Google está realizando cambios importantes en su experiencia de búsqueda. En lugar de ofrecer la lista de enlaces habitual que ha existido durante décadas, las consultas a veces dirigirán a los usuarios a una interfaz interactiva con IA donde podrán interactuar directamente con las respuestas y hacer preguntas adicionales. Estas actualizaciones también implementarán nuevos formatos publicitarios, incluyendo anuncios con funciones de IA que permiten a los usuarios interactuar con ellos.
Muchos estadounidenses ya encuentran resúmenes generados por IA en sus resultados de búsqueda, pero las opiniones sobre su utilidad son diversas. En agosto pasado, una encuesta del Pew Research Center reveló que el 65% de los adultos estadounidenses (incluida una mayoría aún mayor de adultos jóvenes) afirmó haber visto estos resúmenes al menos en alguna ocasión. Entre quienes habían visto resúmenes de búsqueda con IA, uno de cada cinco afirmó que los consideraba extremadamente o muy útiles, y el 6% dijo confiar mucho en la información de estos resúmenes.
Los motores de búsqueda como Google son una forma común en que muchos estadounidenses se informan: el 63% de los adultos estadounidenses afirma informarse de esta manera al menos en ocasiones.
Google anunció en su conferencia anual Google I/O 2026 la mayor transformación de su buscador desde su lanzamiento hace más de veinticinco años. Según la compañía, la era de los tradicionales “diez enlaces azules” está llegando a su fin para dar paso a una experiencia impulsada por inteligencia artificial, donde las respuestas, las interacciones y las acciones ocuparán un lugar mucho más importante que la simple lista de resultados web.
El cambio gira en torno a una nueva “caja de búsqueda inteligente”, diseñada para que los usuarios formulen preguntas largas y complejas de manera conversacional. En lugar de obligar a las personas a buscar mediante palabras clave, el sistema interpreta intenciones, sugiere consultas más sofisticadas y mantiene conversaciones de seguimiento sin que el usuario tenga que reformular constantemente su pregunta. La búsqueda se convierte así en un diálogo continuo con la inteligencia artificial.
Uno de los aspectos más innovadores es la incorporación de agentes de información. Estos asistentes pueden trabajar en segundo plano las veinticuatro horas del día, rastreando cambios en la web, recopilando datos y notificando al usuario cuando se cumplen determinadas condiciones. Por ejemplo, podrán vigilar movimientos financieros, seguir la evolución de un mercado específico o monitorizar cualquier tema de interés para proporcionar actualizaciones sintetizadas y contextualizadas. Esta funcionalidad supone una evolución significativa respecto a herramientas anteriores como Google Alerts.
La inteligencia artificial también permitirá que los resultados de búsqueda adopten la forma de experiencias interactivas. Gracias a técnicas de interfaz generativa, Search podrá construir visualizaciones, simulaciones, paneles de información y herramientas personalizadas adaptadas a cada consulta. Una búsqueda sobre agujeros negros, por ejemplo, podría convertirse en una representación gráfica interactiva que responda dinámicamente a nuevas preguntas formuladas por el usuario.
Otra novedad destacada es la posibilidad de crear pequeñas aplicaciones personalizadas directamente desde el buscador. Mediante instrucciones en lenguaje natural, los usuarios podrán desarrollar herramientas adaptadas a sus necesidades concretas, como planificadores de comidas, aplicaciones de seguimiento deportivo o gestores de proyectos personales. Google deja entrever una visión en la que la búsqueda deja de ser únicamente una herramienta para encontrar información y pasa a convertirse en una plataforma para realizar tareas y tomar decisiones.
Esta transformación se apoya en la integración de los modelos Gemini y de la plataforma Antigravity, desarrollada por Google para aplicaciones autónomas basadas en IA. La compañía afirma que la nueva experiencia será gratuita para todos los usuarios, aunque algunas funciones avanzadas relacionadas con agentes inteligentes y aplicaciones personalizadas llegarán inicialmente a los suscriptores de los planes Google AI Pro y Ultra.
Sin embargo, el anuncio también ha despertado preocupación entre medios de comunicación, creadores de contenidos y editores digitales. Al proporcionar respuestas completas dentro del propio buscador, los usuarios tendrán menos necesidad de visitar las páginas originales donde se encuentra la información. Diversos analistas advierten de que esta tendencia podría reducir aún más el tráfico web hacia los sitios de noticias, blogs y otros recursos en línea, agravando un problema que ya comenzó con la introducción de los resúmenes automáticos AI Overviews.
Las reacciones en comunidades tecnológicas han sido encontradas. Mientras algunos usuarios valoran la rapidez y comodidad de obtener respuestas directas, otros temen una creciente concentración del control de la información en manos de una única empresa. También se plantean interrogantes sobre la sostenibilidad económica de la web abierta, ya que muchos sitios dependen de las visitas generadas por los motores de búsqueda tradicionales.
Uno de los problemas más importantes en la evaluación de los sistemas de búsqueda académica basados en inteligencia artificial: la ausencia de estándares de referencia sólidos y compartidos. Mientras proliferan herramientas como Elicit, Consensus, Scite, Scopus AI o los sistemas de “Deep Research”, existe una gran dificultad para determinar objetivamente cuál de ellas ofrece mejores resultados, ya que no disponemos de benchmarks ampliamente aceptados que permitan comparar su rendimiento de forma rigurosa.
