Google está realizando cambios importantes en su experiencia de búsqueda. En lugar de ofrecer la lista de enlaces habitual que ha existido durante décadas, las consultas a veces dirigirán a los usuarios a una interfaz interactiva con IA donde podrán interactuar directamente con las respuestas y hacer preguntas adicionales. Estas actualizaciones también implementarán nuevos formatos publicitarios, incluyendo anuncios con funciones de IA que permiten a los usuarios interactuar con ellos.
Muchos estadounidenses ya encuentran resúmenes generados por IA en sus resultados de búsqueda, pero las opiniones sobre su utilidad son diversas. En agosto pasado, una encuesta del Pew Research Center reveló que el 65% de los adultos estadounidenses (incluida una mayoría aún mayor de adultos jóvenes) afirmó haber visto estos resúmenes al menos en alguna ocasión. Entre quienes habían visto resúmenes de búsqueda con IA, uno de cada cinco afirmó que los consideraba extremadamente o muy útiles, y el 6% dijo confiar mucho en la información de estos resúmenes.
Los motores de búsqueda como Google son una forma común en que muchos estadounidenses se informan: el 63% de los adultos estadounidenses afirma informarse de esta manera al menos en ocasiones.
Google anunció en su conferencia anual Google I/O 2026 la mayor transformación de su buscador desde su lanzamiento hace más de veinticinco años. Según la compañía, la era de los tradicionales “diez enlaces azules” está llegando a su fin para dar paso a una experiencia impulsada por inteligencia artificial, donde las respuestas, las interacciones y las acciones ocuparán un lugar mucho más importante que la simple lista de resultados web.
El cambio gira en torno a una nueva “caja de búsqueda inteligente”, diseñada para que los usuarios formulen preguntas largas y complejas de manera conversacional. En lugar de obligar a las personas a buscar mediante palabras clave, el sistema interpreta intenciones, sugiere consultas más sofisticadas y mantiene conversaciones de seguimiento sin que el usuario tenga que reformular constantemente su pregunta. La búsqueda se convierte así en un diálogo continuo con la inteligencia artificial.
Uno de los aspectos más innovadores es la incorporación de agentes de información. Estos asistentes pueden trabajar en segundo plano las veinticuatro horas del día, rastreando cambios en la web, recopilando datos y notificando al usuario cuando se cumplen determinadas condiciones. Por ejemplo, podrán vigilar movimientos financieros, seguir la evolución de un mercado específico o monitorizar cualquier tema de interés para proporcionar actualizaciones sintetizadas y contextualizadas. Esta funcionalidad supone una evolución significativa respecto a herramientas anteriores como Google Alerts.
La inteligencia artificial también permitirá que los resultados de búsqueda adopten la forma de experiencias interactivas. Gracias a técnicas de interfaz generativa, Search podrá construir visualizaciones, simulaciones, paneles de información y herramientas personalizadas adaptadas a cada consulta. Una búsqueda sobre agujeros negros, por ejemplo, podría convertirse en una representación gráfica interactiva que responda dinámicamente a nuevas preguntas formuladas por el usuario.
Otra novedad destacada es la posibilidad de crear pequeñas aplicaciones personalizadas directamente desde el buscador. Mediante instrucciones en lenguaje natural, los usuarios podrán desarrollar herramientas adaptadas a sus necesidades concretas, como planificadores de comidas, aplicaciones de seguimiento deportivo o gestores de proyectos personales. Google deja entrever una visión en la que la búsqueda deja de ser únicamente una herramienta para encontrar información y pasa a convertirse en una plataforma para realizar tareas y tomar decisiones.
Esta transformación se apoya en la integración de los modelos Gemini y de la plataforma Antigravity, desarrollada por Google para aplicaciones autónomas basadas en IA. La compañía afirma que la nueva experiencia será gratuita para todos los usuarios, aunque algunas funciones avanzadas relacionadas con agentes inteligentes y aplicaciones personalizadas llegarán inicialmente a los suscriptores de los planes Google AI Pro y Ultra.
Sin embargo, el anuncio también ha despertado preocupación entre medios de comunicación, creadores de contenidos y editores digitales. Al proporcionar respuestas completas dentro del propio buscador, los usuarios tendrán menos necesidad de visitar las páginas originales donde se encuentra la información. Diversos analistas advierten de que esta tendencia podría reducir aún más el tráfico web hacia los sitios de noticias, blogs y otros recursos en línea, agravando un problema que ya comenzó con la introducción de los resúmenes automáticos AI Overviews.
Las reacciones en comunidades tecnológicas han sido encontradas. Mientras algunos usuarios valoran la rapidez y comodidad de obtener respuestas directas, otros temen una creciente concentración del control de la información en manos de una única empresa. También se plantean interrogantes sobre la sostenibilidad económica de la web abierta, ya que muchos sitios dependen de las visitas generadas por los motores de búsqueda tradicionales.
