Endert, Julius. “Generative AI is the Ultimate Disinformation Amplifier.” DW Akademie, March 26, 2024. https://akademie.dw.com/en/generative-ai-is-the-ultimate-disinformation-amplifier/a-68593890
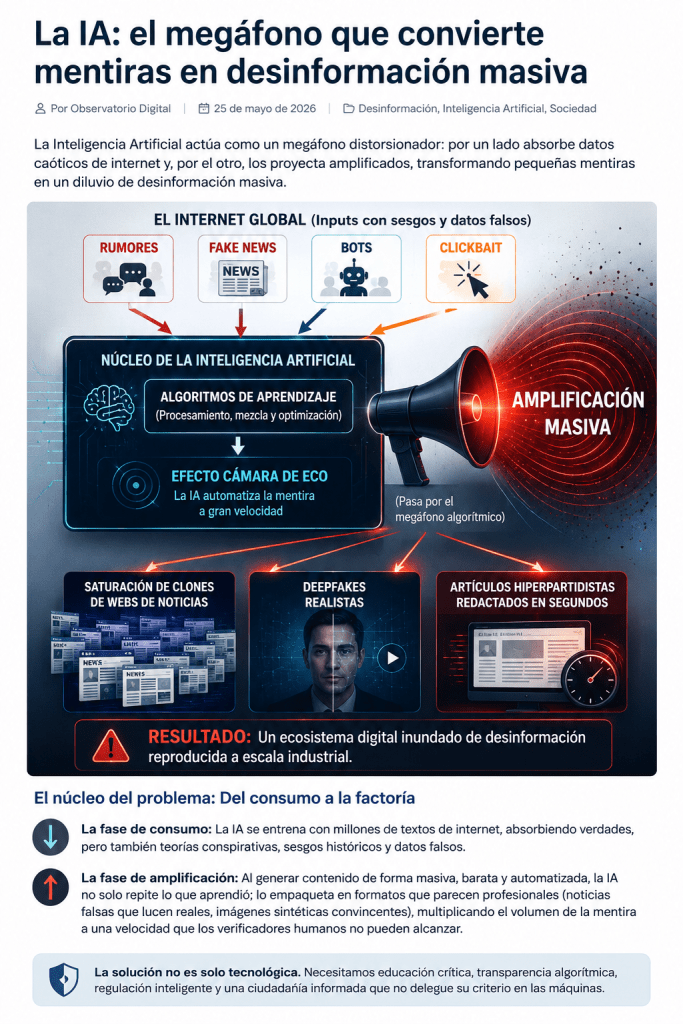
La Inteligencia Artificial actúa como un megáfono distorsionador: por un lado absorbe datos caóticos de internet y, por el otro, los proyecta amplificados, transformando pequeñas mentiras en un diluvio de desinformación masiva.
La inteligencia artificial está redefiniendo el ecosistema informativo global. Su capacidad para procesar enormes volúmenes de datos, sintetizar información y generar contenido coherente ha sido celebrada como una revolución tecnológica. Sin embargo, existe una dimensión menos visible y potencialmente más peligrosa: su papel como amplificador estructural de la desinformación.
El núcleo del problema: Del consumo a la factoría
- La fase de consumo: La IA se entrena con millones de textos de internet, absorbiendo verdades, pero también teorías conspirativas, sesgos históricos y datos falsos.
- La fase de amplificación: Al generar contenido de forma masiva, barata y automatizada, la IA no solo repite lo que aprendió; lo empaqueta en formatos que parecen profesionales (noticias falsas que lucen reales, imágenes sintéticas convincentes), multiplicando el volumen de la mentira a una velocidad que los verificadores humanos no pueden alcanzar.
En este sentido, la IA puede entenderse como un megáfono distorsionador. No necesariamente crea la mentira, pero sí la recoge del entorno digital, la reorganiza y la devuelve amplificada, dotada de mayor coherencia formal, más persuasiva y, en muchos casos, más difícil de detectar.
El ecosistema digital contemporáneo ya está profundamente contaminado por información de baja calidad. Rumores sin verificar, noticias falsas diseñadas estratégicamente, bots automatizados y contenidos clickbait optimizados para la viralidad forman parte de un flujo constante de información caótica. En condiciones tradicionales, este ruido informativo se filtra parcialmente a través de medios de comunicación, periodistas o verificadores de hechos. Sin embargo, en los sistemas de inteligencia artificial generativa, este filtro se vuelve más ambiguo y menos transparente.
