De-Moya-Anegón, Félix; Sánchez-Jiménez, Rodrigo; Halevi, Gali; Guerrero-Bote, Vicente P.; Guerrero-Castillo, Pablo; Rivadeneyra, Federico (2026). A Comparative Analysis of Open and Commercial Bibliographic Infrastructures: Scale, Metadata Standardization, and Implications for Bibliometric Evaluation. Granada: Ediciones Profesionales de la Información, 48 pp. ISBN: 978-84-125757-8-1
El informe analiza la viabilidad estructural de las infraestructuras bibliográficas abiertas para su uso en evaluación de la investigación, comparándolas con bases de datos comerciales como Scopus en aspectos clave como cobertura, calidad de metadatos, interoperabilidad y utilidad en flujos de trabajo bibliométricos. El contexto está marcado por el impulso de marcos políticos recientes como CoARA y la Declaración de Barcelona, que promueven una transición hacia datos de investigación abiertos. Sin embargo, el estudio muestra que esta transición no es lineal, ya que existe una tensión estructural entre la enorme escala de las plataformas abiertas y la estandarización de sus metadatos, lo que genera un dilema entre cobertura masiva y consistencia analítica.
Las plataformas abiertas como OpenAIRE, OpenAlex y The Lens superan ampliamente a Scopus en volumen de registros, pero este crecimiento se produce a costa de una menor calidad y completitud de los metadatos. Problemas como la ausencia de afiliaciones en más del 55% de los registros, la baja normalización de identificadores como ISSN y DOI, y una clasificación documental excesivamente algorítmica afectan directamente a su aplicabilidad en evaluación institucional. Esta situación limita su uso directo en bibliometría, especialmente en análisis comparativos entre instituciones o países.
El informe también destaca una dinámica asimétrica en los flujos de citación: el “long tail” de las bases abiertas no redistribuye de forma equilibrada el impacto científico, sino que tiende a reforzar la centralidad de la literatura ya indexada en bases comerciales. En otras palabras, la ampliación del corpus abierto no se traduce automáticamente en una democratización del impacto científico, sino que en muchos casos consolida estructuras previas de visibilidad. A ello se suman desigualdades geográficas persistentes, con mejoras en regiones como América Latina y África, pero con importantes vacíos en Asia y Oriente Medio, además de déficits en tipologías documentales complejas como monografías de humanidades o actas de congresos.
Por otro lado, las plataformas abiertas enfrentan importantes compromisos estructurales: The Lens presenta dificultades en la estandarización global de metadatos, registrando las tasas más bajas de presencia de ISSN y DOI y un déficit del 71,67% en la captura de actas de congresos. OpenAlex depende en gran medida de datos de origen no estructurados, con un 41,5% de sus registros (con fuente) sin ISSN, y presenta un posible sesgo analítico debido a la sobre-etiquetación algorítmica de documentos como «artículos». Finalmente, OpenAIRE presenta anomalías técnicas relevantes, incluyendo más de un millón de DOI duplicados y la tasa más alta de documentos no clasificados (23,1%) dentro del núcleo curado, lo que resulta en el menor ratio global de impacto de citación del grupo.
Finalmente, el estudio subraya que cada plataforma abierta presenta fortalezas y debilidades específicas: The Lens destaca por su integración con patentes y su utilidad en análisis de transferencia tecnológica; OpenAlex por su alta alineación con registros de Scopus y su densidad de citación en el núcleo coincidente; y OpenAIRE por su mayor cobertura de identificadores persistentes y menor ausencia de afiliaciones. Sin embargo, todas comparten limitaciones estructurales cuando se utilizan sin procesos rigurosos de normalización y depuración. La conclusión central es que el acceso abierto a grandes volúmenes de datos no equivale automáticamente a su validez evaluativa, y que el futuro de la evaluación científica abierta depende de pasar de la mera disponibilidad de datos a su validación activa y metodológicamente controlada.
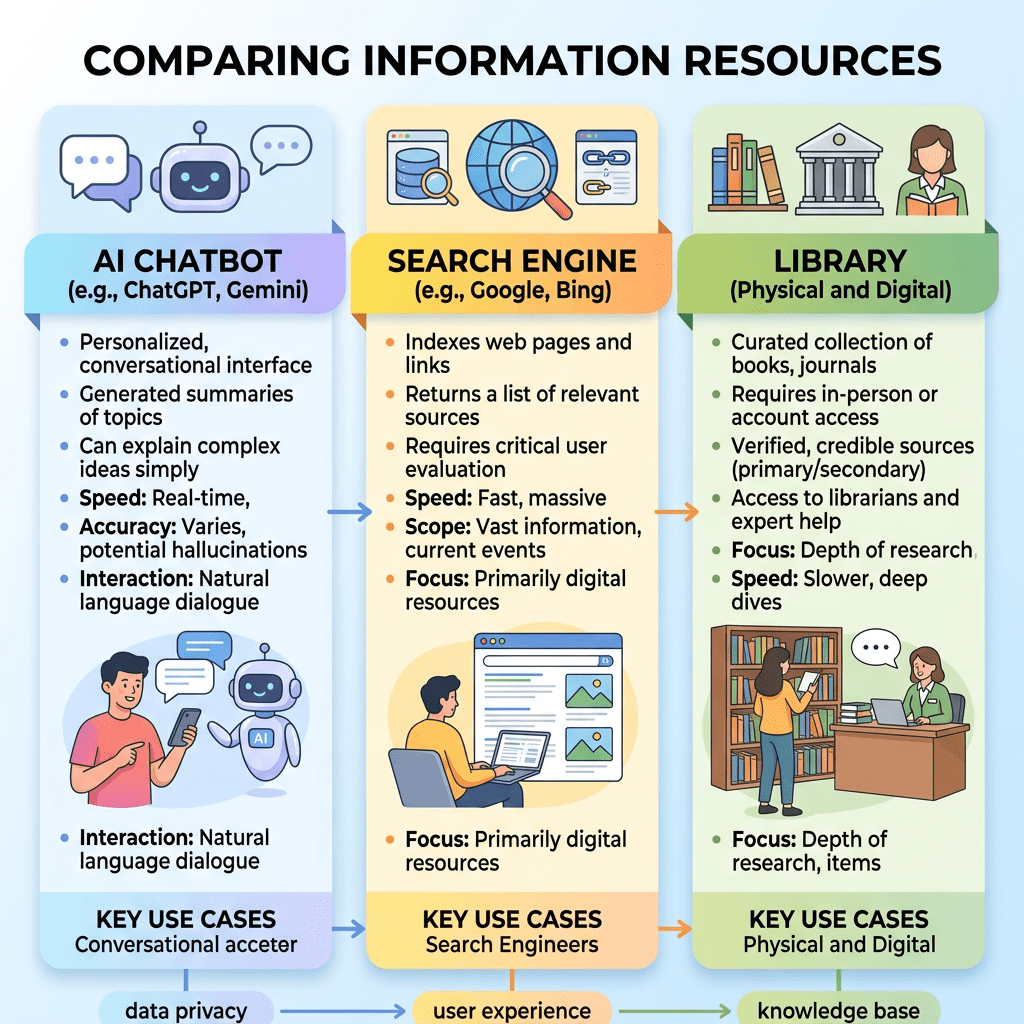
An infographic comparing AI chatbots, search engines, and libraries as information resources.