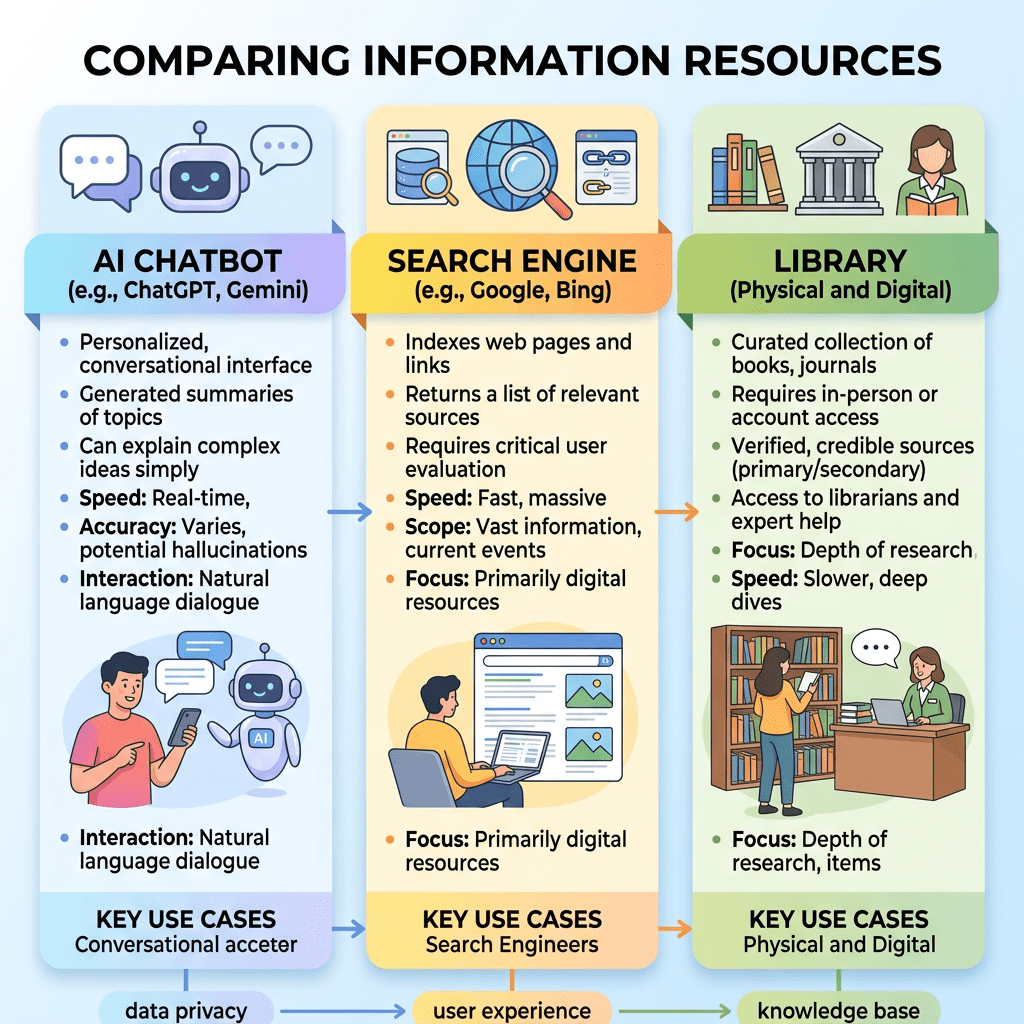
An infographic comparing AI chatbots, search engines, and libraries as information resources.
Lund, Brady D., Zoe Abbie Teel, Ting Wang, et al. “Artificial Intelligence (AI) and Information Seeking: A Comparative Exploration of AI Chatbots, Search Engines, and Library Resources as Information Sources among University Students.” Journal of Librarianship and Information Science (OnlineFirst, 2026). https://doi.org/10.1177/09610006261438484
El artículo retrata un momento de transición en el ecosistema informativo universitario. La IA no ha desplazado a Google ni a las bibliotecas, pero ya se ha incorporado de forma visible a las rutinas académicas. Su papel es complementario, aunque en expansión, especialmente entre estudiantes jóvenes e internacionales. Para las bibliotecas y universidades, el reto no consiste en resistirse al cambio, sino en liderarlo: integrar la IA de forma ética, crítica y conectada con recursos académicos de calidad.
Este estudio analiza cómo los estudiantes universitarios de Estados Unidos están integrando la inteligencia artificial generativa en sus prácticas de búsqueda académica. A partir de una encuesta electrónica respondida por 236 estudiantes de perfiles diversos, los autores comparan el uso, preferencia y satisfacción con tres grandes fuentes de información: motores de búsqueda tradicionales (como Google), recursos bibliotecarios universitarios y herramientas de IA conversacional como ChatGPT. El trabajo parte de la idea de que la irrupción de la IA está modificando profundamente la ecología informacional en la educación superior, alterando la manera en que los estudiantes localizan, evalúan y utilizan información.
Los resultados muestran que los motores de búsqueda siguen siendo la herramienta dominante para tareas académicas, tanto por frecuencia de uso como por preferencia inicial al comenzar una investigación. Casi la mitad de los estudiantes indicaron que Google o buscadores similares son su primera opción, mientras que el resto se divide entre los recursos de biblioteca y la IA. Sin embargo, la IA ya ocupa un lugar significativo: solo un 15% declaró no haberla usado nunca para fines académicos, mientras que cerca del 10% la utiliza diariamente. Esto indica que la IA no ha sustituido aún a las herramientas tradicionales, pero sí se ha convertido en una pieza estable del repertorio informacional estudiantil.
Uno de los hallazgos más relevantes es la existencia de diferencias demográficas marcadas. Los estudiantes más jóvenes muestran mayor inclinación hacia la IA como punto de partida en sus búsquedas, mientras que los mayores prefieren claramente las páginas web de bibliotecas universitarias. Asimismo, los estudiantes internacionales utilizan la IA con mucha mayor frecuencia que los estudiantes nacionales estadounidenses. De hecho, recurren menos a los recursos bibliotecarios y más a herramientas de IA, lo que los autores interpretan como posible consecuencia de barreras idiomáticas, desconocimiento del entorno bibliotecario estadounidense o búsqueda de interfaces más accesibles y conversacionales.
En cuanto a la percepción de calidad, los buscadores tradicionales siguen obteniendo mejores puntuaciones globales que la IA en relevancia y satisfacción de resultados. Los estudiantes consideran especialmente eficaces a los buscadores para noticias recientes, meteorología e información laboral. En cambio, la IA obtiene valoraciones más competitivas cuando se trata de ayuda académica, preparación de exámenes, comprensión inicial de un tema o generación de instrucciones para realizar tareas. Esto sugiere que los usuarios perciben fortalezas diferenciadas: el buscador como herramienta de acceso a fuentes actualizadas y múltiples perspectivas, y la IA como asistente para sintetizar, orientar o explicar.