Tay señala que la situación recuerda a los primeros años de otros campos de la inteligencia artificial, donde los avances tecnológicos fueron más rápidos que los mecanismos de evaluación. Muchas plataformas promocionan capacidades como la búsqueda semántica, la recuperación aumentada por generación (RAG), la identificación automática de literatura relevante o la elaboración de revisiones bibliográficas asistidas por IA. Sin embargo, los usuarios suelen disponer únicamente de demostraciones comerciales o ejemplos seleccionados por los propios desarrolladores, lo que dificulta conocer el rendimiento real de estas herramientas en contextos de investigación auténticos.
Uno de los argumentos centrales del autor es que la búsqueda académica constituye un problema mucho más complejo que responder preguntas generales. No basta con recuperar documentos relacionados; también es necesario encontrar trabajos relevantes aunque utilicen terminología diferente, identificar literatura seminal, reconocer relaciones de citación y ofrecer resultados adecuados para distintas etapas del proceso investigador. Debido a ello, evaluar únicamente la precisión de una respuesta generada por IA resulta insuficiente.
El artículo destaca además que muchas pruebas actuales se centran en tareas demasiado simples. Un sistema puede responder correctamente a preguntas factuales concretas y aun así fracasar cuando se enfrenta a necesidades reales de investigación, como localizar artículos fundamentales omitidos en una revisión bibliográfica, detectar debates emergentes o construir estrategias de búsqueda exhaustivas. Tay sostiene que los escenarios de evaluación deberían reflejar mejor las tareas cotidianas de investigadores, estudiantes y bibliotecarios.
Otro problema importante es la falta de transparencia. Muchas herramientas académicas basadas en IA funcionan mediante modelos propietarios cuyos índices documentales, algoritmos de recuperación y mecanismos de clasificación no son públicos. Como consecuencia, resulta difícil reproducir experimentos o comprender por qué dos sistemas ofrecen resultados distintos ante la misma consulta. Esta opacidad limita la posibilidad de desarrollar evaluaciones comparables y acumulativas.
Tay también subraya que la calidad de un sistema RAG depende de dos componentes distintos: la recuperación de información y la generación de respuestas. Un modelo puede producir un texto aparentemente convincente pero basado en documentos poco relevantes, o bien recuperar excelentes artículos y resumirlos de forma deficiente. Por ello, propone evaluar por separado la capacidad de recuperación y la fidelidad de la síntesis generada.
En sus análisis previos sobre herramientas de búsqueda académica, el autor ha mostrado que algunos sistemas especializados fracasan en tareas relativamente sencillas para un investigador humano, mientras que modelos generales pueden resolverlas con más eficacia. Estos resultados sugieren que muchas plataformas funcionan mediante flujos de trabajo predefinidos que son muy eficaces en determinados escenarios, pero menos flexibles cuando la consulta se aparta de los casos previstos por sus diseñadores.
El texto conecta además con una cuestión más amplia dentro de la inteligencia artificial: la importancia de los benchmarks. Históricamente, disciplinas como el procesamiento del lenguaje natural o la visión artificial han avanzado gracias a conjuntos de pruebas estandarizados que permiten comparar sistemas bajo condiciones comunes. Sin estándares equivalentes para la búsqueda académica asistida por IA, resulta difícil distinguir entre mejoras reales y simples estrategias de marketing.
Aaron Tay defiende la necesidad de construir marcos de evaluación abiertos, transparentes y orientados a tareas reales de investigación. Solo mediante benchmarks compartidos será posible determinar qué herramientas mejoran verdaderamente el descubrimiento académico y cuáles simplemente generan respuestas convincentes. Para bibliotecarios, investigadores y responsables institucionales, esta cuestión resulta especialmente relevante en un momento en que las plataformas de búsqueda basadas en IA comienzan a integrarse en bases de datos científicas, catálogos bibliotecarios y servicios de apoyo a la investigación.
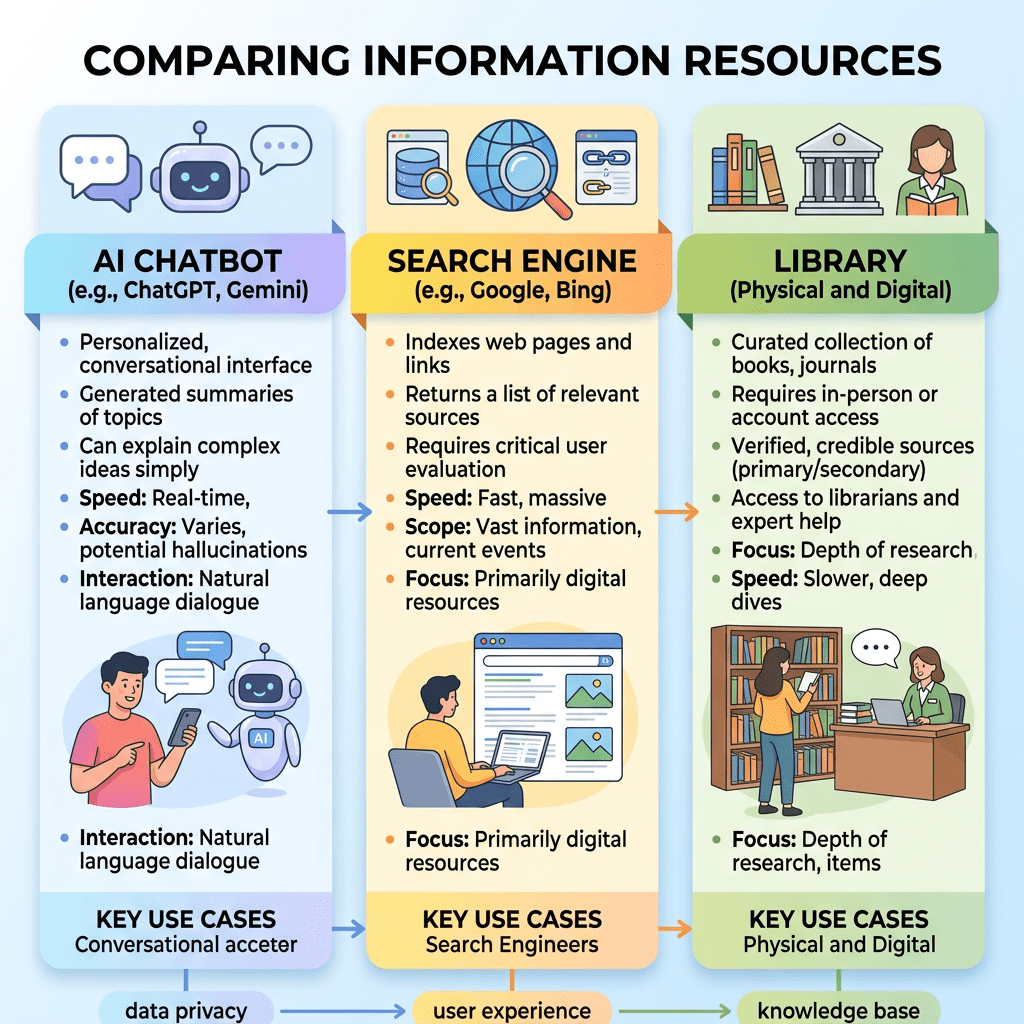
An infographic comparing AI chatbots, search engines, and libraries as information resources.