Lund, Brady D., Zoe Abbie Teel, Ting Wang, et al. “Artificial Intelligence (AI) and Information Seeking: A Comparative Exploration of AI Chatbots, Search Engines, and Library Resources as Information Sources among University Students.” Journal of Librarianship and Information Science (OnlineFirst, 2026). https://doi.org/10.1177/09610006261438484
El artículo retrata un momento de transición en el ecosistema informativo universitario. La IA no ha desplazado a Google ni a las bibliotecas, pero ya se ha incorporado de forma visible a las rutinas académicas. Su papel es complementario, aunque en expansión, especialmente entre estudiantes jóvenes e internacionales. Para las bibliotecas y universidades, el reto no consiste en resistirse al cambio, sino en liderarlo: integrar la IA de forma ética, crítica y conectada con recursos académicos de calidad.
Este estudio analiza cómo los estudiantes universitarios de Estados Unidos están integrando la inteligencia artificial generativa en sus prácticas de búsqueda académica. A partir de una encuesta electrónica respondida por 236 estudiantes de perfiles diversos, los autores comparan el uso, preferencia y satisfacción con tres grandes fuentes de información: motores de búsqueda tradicionales (como Google), recursos bibliotecarios universitarios y herramientas de IA conversacional como ChatGPT. El trabajo parte de la idea de que la irrupción de la IA está modificando profundamente la ecología informacional en la educación superior, alterando la manera en que los estudiantes localizan, evalúan y utilizan información.
Los resultados muestran que los motores de búsqueda siguen siendo la herramienta dominante para tareas académicas, tanto por frecuencia de uso como por preferencia inicial al comenzar una investigación. Casi la mitad de los estudiantes indicaron que Google o buscadores similares son su primera opción, mientras que el resto se divide entre los recursos de biblioteca y la IA. Sin embargo, la IA ya ocupa un lugar significativo: solo un 15% declaró no haberla usado nunca para fines académicos, mientras que cerca del 10% la utiliza diariamente. Esto indica que la IA no ha sustituido aún a las herramientas tradicionales, pero sí se ha convertido en una pieza estable del repertorio informacional estudiantil.
Uno de los hallazgos más relevantes es la existencia de diferencias demográficas marcadas. Los estudiantes más jóvenes muestran mayor inclinación hacia la IA como punto de partida en sus búsquedas, mientras que los mayores prefieren claramente las páginas web de bibliotecas universitarias. Asimismo, los estudiantes internacionales utilizan la IA con mucha mayor frecuencia que los estudiantes nacionales estadounidenses. De hecho, recurren menos a los recursos bibliotecarios y más a herramientas de IA, lo que los autores interpretan como posible consecuencia de barreras idiomáticas, desconocimiento del entorno bibliotecario estadounidense o búsqueda de interfaces más accesibles y conversacionales.
En cuanto a la percepción de calidad, los buscadores tradicionales siguen obteniendo mejores puntuaciones globales que la IA en relevancia y satisfacción de resultados. Los estudiantes consideran especialmente eficaces a los buscadores para noticias recientes, meteorología e información laboral. En cambio, la IA obtiene valoraciones más competitivas cuando se trata de ayuda académica, preparación de exámenes, comprensión inicial de un tema o generación de instrucciones para realizar tareas. Esto sugiere que los usuarios perciben fortalezas diferenciadas: el buscador como herramienta de acceso a fuentes actualizadas y múltiples perspectivas, y la IA como asistente para sintetizar, orientar o explicar.
El estudio también demuestra una relación clara entre uso frecuente y satisfacción con la IA. Cuanto más emplea un estudiante estas herramientas, mayor es su percepción de utilidad. Los usuarios intensivos valoran especialmente la IA para tareas educativas, estudio y resolución de procedimientos. Esto puede indicar un aprendizaje progresivo del uso eficaz de la herramienta o una adaptación de expectativas a sus capacidades reales. Los autores advierten, no obstante, que esta relación también podría fomentar dependencia acrítica si los estudiantes aceptan respuestas sintéticas sin contrastarlas con fuentes primarias.