El estudio también demuestra una relación clara entre uso frecuente y satisfacción con la IA. Cuanto más emplea un estudiante estas herramientas, mayor es su percepción de utilidad. Los usuarios intensivos valoran especialmente la IA para tareas educativas, estudio y resolución de procedimientos. Esto puede indicar un aprendizaje progresivo del uso eficaz de la herramienta o una adaptación de expectativas a sus capacidades reales. Los autores advierten, no obstante, que esta relación también podría fomentar dependencia acrítica si los estudiantes aceptan respuestas sintéticas sin contrastarlas con fuentes primarias.
Desde la perspectiva bibliotecaria, el artículo plantea implicaciones estratégicas de gran interés. Las bibliotecas universitarias no deberían contemplar la IA únicamente como una amenaza competitiva, sino como una oportunidad para rediseñar sus servicios. Proponen desarrollar sistemas de descubrimiento apoyados en IA conectados directamente con colecciones licenciadas, bases de datos y contenidos académicos fiables. De este modo, las bibliotecas podrían ofrecer experiencias conversacionales semejantes a ChatGPT, pero sustentadas en recursos evaluados y legales. También subrayan la necesidad urgente de programas de alfabetización informacional y alfabetización en IA, enseñando a los estudiantes a verificar respuestas, identificar sesgos, contrastar perspectivas y comprender límites de los modelos generativos.
Los autores reconocen algunas limitaciones metodológicas. La muestra estaba sobrerrepresentada por estudiantes de posgrado, internacionales y vinculados a ciencias de la computación e información, lo que puede inflar los niveles generales de adopción tecnológica. Además, el estudio se basa en autoinformes y no en observación directa del comportamiento real. Por ello recomiendan investigaciones futuras con muestras más representativas, entrevistas cualitativas y estudios experimentales que analicen cómo los estudiantes combinan IA, buscadores y biblioteca ante necesidades concretas de información.
Apéndice. Encuesta sobre IA y búsqueda de información
1. ¿Cuál de las siguientes opciones describe mejor tu especialidad académica? a. Artes – bellas artes, música, danza, fotografía b. Humanidades – filosofía, historia, literatura, lenguas c. Ciencias Sociales – psicología, sociología, economía, educación, biblioteconomía d. Ciencias Naturales – biología, química, matemáticas, ecología, ingeniería e. Ciencias de la Computación – informática, ciencia de la información, ciencia de datos, IA f. Empresa – administración, hostelería, sistemas y ciencias de la decisión, marketing
2. ¿Cuál es tu nivel académico actual? a. Estudiante de grado b. Estudiante de máster c. Estudiante de doctorado
3. ¿Cuál es tu edad? a. 18–25 b. 26–30 c. 31–35 d. 36 o más
4. ¿Cuál es tu género? a. Mujer b. Hombre c. No binario d. Otro
5. ¿Cuál describe mejor tu situación como estudiante? a. Estudiante nacional b. Estudiante internacional
6. Pensando específicamente en tus actividades académicas y/o experiencias de investigación, indica con qué frecuencia utilizas cada una de las siguientes fuentes de información (nunca, menos de una vez al mes, mensualmente, semanalmente, diariamente): a. Libros b. Revistas científicas c. Actas de congresos d. Recursos web e. Bases de datos bibliotecarias f. Comunicaciones personales g. Herramientas de IA generativa
7. Pensando específicamente en tus actividades académicas y/o experiencias de investigación, ¿qué grado de confianza tienes en que encuentras toda la información necesaria sobre un tema cuando utilizas los siguientes recursos? (nada confiado, poco confiado, neutral, bastante confiado, muy confiado): a. Libros b. Revistas científicas c. Actas de congresos d. Recursos web e. Bases de datos bibliotecarias f. Comunicaciones personales g. Herramientas de IA generativa
8. ¿Cuál de las siguientes interfaces preferirías utilizar al comenzar tu búsqueda de información? a. Página principal de la biblioteca b. Google/motor de búsqueda c. Chatbot de IA/modelo de lenguaje grande
9. ¿Cuántas veces has realizado las siguientes actividades durante el último mes? a. Visitado la biblioteca universitaria, utilizado la web de la biblioteca o accedido a recursos bibliotecarios mediante enlaces web. b. Utilizado Google u otro motor de búsqueda similar para actividades o tareas universitarias. c. Utilizado una herramienta de IA para actividades o tareas universitarias.