Lund, Brady D., Zoe Abbie Teel, Ting Wang, et al. “Artificial Intelligence (AI) and Information Seeking: A Comparative Exploration of AI Chatbots, Search Engines, and Library Resources as Information Sources among University Students.” Journal of Librarianship and Information Science (OnlineFirst, 2026). https://doi.org/10.1177/09610006261438484
El artículo retrata un momento de transición en el ecosistema informativo universitario. La IA no ha desplazado a Google ni a las bibliotecas, pero ya se ha incorporado de forma visible a las rutinas académicas. Su papel es complementario, aunque en expansión, especialmente entre estudiantes jóvenes e internacionales. Para las bibliotecas y universidades, el reto no consiste en resistirse al cambio, sino en liderarlo: integrar la IA de forma ética, crítica y conectada con recursos académicos de calidad.
Este estudio analiza cómo los estudiantes universitarios de Estados Unidos están integrando la inteligencia artificial generativa en sus prácticas de búsqueda académica. A partir de una encuesta electrónica respondida por 236 estudiantes de perfiles diversos, los autores comparan el uso, preferencia y satisfacción con tres grandes fuentes de información: motores de búsqueda tradicionales (como Google), recursos bibliotecarios universitarios y herramientas de IA conversacional como ChatGPT. El trabajo parte de la idea de que la irrupción de la IA está modificando profundamente la ecología informacional en la educación superior, alterando la manera en que los estudiantes localizan, evalúan y utilizan información.
Los resultados muestran que los motores de búsqueda siguen siendo la herramienta dominante para tareas académicas, tanto por frecuencia de uso como por preferencia inicial al comenzar una investigación. Casi la mitad de los estudiantes indicaron que Google o buscadores similares son su primera opción, mientras que el resto se divide entre los recursos de biblioteca y la IA. Sin embargo, la IA ya ocupa un lugar significativo: solo un 15% declaró no haberla usado nunca para fines académicos, mientras que cerca del 10% la utiliza diariamente. Esto indica que la IA no ha sustituido aún a las herramientas tradicionales, pero sí se ha convertido en una pieza estable del repertorio informacional estudiantil.
Uno de los hallazgos más relevantes es la existencia de diferencias demográficas marcadas. Los estudiantes más jóvenes muestran mayor inclinación hacia la IA como punto de partida en sus búsquedas, mientras que los mayores prefieren claramente las páginas web de bibliotecas universitarias. Asimismo, los estudiantes internacionales utilizan la IA con mucha mayor frecuencia que los estudiantes nacionales estadounidenses. De hecho, recurren menos a los recursos bibliotecarios y más a herramientas de IA, lo que los autores interpretan como posible consecuencia de barreras idiomáticas, desconocimiento del entorno bibliotecario estadounidense o búsqueda de interfaces más accesibles y conversacionales.
En cuanto a la percepción de calidad, los buscadores tradicionales siguen obteniendo mejores puntuaciones globales que la IA en relevancia y satisfacción de resultados. Los estudiantes consideran especialmente eficaces a los buscadores para noticias recientes, meteorología e información laboral. En cambio, la IA obtiene valoraciones más competitivas cuando se trata de ayuda académica, preparación de exámenes, comprensión inicial de un tema o generación de instrucciones para realizar tareas. Esto sugiere que los usuarios perciben fortalezas diferenciadas: el buscador como herramienta de acceso a fuentes actualizadas y múltiples perspectivas, y la IA como asistente para sintetizar, orientar o explicar.
El estudio también demuestra una relación clara entre uso frecuente y satisfacción con la IA. Cuanto más emplea un estudiante estas herramientas, mayor es su percepción de utilidad. Los usuarios intensivos valoran especialmente la IA para tareas educativas, estudio y resolución de procedimientos. Esto puede indicar un aprendizaje progresivo del uso eficaz de la herramienta o una adaptación de expectativas a sus capacidades reales. Los autores advierten, no obstante, que esta relación también podría fomentar dependencia acrítica si los estudiantes aceptan respuestas sintéticas sin contrastarlas con fuentes primarias.