Desde la perspectiva bibliotecaria, el artículo plantea implicaciones estratégicas de gran interés. Las bibliotecas universitarias no deberían contemplar la IA únicamente como una amenaza competitiva, sino como una oportunidad para rediseñar sus servicios. Proponen desarrollar sistemas de descubrimiento apoyados en IA conectados directamente con colecciones licenciadas, bases de datos y contenidos académicos fiables. De este modo, las bibliotecas podrían ofrecer experiencias conversacionales semejantes a ChatGPT, pero sustentadas en recursos evaluados y legales. También subrayan la necesidad urgente de programas de alfabetización informacional y alfabetización en IA, enseñando a los estudiantes a verificar respuestas, identificar sesgos, contrastar perspectivas y comprender límites de los modelos generativos.
Los autores reconocen algunas limitaciones metodológicas. La muestra estaba sobrerrepresentada por estudiantes de posgrado, internacionales y vinculados a ciencias de la computación e información, lo que puede inflar los niveles generales de adopción tecnológica. Además, el estudio se basa en autoinformes y no en observación directa del comportamiento real. Por ello recomiendan investigaciones futuras con muestras más representativas, entrevistas cualitativas y estudios experimentales que analicen cómo los estudiantes combinan IA, buscadores y biblioteca ante necesidades concretas de información.
Apéndice. Encuesta sobre IA y búsqueda de información
1. ¿Cuál de las siguientes opciones describe mejor tu especialidad académica? a. Artes – bellas artes, música, danza, fotografía b. Humanidades – filosofía, historia, literatura, lenguas c. Ciencias Sociales – psicología, sociología, economía, educación, biblioteconomía d. Ciencias Naturales – biología, química, matemáticas, ecología, ingeniería e. Ciencias de la Computación – informática, ciencia de la información, ciencia de datos, IA f. Empresa – administración, hostelería, sistemas y ciencias de la decisión, marketing
2. ¿Cuál es tu nivel académico actual? a. Estudiante de grado b. Estudiante de máster c. Estudiante de doctorado
3. ¿Cuál es tu edad? a. 18–25 b. 26–30 c. 31–35 d. 36 o más
4. ¿Cuál es tu género? a. Mujer b. Hombre c. No binario d. Otro
5. ¿Cuál describe mejor tu situación como estudiante? a. Estudiante nacional b. Estudiante internacional
6. Pensando específicamente en tus actividades académicas y/o experiencias de investigación, indica con qué frecuencia utilizas cada una de las siguientes fuentes de información (nunca, menos de una vez al mes, mensualmente, semanalmente, diariamente): a. Libros b. Revistas científicas c. Actas de congresos d. Recursos web e. Bases de datos bibliotecarias f. Comunicaciones personales g. Herramientas de IA generativa
7. Pensando específicamente en tus actividades académicas y/o experiencias de investigación, ¿qué grado de confianza tienes en que encuentras toda la información necesaria sobre un tema cuando utilizas los siguientes recursos? (nada confiado, poco confiado, neutral, bastante confiado, muy confiado): a. Libros b. Revistas científicas c. Actas de congresos d. Recursos web e. Bases de datos bibliotecarias f. Comunicaciones personales g. Herramientas de IA generativa
8. ¿Cuál de las siguientes interfaces preferirías utilizar al comenzar tu búsqueda de información? a. Página principal de la biblioteca b. Google/motor de búsqueda c. Chatbot de IA/modelo de lenguaje grande
9. ¿Cuántas veces has realizado las siguientes actividades durante el último mes? a. Visitado la biblioteca universitaria, utilizado la web de la biblioteca o accedido a recursos bibliotecarios mediante enlaces web. b. Utilizado Google u otro motor de búsqueda similar para actividades o tareas universitarias. c. Utilizado una herramienta de IA para actividades o tareas universitarias.
10. Al realizar una tarea concreta de búsqueda de información relacionada con estudios o investigación, ¿con qué frecuencia recurres a los siguientes enfoques? (nunca, raramente, a veces, a menudo, siempre): a. Utilizar solo un motor de búsqueda tradicional b. Utilizar solo un chatbot de IA/ChatGPT c. Primero utilizar un motor de búsqueda tradicional y después un chatbot de IA/ChatGPT d. Primero utilizar un chatbot de IA/ChatGPT y después un motor de búsqueda tradicional