La IA no distingue entre verdad y falsedad en términos humanos. Su funcionamiento se basa en el reconocimiento de patrones lingüísticos, probabilidades estadísticas y correlaciones entre datos. En otras palabras, no opera con un modelo de verdad, sino con un modelo de coherencia. Esto genera un problema estructural: aquello que es falso, pero aparece repetido con suficiente frecuencia en los datos, puede adquirir apariencia de verosimilitud dentro del sistema.
El núcleo del problema reside precisamente en esta ausencia de epistemología. Los algoritmos de aprendizaje automático procesan grandes volúmenes de información heterogénea, mezclan fuentes de distinta calidad y generan respuestas que priorizan la plausibilidad lingüística. El resultado es la posibilidad de que la coherencia sustituya a la veracidad como criterio dominante.
En este contexto, surge un efecto de cámara de eco automatizado. Una vez que los sistemas han sido entrenados con datos contaminados, pueden reproducir narrativas sesgadas, interpretaciones incompletas o errores que aparecen reformulados como si fueran hechos. Sin embargo, el aspecto más preocupante no es la simple repetición, sino la capacidad de reformulación constante.
La inteligencia artificial no copia la desinformación de forma literal, sino que la reescribe. En ese proceso, le otorga apariencia de novedad, adopta estilos comunicativos profesionales y elimina rastros evidentes de su origen dudoso. Esto contribuye a que la mentira se vuelva más sofisticada, más creíble y mucho más difícil de rastrear.
Cuando este contenido generado se traslada al espacio público, entra en una fase de amplificación masiva. La IA funciona entonces como un megáfono digital capaz de producir múltiples versiones de un mismo mensaje, adaptarlo a diferentes audiencias, generar textos, imágenes o vídeos hiperrealistas y simular voces o estilos periodísticos. El resultado es una auténtica industrialización de la desinformación, donde ya no existen falsedades aisladas, sino ecosistemas completos de réplicas coordinadas.
En este nuevo entorno emergen formas específicas de desinformación automatizada. Por un lado, la saturación de medios clonados, es decir, sitios web que imitan portales informativos legítimos y que se generan automáticamente para reforzar determinadas narrativas. Por otro, los deepfakes hiperrealistas, capaces de recrear con gran precisión eventos que nunca ocurrieron. Finalmente, los artículos hiperpartidistas automatizados, textos generados en segundos que imitan el estilo periodístico pero están diseñados para polarizar y manipular la opinión pública.
Este proceso implica un cambio estructural profundo: la transición de la IA de consumidora de información a productora masiva de narrativas. Durante su fase de consumo, los sistemas se entrenan con un entorno digital donde conviven textos fiables, teorías conspirativas, sesgos históricos y errores acumulados. El problema no es la diversidad de datos, sino la ausencia de jerarquía epistemológica que permita distinguir su valor.
En la fase de amplificación, la IA reconfigura ese material sin mecanismos robustos de verificación de verdad. Reempaqueta la información en formatos persuasivos y acelera su difusión a una escala sin precedentes. De este modo, el sistema deja de ser únicamente un repositorio de conocimiento para convertirse en una factoría de narrativas.
El resultado es un ecosistema de realidad cada vez más inestable. La saturación informativa se vuelve constante, las fronteras entre lo real y lo simulado se difuminan, la confianza en las fuentes tradicionales disminuye y la verificación de hechos se vuelve progresivamente más compleja. En este contexto, la desinformación deja de ser una anomalía puntual y pasa a integrarse como un subproducto estructural del sistema informativo automatizado.
Por ello, la inteligencia artificial no puede entenderse únicamente como una herramienta neutral. Su funcionamiento actual la sitúa como un sistema de transformación masiva de información que puede tanto ampliar el acceso al conocimiento como intensificar sus distorsiones. El problema no es solo tecnológico, sino profundamente epistemológico: cómo distinguir la verdad cuando la falsedad puede ser generada, replicada y estilizada con la misma eficacia formal.
La respuesta no puede ser exclusivamente técnica. Requiere educación crítica, alfabetización mediática y nuevos marcos de gobernanza digital. En un entorno donde la inteligencia artificial amplifica todo, la cuestión central ya no es únicamente qué es información, sino qué significa todavía hablar de verdad.