Desde la perspectiva bibliotecaria, el artículo plantea implicaciones estratégicas de gran interés. Las bibliotecas universitarias no deberían contemplar la IA únicamente como una amenaza competitiva, sino como una oportunidad para rediseñar sus servicios. Proponen desarrollar sistemas de descubrimiento apoyados en IA conectados directamente con colecciones licenciadas, bases de datos y contenidos académicos fiables. De este modo, las bibliotecas podrían ofrecer experiencias conversacionales semejantes a ChatGPT, pero sustentadas en recursos evaluados y legales. También subrayan la necesidad urgente de programas de alfabetización informacional y alfabetización en IA, enseñando a los estudiantes a verificar respuestas, identificar sesgos, contrastar perspectivas y comprender límites de los modelos generativos.
Los autores reconocen algunas limitaciones metodológicas. La muestra estaba sobrerrepresentada por estudiantes de posgrado, internacionales y vinculados a ciencias de la computación e información, lo que puede inflar los niveles generales de adopción tecnológica. Además, el estudio se basa en autoinformes y no en observación directa del comportamiento real. Por ello recomiendan investigaciones futuras con muestras más representativas, entrevistas cualitativas y estudios experimentales que analicen cómo los estudiantes combinan IA, buscadores y biblioteca ante necesidades concretas de información.
Apéndice. Encuesta sobre IA y búsqueda de información
1. ¿Cuál de las siguientes opciones describe mejor tu especialidad académica? a. Artes – bellas artes, música, danza, fotografía b. Humanidades – filosofía, historia, literatura, lenguas c. Ciencias Sociales – psicología, sociología, economía, educación, biblioteconomía d. Ciencias Naturales – biología, química, matemáticas, ecología, ingeniería e. Ciencias de la Computación – informática, ciencia de la información, ciencia de datos, IA f. Empresa – administración, hostelería, sistemas y ciencias de la decisión, marketing
2. ¿Cuál es tu nivel académico actual? a. Estudiante de grado b. Estudiante de máster c. Estudiante de doctorado
3. ¿Cuál es tu edad? a. 18–25 b. 26–30 c. 31–35 d. 36 o más
4. ¿Cuál es tu género? a. Mujer b. Hombre c. No binario d. Otro
5. ¿Cuál describe mejor tu situación como estudiante? a. Estudiante nacional b. Estudiante internacional
6. Pensando específicamente en tus actividades académicas y/o experiencias de investigación, indica con qué frecuencia utilizas cada una de las siguientes fuentes de información (nunca, menos de una vez al mes, mensualmente, semanalmente, diariamente): a. Libros b. Revistas científicas c. Actas de congresos d. Recursos web e. Bases de datos bibliotecarias f. Comunicaciones personales g. Herramientas de IA generativa
7. Pensando específicamente en tus actividades académicas y/o experiencias de investigación, ¿qué grado de confianza tienes en que encuentras toda la información necesaria sobre un tema cuando utilizas los siguientes recursos? (nada confiado, poco confiado, neutral, bastante confiado, muy confiado): a. Libros b. Revistas científicas c. Actas de congresos d. Recursos web e. Bases de datos bibliotecarias f. Comunicaciones personales g. Herramientas de IA generativa
8. ¿Cuál de las siguientes interfaces preferirías utilizar al comenzar tu búsqueda de información? a. Página principal de la biblioteca b. Google/motor de búsqueda c. Chatbot de IA/modelo de lenguaje grande
9. ¿Cuántas veces has realizado las siguientes actividades durante el último mes? a. Visitado la biblioteca universitaria, utilizado la web de la biblioteca o accedido a recursos bibliotecarios mediante enlaces web. b. Utilizado Google u otro motor de búsqueda similar para actividades o tareas universitarias. c. Utilizado una herramienta de IA para actividades o tareas universitarias.