11. Pensando en la información que buscas en tu vida diaria, ¿qué probabilidad hay de que uses un motor de búsqueda tradicional para lo siguiente? (muy improbable, algo improbable, ni probable ni improbable, algo probable, muy probable): a. Encontrar información relacionada con empleo b. Encontrar información relacionada con estudios c. Aprender más sobre un tema que estudias d. Consultar el tiempo e. Ponerte al día con noticias recientes f. Crear chistes o historias g. Crear un conjunto de instrucciones para completar una tarea
12. Pensando en la información que buscas en tu vida diaria, ¿qué probabilidad hay de que uses chatbots de IA/ChatGPT para lo siguiente? (muy improbable, algo improbable, ni probable ni improbable, algo probable, muy probable): a. Encontrar información relacionada con empleo b. Encontrar información relacionada con estudios c. Aprender más sobre un tema que estudias d. Consultar el tiempo e. Ponerte al día con noticias recientes f. Crear chistes o historias g. Crear un conjunto de instrucciones para completar una tarea
13. Cuando buscas cada uno de los siguientes tipos de información, ¿con qué frecuencia un motor de búsqueda es capaz de generar una respuesta relevante? Nota: relevante significa únicamente que proporciona información pertinente sobre el tema, no necesariamente que sea exacta o satisfactoria para ti. (nunca, no muy a menudo, con cierta frecuencia, muy a menudo, siempre): a. Encontrar información relacionada con empleo b. Encontrar información relacionada con estudios c. Aprender más sobre un tema que estudias d. Consultar el tiempo e. Ponerte al día con noticias recientes f. Crear chistes o historias g. Crear un conjunto de instrucciones para completar una tarea
14. Cuando buscas cada uno de los siguientes tipos de información, ¿con qué frecuencia un chatbot de IA/ChatGPT es capaz de generar una respuesta relevante? Nota: relevante significa únicamente que proporciona información pertinente sobre el tema, no necesariamente que sea exacta o satisfactoria para ti. (nunca, no muy a menudo, con cierta frecuencia, muy a menudo, siempre): a. Encontrar información relacionada con empleo b. Encontrar información relacionada con estudios c. Aprender más sobre un tema que estudias d. Consultar el tiempo e. Ponerte al día con noticias recientes f. Crear chistes o historias g. Crear un conjunto de instrucciones para completar una tarea
15. Cuando buscas cada uno de los siguientes tipos de información, ¿con qué frecuencia un motor de búsqueda tradicional es capaz de generar una respuesta satisfactoria? Nota: una respuesta satisfactoria es aquella que cubre completamente la información que necesitas y con la que quedas satisfecho/a. (nunca, no muy a menudo, con cierta frecuencia, muy a menudo, siempre): a. Encontrar información relacionada con empleo b. Encontrar información relacionada con estudios c. Aprender más sobre un tema que estudias d. Consultar el tiempo e. Ponerte al día con noticias recientes f. Crear chistes o historias g. Crear un conjunto de instrucciones para completar una tarea
16. Cuando buscas cada uno de los siguientes tipos de información, ¿con qué frecuencia un chatbot de IA/ChatGPT es capaz de generar una respuesta satisfactoria? Nota: una respuesta satisfactoria es aquella que cubre completamente la información que necesitas y con la que quedas satisfecho/a. (nunca, no muy a menudo, con cierta frecuencia, muy a menudo, siempre): a. Encontrar información relacionada con empleo b. Encontrar información relacionada con estudios c. Aprender más sobre un tema que estudias d. Consultar el tiempo e. Ponerte al día con noticias recientes f. Crear chistes o historias g. Crear un conjunto de instrucciones para completar una tarea
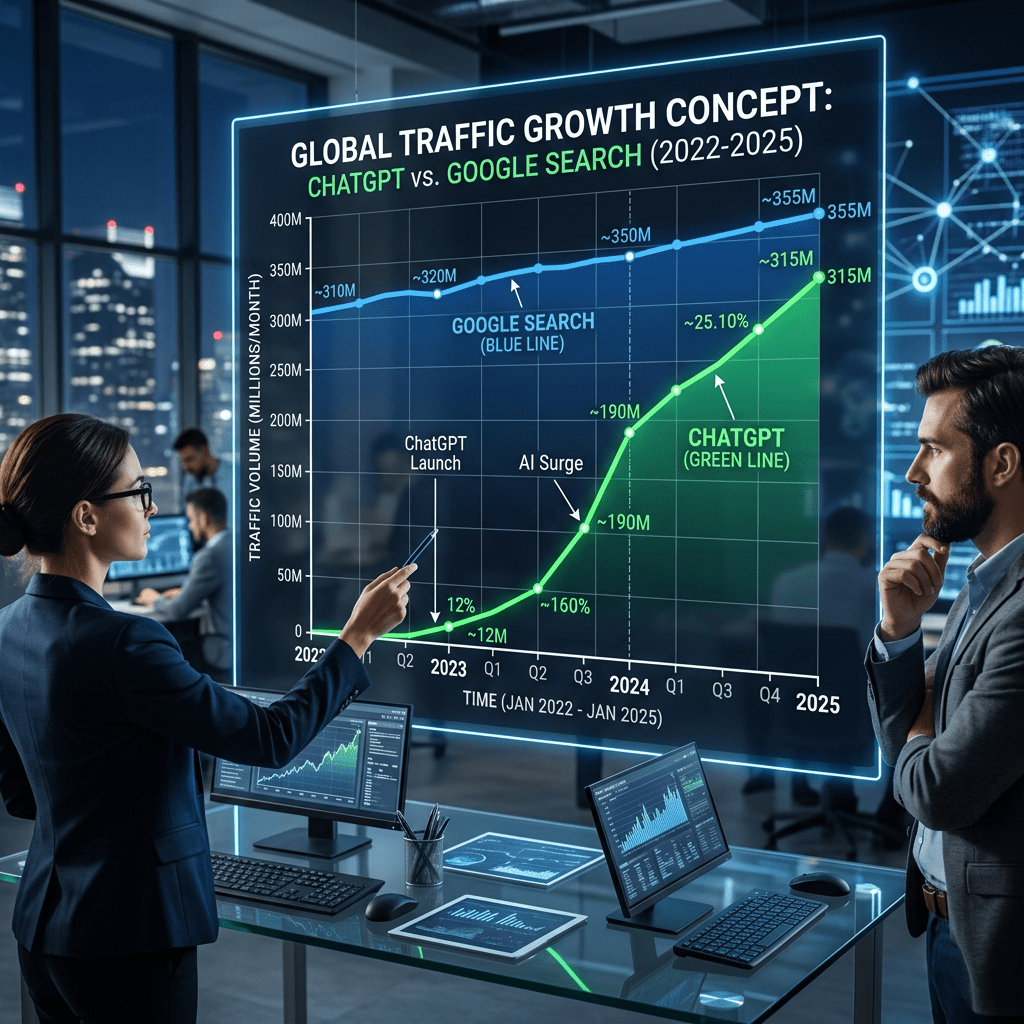
El artículo analiza el impacto creciente de ChatGPT y otras herramientas de inteligencia artificial en el ecosistema del tráfico web, comparándolo con el dominio tradicional de Google. La principal conclusión es que, aunque Google sigue siendo el actor dominante en términos absolutos, el crecimiento de ChatGPT está redefiniendo el modo en que los usuarios acceden a la información. La investigación muestra que ChatGPT ya genera un volumen significativo de tráfico equivalente a una parte relevante del ecosistema de búsqueda global, consolidándose como el segundo gran canal de descubrimiento digital.