10. Al realizar una tarea concreta de búsqueda de información relacionada con estudios o investigación, ¿con qué frecuencia recurres a los siguientes enfoques? (nunca, raramente, a veces, a menudo, siempre): a. Utilizar solo un motor de búsqueda tradicional b. Utilizar solo un chatbot de IA/ChatGPT c. Primero utilizar un motor de búsqueda tradicional y después un chatbot de IA/ChatGPT d. Primero utilizar un chatbot de IA/ChatGPT y después un motor de búsqueda tradicional
11. Pensando en la información que buscas en tu vida diaria, ¿qué probabilidad hay de que uses un motor de búsqueda tradicional para lo siguiente? (muy improbable, algo improbable, ni probable ni improbable, algo probable, muy probable): a. Encontrar información relacionada con empleo b. Encontrar información relacionada con estudios c. Aprender más sobre un tema que estudias d. Consultar el tiempo e. Ponerte al día con noticias recientes f. Crear chistes o historias g. Crear un conjunto de instrucciones para completar una tarea
12. Pensando en la información que buscas en tu vida diaria, ¿qué probabilidad hay de que uses chatbots de IA/ChatGPT para lo siguiente? (muy improbable, algo improbable, ni probable ni improbable, algo probable, muy probable): a. Encontrar información relacionada con empleo b. Encontrar información relacionada con estudios c. Aprender más sobre un tema que estudias d. Consultar el tiempo e. Ponerte al día con noticias recientes f. Crear chistes o historias g. Crear un conjunto de instrucciones para completar una tarea
13. Cuando buscas cada uno de los siguientes tipos de información, ¿con qué frecuencia un motor de búsqueda es capaz de generar una respuesta relevante? Nota: relevante significa únicamente que proporciona información pertinente sobre el tema, no necesariamente que sea exacta o satisfactoria para ti. (nunca, no muy a menudo, con cierta frecuencia, muy a menudo, siempre): a. Encontrar información relacionada con empleo b. Encontrar información relacionada con estudios c. Aprender más sobre un tema que estudias d. Consultar el tiempo e. Ponerte al día con noticias recientes f. Crear chistes o historias g. Crear un conjunto de instrucciones para completar una tarea
14. Cuando buscas cada uno de los siguientes tipos de información, ¿con qué frecuencia un chatbot de IA/ChatGPT es capaz de generar una respuesta relevante? Nota: relevante significa únicamente que proporciona información pertinente sobre el tema, no necesariamente que sea exacta o satisfactoria para ti. (nunca, no muy a menudo, con cierta frecuencia, muy a menudo, siempre): a. Encontrar información relacionada con empleo b. Encontrar información relacionada con estudios c. Aprender más sobre un tema que estudias d. Consultar el tiempo e. Ponerte al día con noticias recientes f. Crear chistes o historias g. Crear un conjunto de instrucciones para completar una tarea
15. Cuando buscas cada uno de los siguientes tipos de información, ¿con qué frecuencia un motor de búsqueda tradicional es capaz de generar una respuesta satisfactoria? Nota: una respuesta satisfactoria es aquella que cubre completamente la información que necesitas y con la que quedas satisfecho/a. (nunca, no muy a menudo, con cierta frecuencia, muy a menudo, siempre): a. Encontrar información relacionada con empleo b. Encontrar información relacionada con estudios c. Aprender más sobre un tema que estudias d. Consultar el tiempo e. Ponerte al día con noticias recientes f. Crear chistes o historias g. Crear un conjunto de instrucciones para completar una tarea
16. Cuando buscas cada uno de los siguientes tipos de información, ¿con qué frecuencia un chatbot de IA/ChatGPT es capaz de generar una respuesta satisfactoria? Nota: una respuesta satisfactoria es aquella que cubre completamente la información que necesitas y con la que quedas satisfecho/a. (nunca, no muy a menudo, con cierta frecuencia, muy a menudo, siempre): a. Encontrar información relacionada con empleo b. Encontrar información relacionada con estudios c. Aprender más sobre un tema que estudias d. Consultar el tiempo e. Ponerte al día con noticias recientes f. Crear chistes o historias g. Crear un conjunto de instrucciones para completar una tarea
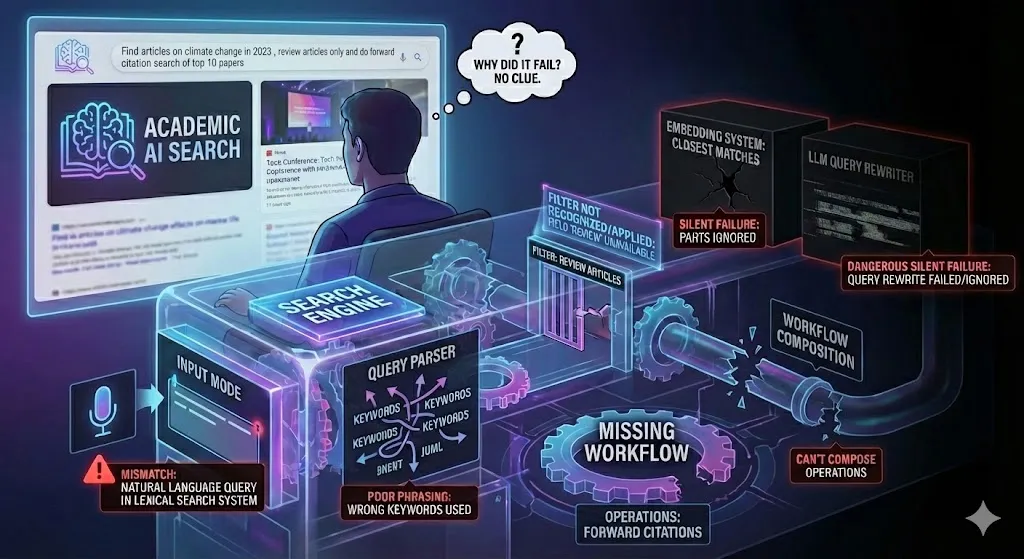
Se aborda un fenómeno importante y creciente en la forma en que interactuamos con las tecnologías de búsqueda potenciada por inteligencia artificial. Aaron Tay describe el llamado “problema de la caja vacía”, que se refiere a la interfaz minimalista y aparentemente sencilla que caracteriza a las nuevas herramientas de búsqueda con IA: una simple barra de texto en blanco donde el usuario debe escribir su consulta sin ninguna guía explícita. Aunque esta simplicidad visual puede parecer atractiva, Tay argumenta que en realidad introduce una complejidad mucho mayor para el usuario, quien ahora enfrenta un desafío mucho más grande para formular preguntas efectivas. La ausencia de señales visuales, filtros o estructuras de consulta claras que existían en los motores de búsqueda tradicionales provoca que el usuario quede desorientado y no sepa qué tipo de entrada es la más adecuada para obtener resultados precisos o útiles.
En la era previa a la inteligencia artificial, muchas plataformas de búsqueda ofrecían herramientas como operadores booleanos, menús desplegables y categorías que ayudaban a los usuarios a acotar y precisar sus consultas. Estas herramientas, aunque a veces complejas, proporcionaban un marco de referencia sobre cómo interactuar con la base de datos o motor de búsqueda. Sin embargo, las interfaces modernas con IA, como los chatbots y asistentes inteligentes, presentan una única caja de texto sin indicaciones claras sobre qué esperar. Esto crea dos niveles de ambigüedad para el usuario: por un lado, no está seguro de cómo debe redactar su consulta —si debe usar términos técnicos, lenguaje natural, frases completas, comandos específicos o prompts diseñados para la IA—, y por otro lado, desconoce qué tipo de capacidades tiene el sistema, qué preguntas puede responder con precisión y cuáles no. Esta doble incertidumbre dificulta la confianza en el sistema y genera una sensación de trial and error constante, en la que los usuarios prueban diferentes formas de preguntar sin saber cuál será la mejor.