10. Al realizar una tarea concreta de búsqueda de información relacionada con estudios o investigación, ¿con qué frecuencia recurres a los siguientes enfoques? (nunca, raramente, a veces, a menudo, siempre): a. Utilizar solo un motor de búsqueda tradicional b. Utilizar solo un chatbot de IA/ChatGPT c. Primero utilizar un motor de búsqueda tradicional y después un chatbot de IA/ChatGPT d. Primero utilizar un chatbot de IA/ChatGPT y después un motor de búsqueda tradicional
11. Pensando en la información que buscas en tu vida diaria, ¿qué probabilidad hay de que uses un motor de búsqueda tradicional para lo siguiente? (muy improbable, algo improbable, ni probable ni improbable, algo probable, muy probable): a. Encontrar información relacionada con empleo b. Encontrar información relacionada con estudios c. Aprender más sobre un tema que estudias d. Consultar el tiempo e. Ponerte al día con noticias recientes f. Crear chistes o historias g. Crear un conjunto de instrucciones para completar una tarea
12. Pensando en la información que buscas en tu vida diaria, ¿qué probabilidad hay de que uses chatbots de IA/ChatGPT para lo siguiente? (muy improbable, algo improbable, ni probable ni improbable, algo probable, muy probable): a. Encontrar información relacionada con empleo b. Encontrar información relacionada con estudios c. Aprender más sobre un tema que estudias d. Consultar el tiempo e. Ponerte al día con noticias recientes f. Crear chistes o historias g. Crear un conjunto de instrucciones para completar una tarea
13. Cuando buscas cada uno de los siguientes tipos de información, ¿con qué frecuencia un motor de búsqueda es capaz de generar una respuesta relevante? Nota: relevante significa únicamente que proporciona información pertinente sobre el tema, no necesariamente que sea exacta o satisfactoria para ti. (nunca, no muy a menudo, con cierta frecuencia, muy a menudo, siempre): a. Encontrar información relacionada con empleo b. Encontrar información relacionada con estudios c. Aprender más sobre un tema que estudias d. Consultar el tiempo e. Ponerte al día con noticias recientes f. Crear chistes o historias g. Crear un conjunto de instrucciones para completar una tarea
14. Cuando buscas cada uno de los siguientes tipos de información, ¿con qué frecuencia un chatbot de IA/ChatGPT es capaz de generar una respuesta relevante? Nota: relevante significa únicamente que proporciona información pertinente sobre el tema, no necesariamente que sea exacta o satisfactoria para ti. (nunca, no muy a menudo, con cierta frecuencia, muy a menudo, siempre): a. Encontrar información relacionada con empleo b. Encontrar información relacionada con estudios c. Aprender más sobre un tema que estudias d. Consultar el tiempo e. Ponerte al día con noticias recientes f. Crear chistes o historias g. Crear un conjunto de instrucciones para completar una tarea
15. Cuando buscas cada uno de los siguientes tipos de información, ¿con qué frecuencia un motor de búsqueda tradicional es capaz de generar una respuesta satisfactoria? Nota: una respuesta satisfactoria es aquella que cubre completamente la información que necesitas y con la que quedas satisfecho/a. (nunca, no muy a menudo, con cierta frecuencia, muy a menudo, siempre): a. Encontrar información relacionada con empleo b. Encontrar información relacionada con estudios c. Aprender más sobre un tema que estudias d. Consultar el tiempo e. Ponerte al día con noticias recientes f. Crear chistes o historias g. Crear un conjunto de instrucciones para completar una tarea
16. Cuando buscas cada uno de los siguientes tipos de información, ¿con qué frecuencia un chatbot de IA/ChatGPT es capaz de generar una respuesta satisfactoria? Nota: una respuesta satisfactoria es aquella que cubre completamente la información que necesitas y con la que quedas satisfecho/a. (nunca, no muy a menudo, con cierta frecuencia, muy a menudo, siempre): a. Encontrar información relacionada con empleo b. Encontrar información relacionada con estudios c. Aprender más sobre un tema que estudias d. Consultar el tiempo e. Ponerte al día con noticias recientes f. Crear chistes o historias g. Crear un conjunto de instrucciones para completar una tarea
Wilson, T. D. (2026).Explorando el comportamiento informacional. (Trad. Martha Sabelli y José Vicente Rodríguez Muñoz). (Ed. y Trad. Francisco Javier Martínez Méndez). Editum. Ediciones de la Universidad de Murcia. https://doi.org/10.6018/editum.3204
El autor revisa los principales modelos teóricos del campo e incorpora enfoques de disciplinas como la psicología, la sociología y la comunicación, destacando la influencia de factores contextuales, cognitivos y emocionales. Además, amplía la visión tradicional centrada en la “búsqueda de información” hacia un concepto más amplio de “comportamiento informacional”, que incluye tanto la búsqueda intencional como el descubrimiento accidental de información.
En conjunto, el libro ofrece una introducción estructurada que combina teoría y evidencia, consolidando un enfoque centrado en el usuario clave para la investigación, la enseñanza y el diseño de sistemas de información.
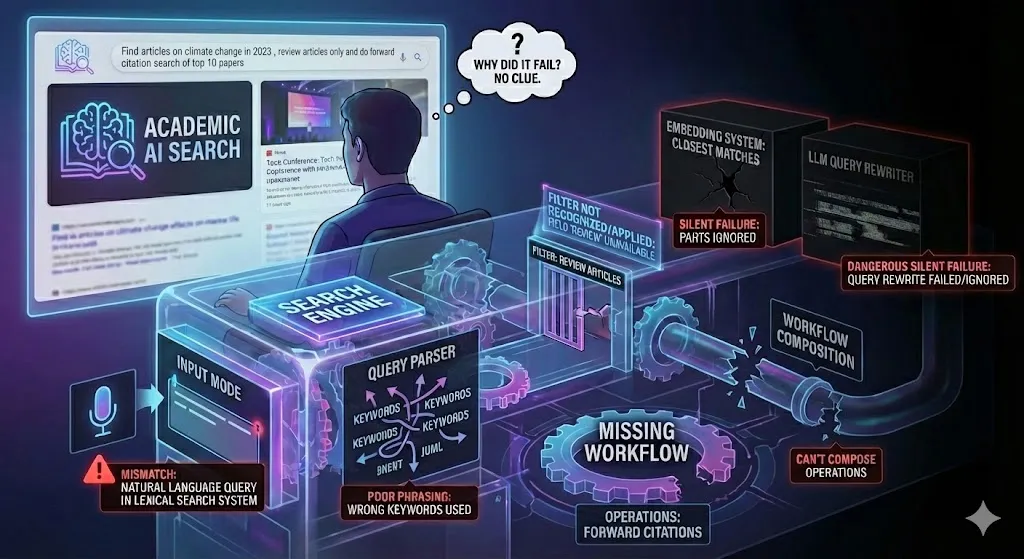
Se aborda un fenómeno importante y creciente en la forma en que interactuamos con las tecnologías de búsqueda potenciada por inteligencia artificial. Aaron Tay describe el llamado “problema de la caja vacía”, que se refiere a la interfaz minimalista y aparentemente sencilla que caracteriza a las nuevas herramientas de búsqueda con IA: una simple barra de texto en blanco donde el usuario debe escribir su consulta sin ninguna guía explícita. Aunque esta simplicidad visual puede parecer atractiva, Tay argumenta que en realidad introduce una complejidad mucho mayor para el usuario, quien ahora enfrenta un desafío mucho más grande para formular preguntas efectivas. La ausencia de señales visuales, filtros o estructuras de consulta claras que existían en los motores de búsqueda tradicionales provoca que el usuario quede desorientado y no sepa qué tipo de entrada es la más adecuada para obtener resultados precisos o útiles.