Uno de los aspectos más relevantes del estudio es el cambio estructural en el comportamiento de los usuarios. Cada vez más personas utilizan herramientas de IA no solo como complemento, sino como punto de partida para sus búsquedas, especialmente en contextos de investigación previa (por ejemplo, en procesos de compra o toma de decisiones). Esto implica que muchas interacciones informativas ya no pasan por los motores de búsqueda tradicionales, lo que reduce la visibilidad de los sitios web en Google y desplaza parte del tráfico hacia entornos conversacionales.
Sin embargo, el artículo también subraya que este crecimiento no implica una sustitución inmediata de Google. De hecho, el volumen total de búsquedas en internet sigue aumentando, lo que indica que ambos modelos —búsqueda tradicional y búsqueda asistida por IA— están coexistiendo dentro de un ecosistema más amplio de “descubrimiento de información”. Lo que sí está cambiando es la cuota relativa: Google pierde peso porcentual aunque no necesariamente tráfico absoluto, mientras que la IA gana protagonismo rápidamente.
Otro punto clave es la calidad del tráfico generado por ChatGPT. Aunque su volumen aún es menor, algunos estudios indican que los usuarios que llegan desde herramientas de IA pueden tener una intención más definida, lo que podría traducirse en mejores tasas de conversión en determinados contextos. No obstante, otros análisis matizan esta idea y señalan que, en ciertos sectores como el comercio electrónico, el tráfico procedente de ChatGPT todavía rinde peor que el de Google en términos de ingresos y conversión.
Finalmente, el artículo destaca las implicaciones estratégicas para el SEO y el marketing digital. La visibilidad ya no depende únicamente de posicionarse en Google, sino también de aparecer en las respuestas generadas por sistemas de IA. Esto introduce un nuevo paradigma —a veces denominado “Answer Engine Optimization”— en el que las marcas deben adaptarse a un entorno donde las respuestas directas sustituyen parcialmente a los listados de enlaces. En este nuevo escenario, no estar presente en las respuestas de IA puede significar perder oportunidades antes incluso de que el usuario llegue a realizar una búsqueda tradicional.
En conjunto, el texto plantea una transformación profunda del ecosistema informativo: no se trata de la desaparición de Google, sino de la emergencia de un modelo híbrido donde la inteligencia artificial redefine cómo, cuándo y desde dónde accedemos al conocimiento.
Datos clave del estudio
Crecimiento del tráfico El tráfico de referencia desde ChatGPT creció un 206% entre enero de 2025 y enero de 2026.
Destino del tráfico Google recibe el 21,6% de todo el tráfico que ChatGPT envía a otros sitios. Es decir, uno de cada cinco clics desde ChatGPT termina en Google.
Concentración del tráfico Los 10 principales dominios concentran algo más del 30% del tráfico total. Esto indica una fuerte concentración en pocas webs. “Long tail” (larga cola) La mayoría de los sitios web reciben cantidades muy pequeñas de tráfico desde ChatGPT.
Expansión del ecosistema El número de dominios que reciben tráfico desde ChatGPT: Alcanzó un pico de ~260.000 sitios en 2025 Luego se estabilizó en torno a ~170.000 sitios
Interpretación rápida de los datos ChatGPT está creciendo muy rápido, pero el tráfico aún está muy concentrado. Google sigue siendo clave incluso dentro del ecosma de IA (como destino de clics). Hay una democratización aparente (más webs reciben tráfico), pero en la práctica domina una élite de sitios.
Un análisis reciente de la experiencia de uso de Gemini, el modelo de inteligencia artificial de Google, frente a ChatGPT, evidencia diferencias significativas en creatividad, interacción y adaptación al usuario.
Durante una semana de prueba, Gemini demostró ser eficaz en tareas estructuradas, como la programación y la investigación, y ofreció una integración fluida con herramientas del ecosistema Google, incluyendo Docs y Gmail. Sin embargo, su desempeño en contextos que requieren creatividad y fluidez conversacional fue limitado en comparación con ChatGPT, que mantiene un estilo más versátil, expresivo y capaz de generar ideas originales en sesiones de lluvia de ideas o redacción más elaborada.
Otro punto destacado en la comparación es la capacidad de memoria de contexto. Mientras que ChatGPT logra seguir conversaciones largas y mantener la coherencia en proyectos continuos, Gemini mostró dificultades para recordar información previa en interacciones prolongadas, lo que puede afectar la productividad en tareas complejas o colaborativas. Por otro lado, Gemini ofrece ventajas para usuarios integrados en el ecosistema Google, permitiendo automatizar flujos de trabajo administrativos y de investigación de manera más directa, especialmente en la versión de suscripción avanzada Gemini Advanced.
En términos generales, aunque Gemini representa un avance en eficiencia y conectividad con herramientas digitales, ChatGPT sigue siendo superior en términos de creatividad, riqueza conversacional y adaptabilidad a tareas que requieren pensamiento crítico. El análisis sugiere que, mientras Gemini puede ser útil para productividad y tareas técnicas, la interacción con ChatGPT proporciona un valor diferencial en creatividad y generación de contenido original, consolidándose como la herramienta preferida para usuarios que priorizan la profundidad, la innovación y la continuidad en sus proyectos de IA.