Además, Aaron Tay compara esta situación actual con la experiencia de años anteriores en entornos académicos y profesionales, donde las bases de datos especializadas exigían un aprendizaje de formatos y comandos específicos para ser usadas eficazmente. A pesar de ser más técnicas, esas plataformas ofrecían a los usuarios un marco claro y reglas definidas para construir consultas. En contraste, la actual “caja vacía” no ofrece ningún tipo de feedback inmediato ni estructura clara, por lo que los usuarios desarrollan sus propias “teorías populares” o intuiciones sobre cómo deben preguntar, a menudo basadas en ensayo y error o en compartir trucos entre comunidades en línea. Este fenómeno evidencia la falta de transparencia en cómo los modelos de IA interpretan el lenguaje y procesan las solicitudes, dejando a los usuarios sin un entendimiento real sobre la arquitectura interna que guía la generación de respuestas.
Finalmente, el artículo enfatiza que esta simplicidad superficial puede resultar contraproducente, ya que la interfaz minimalista esconde un funcionamiento interno complejo que no se comunica al usuario. Esto crea una brecha entre la experiencia del usuario y la tecnología, dificultando no solo la eficacia en la búsqueda, sino también la confianza y la adopción plena de estas nuevas herramientas. Aaron Tay sugiere que para superar este desafío, es necesario repensar el diseño de las interfaces de búsqueda con IA, de modo que se mantenga la accesibilidad y simplicidad, pero se agreguen señales claras y transparencia sobre las capacidades reales del sistema. Solo así se podrá equilibrar la promesa de la inteligencia artificial con la necesidad humana de entender y controlar las herramientas que utilizamos diariamente.
Se informa sobre una investigación llevada a cabo por la Ruhr University Bochum y el Max Planck Institute for Software Systems, que compara cómo los motores de búsqueda tradicionales —ejemplificados por Google Search— y los sistemas de búsqueda generativa de IA —como Gemini 2.5 Flash, GPT‑4o con herramienta de búsqueda y la interfaz “Search” de GPT-4o— seleccionan y referencian fuentes web en respuestas a consultas.
Se analizaron más de 4.600 consultas sobre temas diversos (política, productos, ciencia) y se observaron diferencias sustanciales en el origen, cantidad y visibilidad de los enlaces utilizados por cada sistema.
Una de las principales conclusiones es que los sistemas de IA dependen mucho más que la búsqueda tradicional de sitios menos establecidos o con menor visibilidad. Por ejemplo, aproximadamente el 53 % de los sitios citados por el sistema “AI Overview” no aparecían dentro de los diez primeros resultados orgánicos de Google, y cerca del 27 % no estaban siquiera en los primeros cien. En consecuencia, los usuarios que confían en chatbots pueden estar accediendo a contenido procedente de dominios más desconocidos o menos regulados que aquellos a los que normalmente llegarían mediante la búsqueda convencional.
Asimismo, la investigación señala que la cantidad de fuentes externas varía notablemente entre los sistemas. Mientras que algunos modelos de IA incorporan muchos enlaces (por ejemplo, “AI Overview” y Gemini utilizan más de ocho sitios por consulta, de media), otros como “GPT-Tool” emplean un promedio muy bajo, alrededor de 0,4 fuentes externas, apoyándose casi exclusivamente en su conocimiento interno. Esto implica que la profundidad y diversificación de la información pueden variar ampliamente según el sistema usado.
El estudio también analiza la cobertura temática y cómo varía según el tipo de consulta. En temas ambiguos o complejos, la búsqueda tradicional alcanzó una cobertura del 60 % de los subtemas esperados, frente al 51 % alcanzado por “AI Overview” y sólo 47 % por “GPT-Tool”. Esto da a entender que los chatbots de IA pueden ofrecer respuestas más rápidas o consolidadas, pero podrían estar omitiendo matices, perspectivas adicionales o más amplios marcos de análisis que los motores de búsqueda tradicionales tienden a cubrir.
En lo que respecta a temas de actualidad o noticias recientes, la búsqueda tradicional también mostró ventaja: en un test con 100 temas tendencia en septiembre 2025, Google alcanzó un 67 % de cobertura, “GPT-Search” un 72 % (ligeramente superior) pero “AI Overview” sólo un 3 %, y “GPT-Tool” un 51 %. Esto sugiere que no todos los sistemas de IA están optimizados para rastrear o indexar los últimos eventos tan eficazmente como los motores de búsqueda clásicos.
Finalmente, el artículo advierte que estos cambios en selección de fuentes y metodología de citación tienen implicaciones importantes para la credibilidad, verificación y equidad de la información que reciben los usuarios. Al recurrir con frecuencia a sitios menos conocidos, la transparencia sobre la autoridad, la calidad y el sesgo de esas fuentes puede disminuir. También plantea que las habituales reglas de evaluación de calidad de búsquedas deben adaptarse, pues los sistemas de búsqueda de IA operan bajo lógicas distintas y requieren criterios propios para valorar su fiabilidad.
En esencia, el artículo invita a usuarios, bibliotecarios, investigadores y profesionales de la información a tener conciencia de estas diferencias. No basta con asumir que una respuesta generada por un chatbot es equivalente a haber realizado una búsqueda exhaustiva: la procedencia y visibilidad de las fuentes pueden ser muy distintas, lo cual comporta riesgos y oportunidades diferentes respecto a la práctica informacional tradicional.