En la era previa a la inteligencia artificial, muchas plataformas de búsqueda ofrecían herramientas como operadores booleanos, menús desplegables y categorías que ayudaban a los usuarios a acotar y precisar sus consultas. Estas herramientas, aunque a veces complejas, proporcionaban un marco de referencia sobre cómo interactuar con la base de datos o motor de búsqueda. Sin embargo, las interfaces modernas con IA, como los chatbots y asistentes inteligentes, presentan una única caja de texto sin indicaciones claras sobre qué esperar. Esto crea dos niveles de ambigüedad para el usuario: por un lado, no está seguro de cómo debe redactar su consulta —si debe usar términos técnicos, lenguaje natural, frases completas, comandos específicos o prompts diseñados para la IA—, y por otro lado, desconoce qué tipo de capacidades tiene el sistema, qué preguntas puede responder con precisión y cuáles no. Esta doble incertidumbre dificulta la confianza en el sistema y genera una sensación de trial and error constante, en la que los usuarios prueban diferentes formas de preguntar sin saber cuál será la mejor.
Además, Aaron Tay compara esta situación actual con la experiencia de años anteriores en entornos académicos y profesionales, donde las bases de datos especializadas exigían un aprendizaje de formatos y comandos específicos para ser usadas eficazmente. A pesar de ser más técnicas, esas plataformas ofrecían a los usuarios un marco claro y reglas definidas para construir consultas. En contraste, la actual “caja vacía” no ofrece ningún tipo de feedback inmediato ni estructura clara, por lo que los usuarios desarrollan sus propias “teorías populares” o intuiciones sobre cómo deben preguntar, a menudo basadas en ensayo y error o en compartir trucos entre comunidades en línea. Este fenómeno evidencia la falta de transparencia en cómo los modelos de IA interpretan el lenguaje y procesan las solicitudes, dejando a los usuarios sin un entendimiento real sobre la arquitectura interna que guía la generación de respuestas.
Finalmente, el artículo enfatiza que esta simplicidad superficial puede resultar contraproducente, ya que la interfaz minimalista esconde un funcionamiento interno complejo que no se comunica al usuario. Esto crea una brecha entre la experiencia del usuario y la tecnología, dificultando no solo la eficacia en la búsqueda, sino también la confianza y la adopción plena de estas nuevas herramientas. Aaron Tay sugiere que para superar este desafío, es necesario repensar el diseño de las interfaces de búsqueda con IA, de modo que se mantenga la accesibilidad y simplicidad, pero se agreguen señales claras y transparencia sobre las capacidades reales del sistema. Solo así se podrá equilibrar la promesa de la inteligencia artificial con la necesidad humana de entender y controlar las herramientas que utilizamos diariamente.
Lo, Leo S. “The CARE Approach for Academic Librarians: From Search First to Answer First with Generative AI.” The Journal of Academic Librarianship 52, no. 1 (enero 2026): 103186. https://doi.org/10.1016/j.acalib.2025.103186
En el entorno académico actual, estudiantes y profesores cada vez más inician sus investigaciones solicitando explicaciones a sistemas de inteligencia artificial en lugar de comenzar con la búsqueda tradicional en los recursos de la biblioteca. Las herramientas de IA y los motores de búsqueda avanzados proporcionan respuestas desarrolladas incluso antes de que el usuario vea una lista de fuentes académicas. Este fenómeno transforma el punto de partida de la indagación académica y plantea nuevos desafíos para las prácticas de la bibliotecología.
Dado este cambio hacia un enfoque de “respuesta primero”, el autor sostiene que los bibliotecarios también deben evolucionar su mentalidad y estrategias de intervención. En lugar de simplemente ofrecer acceso a recursos, los bibliotecarios necesitan reconocer las respuestas generadas por IA como textos que demandan interpretación y análisis crítico. Para ello, se propone la creación de una tipografía de respuestas que ayude a identificar la función que cumplen estas respuestas automatizadas.
Finalmente, el artículo propone el enfoque CARE —por sus siglas en inglés: Classify, Assess, Review, Enhance (Clasificar, Evaluar, Revisar, Mejorar)— como un marco metodológico para interactuar críticamente con las respuestas de IA en colaboración con los usuarios. Este enfoque sitúa a los bibliotecarios como guías que ayudan a sus comunidades académicas a leer, cuestionar y ampliar las respuestas generadas por IA manteniendo el juicio humano y la evidencia científica en el centro de la investigación.
la transformación profunda que está experimentando la búsqueda de productos en el comercio digital con la irrupción de los motores generativos de inteligencia artificial. Durante dos décadas, el SEO tradicional marcó las normas de visibilidad online, obligando tanto a usuarios como a minoristas a pensar en términos de palabras clave, enlaces y estructuras legibles para los algoritmos. Sin embargo, ese modelo se está desmoronando. Los motores de IA como Gemini, ChatGPT, Claude o Perplexity ya no se limitan a indexar páginas, sino que interpretan significados, contextos e intenciones. Este cambio está alterando de raíz el modo en que los consumidores descubren productos: más del 60% de las búsquedas terminan sin clic y se prevé un descenso del 50% del tráfico orgánico para 2028, al prevalecer las respuestas generadas directamente por IA. En este nuevo escenario, la cuestión clave no es si un producto “aparece”, sino si es correctamente comprendido por los sistemas generativos.