ChatGPT destaca por su versatilidad y creatividad, siendo capaz de abordar tareas muy variadas y adaptarse a múltiples idiomas, formatos y estilos de escritura. Por su parte, Copilot está optimizado para la productividad dentro del ecosistema Microsoft 365: integra funciones en Word, Excel, PowerPoint, Outlook y Teams.
Uno de los puntos clave es que ChatGPT soporta una amplia gama de lenguajes de programación y frameworks, mientras que Copilot está especialmente enfocado en entornos de desarrollo de Microsoft y tareas empresariales estructuradas.
En cuanto al modelo de negocio, ambos ofrecen versiones gratuitas, pero se requiere suscripción (por ejemplo, ChatGPT Premium o Copilot Pro/Microsoft 365 Copilot) para acceder a funciones avanzadas.
Calidad de respuesta y fiabilidad
ChatGPT ofrece respuestas más conversacionales, creativas y adaptables, aunque puede no citar fuentes directamente. Copilot, al estar integrado con Bing y el ecosistema Microsoft, tiende a ofrecer respuestas más precisas, con formatos claros, mejor notación matemática y referencias verificables.
Integración con herramientas de trabajo
Copilot ofrece integración directa y profunda con aplicaciones como Microsoft Word, Excel, PowerPoint, Outlook y Teams. Puede analizar datos en Excel (tablas dinámicas, gráficos, fórmulas), generar presentaciones y redactar correos personalizados a partir de hilos de correo o documentos. ChatGPT, aunque puede conectarse a otras herramientas y servicios, requiere configuraciones externas mediante API o Zapier, lo que lo hace más flexible pero menos inmediato para usuarios de Microsoft 365.
Seguridad y entorno empresarial
Copilot se beneficia de las protecciones de seguridad y cumplimiento de Microsoft 365, incluyendo control de datos, gestión empresarial y políticas corporativas. ChatGPT ofrece medidas de seguridad estándar, con características adicionales en la versión Enterprise para entornos profesionales.
Qué herramienta elegir según tus necesidades
Si trabajas ampliamente en el entorno de Microsoft 365 y buscas automatizar tareas repetitivas como gestión de correos, informes o análisis en Excel dentro de un flujo estandarizado, Copilot puede ser la opción más eficiente. Permite realizar tareas rápidamente dentro de la suite (Word, Excel, PowerPoint, Outlook y Teams) sin salir del entorno familiar.
Si en cambio necesitas soluciones creativas, trabajar con múltiples formatos, personalizar respuestas o desarrollar con soporte en múltiples lenguajes y contextos, ChatGPT ofrece mayor flexibilidad y amplitud funcional, especialmente si deseas crear asistentes personalizados o escribir contenido narrativo, técnico o creativo.
En muchos casos, una combinación de ambos es una estrategia efectiva: se puede aprovechar ChatGPT para generación creativa y análisis abierto, mientras que Copilot se usa para flujos de trabajo dentro de Microsoft 365.
Altamura, L., Vargas, C., & Salmerón, L. (2023). «Do New Forms of Reading Pay Off? A Meta-Analysis on the Relationship Between Leisure Digital Reading Habits and Text Comprehension». Review of Educational Research, 0(0). https://doi.org/10.3102/00346543231216463
Un equipo de la Universidad de Valencia analizó más de dos docenas de estudios publicados entre 2000 y 2022, con casi 470 000 participantes. Concluyeron que la lectura en papel mejora las habilidades de comprensión entre seis y ocho veces más que la lectura en dispositivos digitales
Un nuevo estudio realizado por la Universidad de Valencia concluye que la lectura en formato impreso mejora la comprensión lectora entre seis y ocho veces más que la lectura en pantallas. Esta investigación, que analizó más de veinte años de estudios y casi 470 000 participantes, confirma que el papel sigue siendo el medio más eficaz para fomentar una lectura profunda y comprensiva, especialmente en contextos educativos.
Una de las razones principales es que los textos digitales suelen presentar una calidad lingüística inferior. Muchas veces están escritos en un estilo conversacional, como en redes sociales, lo que limita la exposición a estructuras sintácticas complejas, vocabulario académico y razonamientos elaborados. Además, el acto de leer en pantalla tiende a ser más superficial, con un enfoque en el escaneo rápido y fragmentado, lo que perjudica la capacidad de conectar ideas y retener información.
Los resultados varían según la edad de los lectores. En niños de primaria, la lectura digital tiene un efecto claramente negativo sobre la comprensión. En adolescentes y universitarios, aunque la relación se vuelve algo más positiva, sigue siendo menos efectiva que la lectura en papel. Esto se debe en parte a que los lectores más jóvenes aún no dominan estrategias cognitivas que les permitan ignorar las distracciones digitales, mientras que los mayores han desarrollado mayor capacidad de autorregulación.
Los investigadores no están en contra del uso de tecnologías digitales, pero advierten que el aprendizaje profundo —especialmente en edades tempranas— requiere el tipo de atención, ritmo pausado y concentración que fomenta la lectura impresa. Por ello, recomiendan que las escuelas y educadores prioricen los libros físicos para desarrollar sólidas habilidades lectoras antes de introducir de manera intensiva la lectura digital.
En conclusión, aunque las pantallas ofrecen acceso rápido a una gran cantidad de información, no sustituyen las ventajas cognitivas y educativas de leer en papel. Para cultivar una comprensión lectora rica, duradera y crítica, especialmente en estudiantes, el libro impreso sigue siendo la herramienta más poderosa.
El informe de OneLittleWeb, titulado «Are AI Chatbots Replacing Search Engines? A 2-Year Data Study on Web Traffic Trends», analiza la evolución del tráfico web global entre abril de 2023 y marzo de 2025, comparando el uso de motores de búsqueda tradicionales con el de chatbots de inteligencia artificial.