El análisis de Authoritas revela que sitios que tradicionalmente ocupan la primera posición en Google pueden llegar a perder alrededor del 79 % del tráfico de búsqueda si su enlace aparece por debajo de un AI Overview
Un reciente estudio del Pew Research Center, que analizó el comportamiento de navegación de 900 adultos estadounidenses durante marzo de 2025 (con más de 68 000 búsquedas en Google), alerta sobre el impacto profundo de la función AI Overviews de Google en el tráfico web y los medios informativos. Según este análisis, aproximadamente un 18 % de las búsquedas activan un resumen AI generado por Google, y solo un 8 % de los usuarios hacen clic en enlaces a sitios externos tras ver uno de estos resúmenes, frente al 15 % sin resumen AI. Además, apenas el 1 % de los usuarios clickea cualquiera de los enlaces internos presentes dentro del propio resumen AI, lo que evidencia que estos resúmenes actúan como bloqueadores de tráfico efectivo a los sitios originales
Asimismo, estudios de otros medios como Windows Central y The Guardian subrayan también que los usuarios reciben información satisfactoria directamente en el resultado AI, reduciendo su incentivo para entrar en los sitios originales, lo cual pone en riesgo el modelo económico basado en ingresos por tráfico y publicidad en línea.
En cuanto a los contenidos que sobreviven mejor a este cambio, Wikipedia, YouTube y Reddit lideran como fuentes citadas por los AI Overviews, representando entre el 15 % y el 17 % de las fuentes incluidas en los propios resúmenes y resultados tradicionales, lo que refuerza una concentración de atención en unas pocas plataformas dominantes
Frente a estas tendencias, Google ha cuestionado los métodos del estudio de Pew, calificándolos como poco representativos, y sostiene que no ha detectado una caída sustancial del tráfico global. Sin embargo, parece contradictorio que al mismo tiempo busque acuerdos de licencias con grandes medios informativos, algo que sugiere que reconoce que sus funciones AI están utilizando contenidos sin generar tráfico directo a los creadores originales
Athena Chapekis & Anna Lieb, Google users are less likely to click on links when an AI summary appears in the results, Pew Research Center, 22 de julio de 2025. Disponible en: https://pewrsr.ch/4lIqbsM
El comportamiento de los usuarios de Google cambia cuando se presentan resúmenes generados por inteligencia artificial (IA) en los resultados de búsqueda. Estos “AI Overviews” fueron introducidos por Google en 2024 y actualmente están disponibles para millones de usuarios en EE. UU. La función consiste en un resumen generado por IA que aparece en la parte superior de muchas páginas de resultados, sintetizando la información de diversas fuentes, y ha sido motivo de preocupación entre editores y creadores de contenido digital, quienes han notado una caída significativa en el tráfico hacia sus sitios web.
El estudio analizó el comportamiento de 900 adultos estadounidenses durante marzo de 2025, quienes consintieron en compartir sus datos de navegación. Una de las principales conclusiones fue que los usuarios interactúan menos con los enlaces cuando aparece un resumen de IA. En concreto, solo el 8 % de los usuarios hizo clic en algún enlace tradicional en búsquedas con resumen de IA, frente al 15 % de clics en búsquedas sin resumen. Aún más llamativo es que solo el 1 % de los usuarios hizo clic en los enlaces incluidos dentro del propio resumen generado por IA.
Además, estas búsquedas con resumen de IA también tienden a ser más “finales”: en el 26 % de los casos, los usuarios finalizaron su sesión después de leer el resumen, sin navegar más allá de la página de resultados. En contraste, solo el 16 % de los usuarios abandonó la búsqueda tras consultar una página con resultados tradicionales. Esto sugiere que los resúmenes de IA están cumpliendo su función de ofrecer respuestas rápidas y satisfactorias, aunque esto esté teniendo un costo directo sobre el tráfico hacia otros sitios web.
El estudio también exploró qué tipo de consultas tienden a activar la generación de estos resúmenes por parte de Google. En total, el 18 % de todas las búsquedas realizadas en marzo de 2025 generaron un resumen de IA. No obstante, esta cifra varía ampliamente en función de la longitud y la forma de la consulta. Las búsquedas más extensas (de 10 palabras o más) generaron resúmenes en un 53 % de los casos, mientras que las consultas de una o dos palabras solo lo hicieron en un 8 %.
Asimismo, las búsquedas que incluían preguntas explícitas (“quién”, “qué”, “cuándo”, “por qué”) generaron resúmenes en el 60 % de los casos, y aquellas formuladas como oraciones completas (que contienen al menos un sustantivo y un verbo) lo hicieron en un 36 % de las ocasiones. Esto indica que los algoritmos de IA de Google están más activos cuando la intención de búsqueda es clara, informativa y bien definida.
En cuanto a las fuentes utilizadas para componer los resúmenes, el informe señala que las más citadas son Wikipedia, YouTube y Reddit, que representan el 15 % de las fuentes referenciadas en los resúmenes y un 17 % en los resultados tradicionales. Sin embargo, en los resúmenes de IA es más frecuente encontrar vínculos a sitios gubernamentales (.gov), representando un 6 % de los enlaces, frente al 2 % en los resultados convencionales. En ambos tipos de resultados, las páginas de noticias ocupan un 5 %.
En promedio, los resúmenes de IA tienen una longitud media de 67 palabras, aunque varían enormemente: el más corto encontrado tenía solo 7 palabras y el más largo llegaba a 369. Un 88 % de estos resúmenes incluía al menos tres fuentes citadas, mientras que solo un 1 % se apoyaba en una sola fuente.
El informe pone en evidencia una transformación significativa en la forma en que los usuarios interactúan con Google. Aunque los resúmenes de IA pueden ofrecer comodidad y rapidez, reducen de forma notable la visibilidad y el acceso a las fuentes originales de información, lo que afecta especialmente a medios de comunicación, páginas educativas, blogs y todo tipo de creadores de contenido que dependen del tráfico web para sostenerse económicamente.
Este fenómeno plantea preguntas importantes sobre el futuro de la web abierta, la transparencia de los sistemas de IA y el equilibrio entre ofrecer respuestas eficientes y mantener un ecosistema digital sostenible y diverso.