Se subraya además que los consumidores ya no buscan listados de enlaces, sino relevancia, precisión contextual y orientación personalizada. Las personas formulan peticiones en lenguaje natural, como “un vestido suave y fluido para unas vacaciones de verano”, y esperan que el sistema entienda matices de ocasión, clima, estilo o preferencia estética. Esto exige un nivel de comprensión semántica imposible de satisfacer con descripciones de producto pobres o centradas únicamente en palabras clave. Frente a ello surge el concepto de GEO (Generative Engine Optimization), entendido como la disciplina orientada a que los productos se representen adecuadamente en respuestas generadas por IA. Si el SEO decía a las máquinas “qué ver”, el GEO les enseña “qué significa” cada producto: qué es, para quién sirve, en qué contexto es adecuado y por qué debería recomendarse.
El documento sostiene que los catálogos ya no pueden ser inventarios estáticos, sino auténticas infraestructuras de datos. Los motores generativos funcionan relacionando atributos, imágenes, metadatos y descripciones para formar una representación coherente de cada artículo. Si faltan datos o contexto, la IA rellena los huecos de forma incorrecta, lo que compromete la relevancia. En cambio, un catálogo enriquecido —con taxonomías coherentes, atributos completos, descripciones en lenguaje natural y metadatos unificados— se convierte en un grafo de conocimiento vivo que facilita que la IA conecte productos con necesidades reales. El texto muestra cómo la falta de precisión puede provocar errores, como confundir un pintalabios rojo con tonos completamente distintos, mientras que un sistema de datos bien estructurado favorece recomendaciones fiables, personalizadas y consistentes.
Por último, el informe explica cómo los minoristas pueden prepararse para este nuevo entorno dominado por la IA. Propone acciones como enriquecer los datos de producto más allá de lo básico; optimizar descripciones para consultas naturales; unificar y automatizar los metadatos mediante esquemas y taxonomías; mantener la información constantemente actualizada; y adoptar nuevas métricas que midan la representación semántica en lugar del ranking tradicional. Según el documento, el éxito dependerá de comprender que el contenido de producto ya no es un elemento estático de merchandising, sino un lenguaje compartido entre consumidores, comerciantes, anunciantes y máquinas. Empresas como Lily AI ofrecen plataformas diseñadas para convertir catálogos en sistemas de información legibles por la IA, mejorando la precisión de las recomendaciones, la coherencia de los datos y, en última instancia, las ventas.
Se informa sobre una investigación llevada a cabo por la Ruhr University Bochum y el Max Planck Institute for Software Systems, que compara cómo los motores de búsqueda tradicionales —ejemplificados por Google Search— y los sistemas de búsqueda generativa de IA —como Gemini 2.5 Flash, GPT‑4o con herramienta de búsqueda y la interfaz “Search” de GPT-4o— seleccionan y referencian fuentes web en respuestas a consultas.
Se analizaron más de 4.600 consultas sobre temas diversos (política, productos, ciencia) y se observaron diferencias sustanciales en el origen, cantidad y visibilidad de los enlaces utilizados por cada sistema.
Una de las principales conclusiones es que los sistemas de IA dependen mucho más que la búsqueda tradicional de sitios menos establecidos o con menor visibilidad. Por ejemplo, aproximadamente el 53 % de los sitios citados por el sistema “AI Overview” no aparecían dentro de los diez primeros resultados orgánicos de Google, y cerca del 27 % no estaban siquiera en los primeros cien. En consecuencia, los usuarios que confían en chatbots pueden estar accediendo a contenido procedente de dominios más desconocidos o menos regulados que aquellos a los que normalmente llegarían mediante la búsqueda convencional.
Asimismo, la investigación señala que la cantidad de fuentes externas varía notablemente entre los sistemas. Mientras que algunos modelos de IA incorporan muchos enlaces (por ejemplo, “AI Overview” y Gemini utilizan más de ocho sitios por consulta, de media), otros como “GPT-Tool” emplean un promedio muy bajo, alrededor de 0,4 fuentes externas, apoyándose casi exclusivamente en su conocimiento interno. Esto implica que la profundidad y diversificación de la información pueden variar ampliamente según el sistema usado.
El estudio también analiza la cobertura temática y cómo varía según el tipo de consulta. En temas ambiguos o complejos, la búsqueda tradicional alcanzó una cobertura del 60 % de los subtemas esperados, frente al 51 % alcanzado por “AI Overview” y sólo 47 % por “GPT-Tool”. Esto da a entender que los chatbots de IA pueden ofrecer respuestas más rápidas o consolidadas, pero podrían estar omitiendo matices, perspectivas adicionales o más amplios marcos de análisis que los motores de búsqueda tradicionales tienden a cubrir.
En lo que respecta a temas de actualidad o noticias recientes, la búsqueda tradicional también mostró ventaja: en un test con 100 temas tendencia en septiembre 2025, Google alcanzó un 67 % de cobertura, “GPT-Search” un 72 % (ligeramente superior) pero “AI Overview” sólo un 3 %, y “GPT-Tool” un 51 %. Esto sugiere que no todos los sistemas de IA están optimizados para rastrear o indexar los últimos eventos tan eficazmente como los motores de búsqueda clásicos.