Crecimiento de los Chatbots de IA
Durante el período analizado, los chatbots de IA experimentaron un crecimiento significativo en su tráfico web:
Crecimiento interanual del 80,92%: Pasaron de 30.500 millones de visitas entre abril de 2023 y marzo de 2024 a 55.200 millones en el mismo período de 2024-2025.
Dominio de ChatGPT: Este chatbot lidera el mercado con un 86,32% de participación en el tráfico total de chatbots, seguido por DeepSeek y Gemini.
Crecimiento de nuevos actores: DeepSeek y Grok destacaron por su rápido aumento en visitas, con incrementos del 113.007% y 353.787% respectivamente.
Comparación con los Motores de Búsqueda
A pesar del crecimiento de los chatbots, los motores de búsqueda tradicionales mantienen una posición dominante:
Tráfico total de 1,86 billones de visitas: Entre abril de 2024 y marzo de 2025, los motores de búsqueda registraron una ligera disminución del 0,51% en comparación con el año anterior.
Diferencia en visitas diarias: En marzo de 2025, los motores de búsqueda promediaron 5.500 millones de visitas diarias, mientras que los chatbots alcanzaron 233,1 millones, lo que representa una diferencia de casi 24 veces.
Participación de mercado: Google lidera con un 87,57% del tráfico entre los motores de búsqueda, seguido por Microsoft Bing y Yandex.
Integración de IA en los Motores de Búsqueda
Los motores de búsqueda están incorporando funciones basadas en IA para mejorar la experiencia del usuario:
Google: Ha introducido «AI Overviews» y «AI Mode», que proporcionan respuestas generadas por IA directamente en los resultados de búsqueda
Microsoft Bing: Implementó la «Search Generative Experience (SGE)», que utiliza IA para ofrecer respuestas más completas y contextuales.
Impacto en el Tráfico Web y el SEO
Aunque los chatbots de IA están ganando popularidad, su capacidad para dirigir tráfico a sitios web es limitada
Tasas de clics más bajas: Los chatbots tienen una tasa de clics promedio del 0,33%, en comparación con el 8,63% de los motores de búsqueda tradicionales.
Preocupaciones para los editores: La menor capacidad de los chatbots para generar tráfico directo plantea desafíos para los editores y creadores de contenido que dependen del SEO.
El estudio concluye que, aunque los chatbots de IA están creciendo rápidamente y transformando la forma en que los usuarios interactúan con la información, todavía no están reemplazando a los motores de búsqueda tradicionales. Los motores de búsqueda siguen siendo la principal fuente de acceso a la información en línea, y su integración con tecnologías de IA sugiere una evolución hacia una experiencia de búsqueda más conversacional y personalizada.
Con el auge de los asistentes de inteligencia artificial, elegir el adecuado puede marcar una gran diferencia en términos de productividad, creatividad y eficiencia. Este análisis compara los cuatro líderes del sector según sus puntos fuertes, limitaciones y mejores usos.
ChatGPT (OpenAI): Muy versátil, ideal para tareas generales, redacción creativa y generación de imágenes. Sin embargo, puede perder el hilo en conversaciones largas y ocasionalmente ofrecer información errónea.
Google Gemini: Potente para tareas complejas, análisis profundo y trabajo colaborativo dentro del ecosistema Google. Perfecto para usuarios que manejan grandes volúmenes de datos, aunque puede resultar demasiado formal para usos creativos.
Perplexity AI: Se especializa en investigación en tiempo real, verificación de hechos y análisis de la competencia, con respuestas respaldadas por fuentes. No es tan eficaz en creatividad ni genera imágenes.
Claude AI (Anthropic): Destaca en creatividad, lluvia de ideas y pensamiento estratégico. Tiene una ventana de contexto muy grande (hasta 200.000 tokens), pero no genera imágenes.
Cebrián, Guillem, Ángel Borrego y Ernest Abadal. 2025. «OpenAlex y Crossref como fuentes de datos bibliográficas alternativas a Web of Science y Scopus en ciencias de la salud.» Revista Española de Documentación Científica 48 (1). https://doi.org/10.3989/redc.2025.1.1649.
El artículo analiza el valor de OpenAlex y Crossref como fuentes alternativas a las reconocidas bases de datos Web of Science (WoS) y Scopus, particularmente en el campo de las ciencias de la salud. La motivación surge del creciente uso de WoS y Scopus en procesos de evaluación científica, lo que ha derivado en críticas por su falta de transparencia, sesgos comerciales y limitada cobertura temática y geográfica. En este contexto, los autores exploran si OpenAlex y Crossref pueden ofrecer una cobertura más amplia, representativa y abierta.
Para abordar el primer objetivo, los autores partieron de un listado de revistas categorizadas como «Health Sciences» por Scopus. A partir de este conjunto, analizaron cuántas de estas publicaciones estaban indexadas en Crossref, WoS y Scopus. También compararon el país y la editorial de cada revista.
Para el segundo objetivo, se seleccionaron al azar 300 artículos (100 de cada año entre 2017 y 2019) publicados en revistas científicas españolas de ciencias de la salud. Se consultaron las tres bases de datos (OpenAlex, WoS y Scopus) para verificar la presencia de estos artículos, el número de citas que habían recibido, y la completitud de los metadatos (autores, título, año, DOI, etc.). Para acceder a la información de Crossref y OpenAlex, se emplearon consultas mediante sus respectivas APIs.
1. Cobertura de revistas y editoriales
Crossref indexa un mayor número de títulos que WoS y Scopus. En concreto, supera en un 18 % a WoS y en un 14 % a Scopus.
La cobertura por países y editoriales también es más amplia en Crossref, que muestra una mayor representatividad de editoriales pequeñas o periféricas.