El artículo analiza una transformación radical que está ocurriendo en el mundo digital: la llegada de navegadores web impulsados por inteligencia artificial que pretenden eliminar el modelo tradicional de navegación basado en clics. Esta revolución está liderada por empresas como Perplexity y OpenAI, que buscan desafiar directamente el dominio de Google Chrome y transformar fundamentalmente cómo interactuamos con internet.
La empresa Perplexity ha lanzado oficialmente Comet, un navegador web revolucionario que funciona más como una conversación que como un sistema de navegación tradicional. Este navegador representa un cambio paradigmático, ya que está diseñado para funcionar como ChatGPT pero con capacidades de navegación integradas. Comet promete actuar como un «segundo cerebro» que puede realizar investigaciones activas, comparar opciones, realizar compras, proporcionar resúmenes diarios y analizar información de manera autónoma, todo sin necesidad de que el usuario navegue a través de múltiples pestañas o enlaces.
El concepto detrás de Comet se basa en la evolución de la inteligencia artificial agentiva, un campo de vanguardia donde los sistemas de IA no solo responden preguntas o generan texto, sino que pueden realizar de forma autónoma una serie de acciones y tomar decisiones para lograr los objetivos del usuario. En lugar de requerir que el usuario especifique cada paso, un navegador agéntico busca comprender la intención del usuario y ejecutar tareas de múltiples pasos, funcionando efectivamente como un asistente inteligente dentro del entorno web.
La aparición de Comet representa una confrontación directa con Google Chrome, que durante décadas ha sido el portal dominante que forma cómo miles de millones de personas navegan por la web. Todo el modelo de Chrome está construido para maximizar la interacción del usuario y, por consecuencia, los ingresos publicitarios. Comet está intentando destruir este modelo, desafiando fundamentalmente la economía de internet basada en la publicidad.
OpenAI, la empresa creadora de ChatGPT, también está preparando su propio navegador web impulsado por IA, que podría lanzarse próximamente según reportes de Reuters. Esta herramienta probablemente integrará el poder de ChatGPT con Operator, el agente web propietario de OpenAI. Operator es un agente de IA capaz de realizar tareas de forma autónoma a través de interacciones con el navegador web, utilizando modelos avanzados para navegar sitios web, llenar formularios, realizar pedidos y gestionar otras tareas repetitivas basadas en el navegador.
El diseño de Operator le permite «observar» las páginas web como lo haría un humano, haciendo clic, escribiendo y desplazándose, con el objetivo de manejar eventualmente la «cola larga» de casos de uso digital. Si se integra completamente en un navegador de OpenAI, podría crear una alternativa completa a Google Chrome y Google Search en un movimiento decisivo, atacando a Google desde ambos extremos: la interfaz del navegador y la funcionalidad de búsqueda.
La propuesta de Perplexity es simple pero provocativa: la web debería responder a los pensamientos del usuario, no interrumpirlos. La empresa sostiene que internet se ha convertido en la mente extendida de la humanidad, pero las herramientas para usarla siguen siendo primitivas. En lugar de navegar a través de pestañas infinitas y perseguir hipervínculos, Comet promete funcionar basándose en el contexto, permitiendo a los usuarios pedir comparaciones de planes de seguros, resúmenes de oraciones confusas o encontrar instantáneamente productos que olvidaron marcar como favoritos.
Esta transformación podría significar el fin de la optimización tradicional para motores de búsqueda (SEO) y la muerte de los familiares «enlaces azules» de los resultados de búsqueda. Los navegadores de IA como Comet no solo amenazan a editores individuales y su tráfico, sino que directamente amenazan los fundamentos del ecosistema de Google Chrome y el dominio de Google Search, que depende en gran medida de dirigir a los usuarios a sitios web externos.
Google Search ya ha estado bajo considerable presión de startups nativas de IA como Perplexity y You.com. Sus propios intentos de integración más profunda de IA, como la Experiencia Generativa de Búsqueda (SGE), han recibido críticas por producir a veces «alucinaciones» (información incorrecta) y resúmenes inadecuados. Simultáneamente, Chrome está enfrentando su propia crisis de identidad, atrapado entre tratar de preservar su masivo flujo de ingresos publicitarios y responder a una oleada de alternativas impulsadas por IA que no dependen de enlaces o clics tradicionales para entregar información útil.
Si Comet o el navegador de OpenAI tienen éxito, el impacto no se limitará solo a interrumpir la búsqueda, sino que redefinirá fundamentalmente cómo funciona toda la internet. Los editores, anunciantes, minoristas en línea e incluso las empresas de software tradicionales pueden encontrarse desintermediados por agentes de IA que pueden resumir su contenido, comparar sus precios, ejecutar sus tareas y evitar completamente sus sitios web e interfaces existentes.
Esta transformación representa un nuevo frente de alto riesgo en la guerra por cómo los humanos interactúan con la información y conducen sus vidas digitales. El navegador de IA ya no es un concepto hipotético: es una realidad presente que está redefiniendo el panorama digital tal como lo conocemos.
La hegemonía de Google en el campo de las búsquedas online está enfrentando una transformación sin precedentes. Según Search Engine Land, la cuota de mercado de Google en Estados Unidos cayó por debajo del 90 % en 2024, marcando una ruptura con más de dos décadas de dominio prácticamente absoluto (Sterling 2024).
La cuota de mercado de búsquedas de Google en EE. UU. alcanzó un pico del 90,37% en noviembre, pero cayó al 87,39% en diciembre. En el resto de los meses de 2024, la cuota de mercado de Google en EE. UU. fue bastante constante, oscilando entre el 86% y el 88%.