Finalmente, el artículo advierte que estos cambios en selección de fuentes y metodología de citación tienen implicaciones importantes para la credibilidad, verificación y equidad de la información que reciben los usuarios. Al recurrir con frecuencia a sitios menos conocidos, la transparencia sobre la autoridad, la calidad y el sesgo de esas fuentes puede disminuir. También plantea que las habituales reglas de evaluación de calidad de búsquedas deben adaptarse, pues los sistemas de búsqueda de IA operan bajo lógicas distintas y requieren criterios propios para valorar su fiabilidad.
En esencia, el artículo invita a usuarios, bibliotecarios, investigadores y profesionales de la información a tener conciencia de estas diferencias. No basta con asumir que una respuesta generada por un chatbot es equivalente a haber realizado una búsqueda exhaustiva: la procedencia y visibilidad de las fuentes pueden ser muy distintas, lo cual comporta riesgos y oportunidades diferentes respecto a la práctica informacional tradicional.
Google ha introducido los llamados AI Overviews, resúmenes generados por IA que aparecen directamente en los resultados de búsqueda. Estos tienen un impacto disruptivo, equiparándose a los featured snippets en importancia
Los AI Overviews, resúmenes generados por inteligencia artificial que Google ha incorporado en sus resultados de búsqueda. Estos elementos ya ocupan un rol importante y están modificando de manera profunda las estrategias de posicionamiento.
Los datos muestran que en marzo de 2025 el 13,14 % de las consultas en escritorio en EE. UU. activaron un AI Overview, casi el doble que en enero del mismo año. La mayoría de estas consultas fueron de carácter informacional (88,1 %), aunque también se detectó un ligero incremento en consultas comerciales y de navegación. Las áreas más afectadas incluyen ciencia, salud, sociedad y gobierno, mientras que sectores como noticias y deportes casi no presentan AI Overviews, reflejando la cautela de Google en temas sensibles o de actualidad.
En cuanto al comportamiento de los usuarios, los AI Overviews están vinculados a un aumento de las búsquedas sin clics (zero-click). Sin embargo, al comparar las mismas palabras clave antes y después de aparecer con AI Overview, la tasa de zero-click disminuyó levemente de 38,1 % a 36,2 %. Esto sugiere que, aunque más usuarios encuentran la respuesta sin salir de Google, algunos siguen interactuando con los enlaces destacados dentro del propio resumen generado por IA.
El estudio también señala que los AI Overviews se muestran sobre todo en consultas largas, de baja competencia y bajo coste por clic (CPC). Además, tienden a superponerse a funciones ya existentes del SERP sin reemplazarlas, y suelen dar relevancia a contenidos de plataformas como Reddit, Quora y YouTube, lo que indica una preferencia de Google por fuentes diversificadas y con información estructurada.
Las recomendaciones para las marcas son claras: crear contenido informacional autoritativo y con perspectiva única, reforzar los formatos visuales e interactivos (como vídeos o herramientas), e identificar palabras clave comerciales que aún no activan AI Overviews para aprovechar oportunidades de posicionamiento tradicional. Asimismo, se recomienda el uso de herramientas de monitorización como el Semrush AI Toolkit para medir la visibilidad en estos nuevos entornos y ajustar las estrategias de SEO.
En definitiva, el SEO en 2025 ya no se limita a aparecer en las primeras posiciones de búsqueda, sino a ganar presencia en los resultados generados por IA. El contenido de calidad, adaptado a este nuevo ecosistema híbrido entre buscador tradicional y motor de respuestas, será determinante para mantener la visibilidad digital.
Kusano, Genki, Kosuke Akimoto, y Kunihiro Takeoka. “Revisiting Prompt Engineering: A Comprehensive Evaluation for LLM‑based Personalized Recommendation.” ArXiv, julio 17 de 2025. https://arxiv.org/abs/2507.13525v1.
Los investigadores se adentran en el diseño de ingeniería de prompts, variando aspectos como la estructura (instrucciones explícitas, estilo conversacional), la extensión y formalidad del texto, y la inclusión de ejemplos contextuales. Su objetivo es entender cómo estas variantes afectan tres métricas clave: precisión de la recomendación, relevancia semántica del contenido generado y calidad de las explicaciones aportadas. Mediante el análisis de diferentes LLMs –sin nombrarlos específicamente en el artículo–, se observan diferencias marcadas según el tipo de prompt utilizado.
Los resultados muestran que un prompt cuidadosamente estructurado puede igualar o incluso superar los métodos tradicionales, especialmente en entornos con escasos datos de usuario. Destaca la importancia de utilizar ejemplos contextuales y formatos de diálogo que guían al modelo, lo que mejora tanto la exactitud de las recomendaciones como su explicabilidad. Sin embargo, los LLM se revelan sensibles a cambios mínimos en los prompts, lo que plantea desafíos de robustez y reproducibilidad si se pretende aplicarlos a gran escala.
Los autores concluyen que la ingeniería de prompts podría ofrecer una alternativa eficiente a los enfoques convencionales, evitando la necesidad de grandes volúmenes de datos, infraestructuras de entrenamiento o información demográfica. Apuntan, no obstante, a la urgencia de desarrollar métodos para automatizar el diseño de prompts y reforzar la consistencia de los modelos. Proponen futuras líneas de investigación que aborden estos retos, contribuyendo a consolidar a los LLM como herramientas fiables en entornos reales de recomendación personalizada.