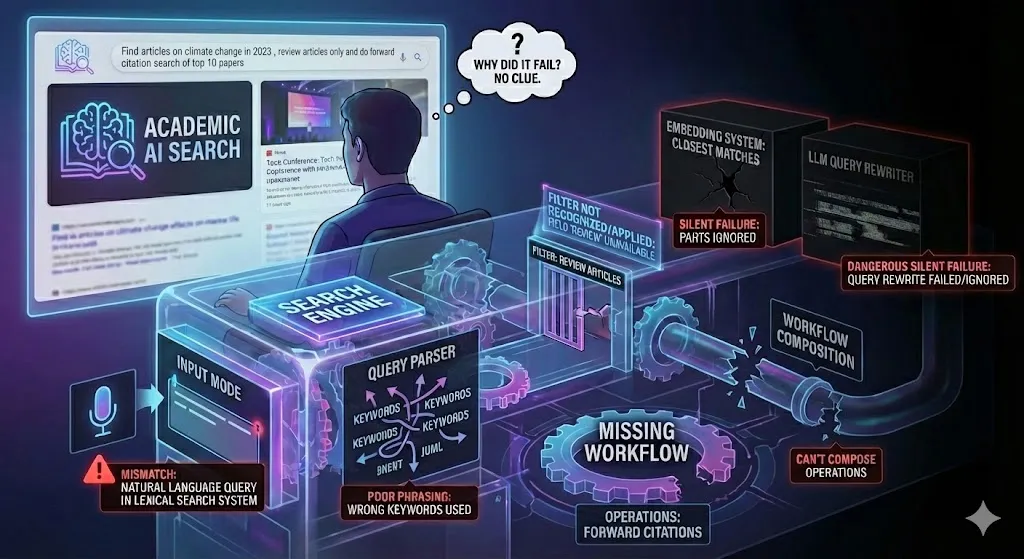
Uno de los argumentos centrales del autor es que la búsqueda académica constituye un problema mucho más complejo que responder preguntas generales. No basta con recuperar documentos relacionados; también es necesario encontrar trabajos relevantes aunque utilicen terminología diferente, identificar literatura seminal, reconocer relaciones de citación y ofrecer resultados adecuados para distintas etapas del proceso investigador. Debido a ello, evaluar únicamente la precisión de una respuesta generada por IA resulta insuficiente.
El artículo destaca además que muchas pruebas actuales se centran en tareas demasiado simples. Un sistema puede responder correctamente a preguntas factuales concretas y aun así fracasar cuando se enfrenta a necesidades reales de investigación, como localizar artículos fundamentales omitidos en una revisión bibliográfica, detectar debates emergentes o construir estrategias de búsqueda exhaustivas. Tay sostiene que los escenarios de evaluación deberían reflejar mejor las tareas cotidianas de investigadores, estudiantes y bibliotecarios.
Otro problema importante es la falta de transparencia. Muchas herramientas académicas basadas en IA funcionan mediante modelos propietarios cuyos índices documentales, algoritmos de recuperación y mecanismos de clasificación no son públicos. Como consecuencia, resulta difícil reproducir experimentos o comprender por qué dos sistemas ofrecen resultados distintos ante la misma consulta. Esta opacidad limita la posibilidad de desarrollar evaluaciones comparables y acumulativas.
Tay también subraya que la calidad de un sistema RAG depende de dos componentes distintos: la recuperación de información y la generación de respuestas. Un modelo puede producir un texto aparentemente convincente pero basado en documentos poco relevantes, o bien recuperar excelentes artículos y resumirlos de forma deficiente. Por ello, propone evaluar por separado la capacidad de recuperación y la fidelidad de la síntesis generada.
En sus análisis previos sobre herramientas de búsqueda académica, el autor ha mostrado que algunos sistemas especializados fracasan en tareas relativamente sencillas para un investigador humano, mientras que modelos generales pueden resolverlas con más eficacia. Estos resultados sugieren que muchas plataformas funcionan mediante flujos de trabajo predefinidos que son muy eficaces en determinados escenarios, pero menos flexibles cuando la consulta se aparta de los casos previstos por sus diseñadores.
El texto conecta además con una cuestión más amplia dentro de la inteligencia artificial: la importancia de los benchmarks. Históricamente, disciplinas como el procesamiento del lenguaje natural o la visión artificial han avanzado gracias a conjuntos de pruebas estandarizados que permiten comparar sistemas bajo condiciones comunes. Sin estándares equivalentes para la búsqueda académica asistida por IA, resulta difícil distinguir entre mejoras reales y simples estrategias de marketing.
Aaron Tay defiende la necesidad de construir marcos de evaluación abiertos, transparentes y orientados a tareas reales de investigación. Solo mediante benchmarks compartidos será posible determinar qué herramientas mejoran verdaderamente el descubrimiento académico y cuáles simplemente generan respuestas convincentes. Para bibliotecarios, investigadores y responsables institucionales, esta cuestión resulta especialmente relevante en un momento en que las plataformas de búsqueda basadas en IA comienzan a integrarse en bases de datos científicas, catálogos bibliotecarios y servicios de apoyo a la investigación.