Esta disminución se relaciona directamente con la emergencia de nuevas herramientas basadas en inteligencia artificial, como ChatGPT, Perplexity o el nuevo motor de búsqueda de Microsoft impulsado por Copilot, que están redefiniendo las expectativas de los usuarios sobre lo que significa «buscar» en Internet. Así lo pone de relieve el estudio de Search Engine Land, que apunta según una encuesta que el 83% de las personas prefieren herramientas de inteligencia artificial frente a motores de búsqueda tradicionales
La tendencia se ve reforzada por un estudio reciente de Statista que muestra que los jóvenes de entre 18 y 24 años cada vez recurren más a plataformas como TikTok y Reddit para informarse, desplazando a Google como primera fuente de descubrimiento de contenidos. Según un artículo de The Verge, estas plataformas ofrecen resultados más “visuales, personales y reales”, lo cual resuena con una generación que valora la inmediatez, la experiencia del usuario y el contenido generado por personas reales.
Además, el exceso de anuncios y el abuso del SEO en Google han deteriorado la calidad percibida de los resultados. Muchos usuarios sienten que las primeras páginas están dominadas por intereses comerciales antes que por la relevancia informativa. Como apunta un análisis de Wired (2024), esta percepción ha motivado a millones de usuarios a buscar alternativas más limpias, rápidas y conversacionales, como las respuestas generadas por IA, que eliminan el ruido publicitario y ofrecen síntesis directas y comprensibles.
En este contexto, la búsqueda evoluciona de un modelo de enlaces hacia un modelo de respuestas. La inteligencia artificial no solo facilita una búsqueda más eficiente, sino que también transforma el hábito de consumo de información, integrándose en asistentes personales, navegadores y dispositivos móviles con capacidades proactivas. Para Google, este cambio representa un desafío existencial: reinventar su modelo de negocio para seguir siendo competitivo sin alienar a sus usuarios ni depender excesivamente de la publicidad.
Las búsquedas mediante inteligencia artificial están redefiniendo el panorama digital. Aunque aún hay obstáculos que superar —como la precisión de las respuestas y la necesidad de una mayor transparencia—, la tendencia apunta a que cada vez más personas usarán estas herramientas como complemento o sustituto de los buscadores tradicionales.
Las ventajas que los usuarios encuentran en las búsquedas impulsadas por IA incluyen la posibilidad de recibir respuestas directas, precisas y resumidas, sin tener que hacer clic en múltiples enlaces. La IA permite interactuar con el buscador mediante lenguaje natural, lo que facilita la comprensión y la personalización de las consultas. Además, estas herramientas reducen el “ruido SEO” —contenido optimizado artificialmente para posicionarse—, ofreciendo resultados que los usuarios perciben como más auténticos y útiles.
Sin embargo, la adopción de la búsqueda con IA no está exenta de desafíos. Uno de los más mencionados es el fenómeno de las «alucinaciones«: respuestas incorrectas o inventadas que algunas IA pueden generar. Modelos como GPT-4, si bien avanzados, todavía muestran fallos en la precisión de ciertos datos. Por ello, aunque la mayoría de usuarios prefieren este tipo de búsqueda, solo el 38 % afirma confiar plenamente en las respuestas generadas por IA. En consecuencia, muchas personas combinan ambas formas de búsqueda: utilizan IA para obtener una visión general rápida y motores tradicionales cuando buscan información muy específica o actualizada.
Expertos como Nick Reese, exdirector de tecnología del Departamento de Seguridad Nacional de EE.UU., señalan que la IA no reemplazará totalmente a la búsqueda tradicional, sino que convivirá con ella en un modelo híbrido. De hecho, Google ya ha comenzado a integrar resúmenes generados por IA en sus resultados, en un esfuerzo por no perder terreno ante estas nuevas herramientas. Las búsquedas con IA se utilizan especialmente para investigar un tema, redactar textos o entender conceptos complejos, mientras que Google sigue siendo dominante en áreas como noticias, productos o ubicaciones.
Se analiza cómo la adopción masiva de buscadores basados en IA —como ChatGPT, Perplexity o los «AI Overviews» de Google— está transformando profundamente la estructura y el funcionamiento tradicionales de la web. Según Daoudi, el usuario actual prefiere respuestas integradas directamente en los resultados en lugar de navegar entre múltiples enlaces; sin embargo, esta tendencia puede generar una crisis de transparencia en la información, ya que no siempre se sabe cómo se priorizan las fuentes o cuáles se están utilizando .
El autor advierte sobre el riesgo de que estas plataformas “rompan” la web al consolidar respuestas sin referencia clara a las fuentes originales. Frente a este desafío, subraya la pérdida de control del usuario sobre la veracidad y el contexto, a medida que el sistema se comporta como una «caja negra» que fusiona múltiples contenidos inconsistentes o sesgados. Se plantea la pregunta crítica: ¿quién decide qué información se muestra y en qué orden? .
Daoudi propone que el futuro de la búsqueda debe evolucionar hacia una estructura híbrida que combine lo mejor del modelo tradicional (enlaces y rastreo) con la inteligencia contextual de la IA. Sugiere que los portales de búsqueda necesitan ofrecer:
Transparencia: mostrar claramente las fuentes utilizadas, y cómo la IA seleccionó y sintetizó la información.
Control del usuario: brindar opciones para que los usuarios exploren más en profundidad (por ejemplo, desgloses fuente por fuente).
Retroalimentación activa: permitir al usuario participar en la mejora continua del sistema, señalando errores o preferencias.
El artículo también sitúa este fenómeno dentro de un contexto más amplio: la economía web está siendo redefinida por el desplazamiento de clics y tráfico hacia respuestas directas de IA, lo que ha provocado preocupación entre editores y creadores de contenido por los impactos en ingresos publicitarios y visibilidad. Además, la dependencia creciente de agentes generativos plantea interrogantes legales ligados a derechos de autor, compensación justa y transparencia algorítmica.
Se advierte que la revolución de la búsqueda potenciada por IA tiene un enorme potencial para mejorar la experiencia de usuario, pero también conlleva riesgos significativos: desinformación, pérdida de visibilidad para creadores de contenido y opacidad en los procesos de decisión. Por ello, propone una evolución hacia sistemas híbridos que integren fiabilidad, trazabilidad, participación activa del usuario y regulación informada.