Mientras que WoS y Scopus tienden a concentrarse en publicaciones de grandes editoriales y países centrales (EE.UU., Reino Unido, Países Bajos), Crossref incluye una variedad más diversa.
2. Cobertura de artículos y citas en OpenAlex
De los 300 artículos muestreados, OpenAlex recuperó el 93 %, mientras que Scopus y WoS recuperaron el 88 % y 82 % respectivamente.
El cómputo de citas fue mayor en OpenAlex que en las otras dos bases. En promedio, OpenAlex ofrecía un 23 % más de citas que WoS y un 17 % más que Scopus.
En cuanto a la calidad de los metadatos, no hubo grandes diferencias. Las tres bases presentaban niveles similares de completitud, especialmente en campos como título, autores y año. OpenAlex destaca por su apertura y facilidad de acceso a los datos mediante API.
Los resultados confirman que Crossref y OpenAlex ofrecen una cobertura más amplia y representativa, lo que las convierte en herramientas útiles para investigaciones y procesos de evaluación más inclusivos. Su carácter abierto y gratuito constituye una ventaja clara frente a WoS y Scopus, que son plataformas comerciales con acceso limitado.
Sin embargo, los autores también advierten de ciertas limitaciones. Por ejemplo, aunque Crossref ofrece una amplia cobertura de revistas, no todas están actualizadas o bien mantenidas por sus editores. Por otro lado, OpenAlex, al ser un recurso relativamente reciente, aún está en desarrollo y puede presentar inconsistencias ocasionales.
Conclusiones
Crossref presenta una cobertura de revistas superior a WoS y Scopus, tanto en cantidad como en diversidad editorial y geográfica.
OpenAlex muestra mayor cobertura de artículos y citas, así como una calidad de metadatos comparable a la de las otras dos bases.
Ambas plataformas representan una alternativa viable y sólida para estudios bibliométricos, especialmente en un entorno que promueve la ciencia abierta.
Los resultados del estudio pueden servir de base para repensar los criterios de evaluación científica, diversificando las fuentes y apoyando modelos más equitativos y abiertos.
Las herramientas de inteligencia artificial (IA) están cambiando la investigación científica, con modelos como ChatGPT y DeepSeek facilitando tareas como la redacción y la resolución de problemas complejos. Llama es popular por su adaptabilidad en simulaciones científicas, mientras que Claude destaca en codificación. OLMo, por su parte, ofrece total transparencia en su funcionamiento.
Las herramientas de inteligencia artificial (IA) generativa están revolucionando el panorama de la investigación, ofreciendo una amplia variedad de modelos de lenguaje (LLM) para diferentes tareas. Desde la escritura de códigos hasta la generación de hipótesis o la edición de manuscritos, los investigadores ahora tienen acceso a más herramientas que nunca.
OpenAI y sus modelos de razonamiento OpenAI, con sede en San Francisco, lanzó su chatbot ChatGPT en 2022, y desde entonces ha desarrollado modelos avanzados como o1 y o3, diseñados para realizar razonamientos paso a paso. Estos modelos sobresalen en tareas como la resolución de problemas matemáticos y la depuración de código. Recientemente, OpenAI introdujo el o3-mini, una versión más rápida y accesible de su modelo de razonamiento, y ‘deep research’, una herramienta que permite generar informes sintéticos de información con citas de múltiples sitios web. Aunque potentes, estos modelos siguen siendo propensos a errores y no pueden reemplazar completamente a un investigador humano.
DeepSeek: el modelo versátil La empresa china DeepSeek lanzó su modelo DeepSeek-R1, que se destaca por su bajo costo y la capacidad de personalizarse para proyectos de investigación específicos. A diferencia de los modelos de OpenAI, DeepSeek-R1 es de «peso abierto», lo que permite a los investigadores adaptarlo a sus necesidades. Es especialmente útil para tareas como problemas matemáticos y generación de hipótesis. Sin embargo, presenta desventajas como un proceso de pensamiento lento y preocupaciones sobre la seguridad de los datos introducidos.
Llama: el caballo de batalla Llama, desarrollado por Meta AI, es otro modelo popular entre los investigadores, especialmente por su disponibilidad de código abierto, lo que permite a los usuarios adaptarlo para tareas específicas. Ha sido utilizado en simulaciones de computadoras cuánticas y para predecir estructuras cristalinas de materiales. A pesar de que requiere permisos para su uso, es ampliamente adoptado por la comunidad científica, que valora su accesibilidad y adaptabilidad.
Claude: el experto en codificación El modelo Claude 3.5 Sonnet de la firma Anthropic, basado en Silicon Valley, es altamente apreciado por su habilidad para escribir código y manejar información visual, como gráficos y tablas. Además, su capacidad para mantener el estilo técnico en la escritura lo hace útil para tareas como la redacción de propuestas de subvenciones y la anotación de códigos. Aunque su uso completo requiere acceso a una API de pago, se valora por su rendimiento en desafíos de codificación.
OLMo: la transparencia total OLMo 2 es un modelo de código abierto que ofrece una transparencia total, permitiendo a los investigadores examinar tanto los datos de entrenamiento como los algoritmos utilizados para desarrollar el modelo. Este nivel de transparencia es valioso para entender sesgos en los resultados y mejorar la eficiencia del modelo. Sin embargo, su uso requiere conocimientos técnicos, aunque los cursos gratuitos están reduciendo las barreras de entrada.
En general, la IA generativa está transformando la investigación científica, pero la elección del modelo adecuado depende de las necesidades del investigador y los recursos disponibles. Aunque estas herramientas prometen avances significativos, su implementación aún enfrenta desafíos como la supervisión humana y la protección de datos sensibles.