
TEXT MINING 101
WRITTEN BY OPENMINTED COMMUNICATIONS ON FEBRUARY 21, 2018
Original
Este artículo le ayudará a entender lo básico en sólo unos minutos.
¿QUÉ ES LA MINERÍA DE TEXTOS?
La minería de textos busca extraer información útil e importante de formatos de documentos heterogéneos, tales como páginas web, correos electrónicos, medios sociales, artículos de revistas, etc. Esto se hace mediante la identificación de patrones dentro de los textos, tales como tendencias en el uso de palabras, estructura sintáctica, etc.
La gente a menudo habla de «minería de texto y datos (TDM)» al mismo tiempo, pero estrictamente hablando la minería de texto es una forma específica de minería de datos que se relaciona con el texto.
¿POR QUÉ LO NECESITAMOS?
La minería de textos tiene muchas aplicaciones. Por ejemplo, la minería de textos puede ayudar a encontrar tecnologías nuevas e innovadoras dentro de ciertos dominios. Es un método muy eficiente para generar nueva información y conocimiento. Esta práctica permite a las empresas reducir el tiempo dedicado a la lectura de textos extensos y extractos literarios. Esto significa que los recursos clave se pueden encontrar con mayor rapidez y eficacia. También permite a los usuarios obtener nueva información que de otro modo sería difícil de encontrar.
¿QUÉ CLASE DE GENTE HACE MINERÍA DE TEXTOS?
La tecnología de la minería de textos es actualmente ampliamente aplicada por una extensa variedad de usuarios, desde organizaciones gubernamentales, instituciones de investigación y empresas para sus necesidades diarias. Estos son algunos ejemplos de uso en diferentes campos:
Investigación: por ejemplo, el descubrimiento de conocimientos, la atención médica y sanitaria: en el pasado, a un investigador humano le lleva mucho tiempo analizar y obtener información relevante. En algunos casos, esta información ni siquiera era accesible. La minería de textos permite a los investigadores encontrar más información y de forma más rápida y eficiente.
Negocios: por ejemplo, las grandes empresas utilizan la minería de textos para ayudar en la toma de decisiones y responder rápidamente a las consultas de los clientes en procesos tales como la gestión de riesgos o el filtrado de currículos
Seguridad: En anti-terrorismo, el análisis de los blogs y otras fuentes de texto en línea se utiliza para prevenir delitos en Internet y luchar contra el fraude.
Diariamente, La minería de texto es usada por los sitios web de correo electrónico para crear métodos de filtrado más confiables y efectivos, para el filtrado de spam, análisis de datos de medios sociales, etc. También para identificar las relaciones entre los usuarios y ciertos productos o para determinar las opiniones de los usuarios sobre temas particulares
¿ES ÚTIL LA MINERÍA DE TEXTOS PARA LA CIENCIA?
Los usos de la minería de textos son virtualmente interminables, pero vamos a centrarnos más en que manera es útil para la ciencia y la investigación. Los científicos se comunican a través de publicaciones científicas y se estima que existen más de 50 millones de revistas (JINHA, A. E. (2010), po lo cual cada vez es más difícil para los investigadores hacer un seguimiento de lo que se publica en su propio campo. Además, hay una enorme afluencia de otros tipos de datos en todas las ciencias, como páginas web, informes de organizaciones públicas (por ejemplo, transcripciones judiciales, actas de reuniones), libros, etc. La minería de textos puede ayudar a resolver este problema y a encontrar nueva información.
ESPERA UN MINUTO, ¿ASÍ ES COMO OBTENGO ESOS ANUNCIOS PERSONALIZADOS?
Como se ha dicho antes, las tecnologías de minería de texto tienen muchas aplicaciones. Entre ellas, se puede utilizar para establecer vínculos entre clientes potenciales y productos con fines de marketing o de otro tipo.
¿CUÁL ES LA DIFERENCIA ENTRE MINERÍA DE TEXTO Y GOOGLE?
Los motores de búsqueda como Google, recuperan todos los documentos que contienen las palabras clave que has especificado. No hay valor añadido a los datos. La minería de textos lleva las cosas un paso más allá al extraer información precisa basada en mucho más que palabras clave. En su lugar, busca entidades o conceptos, relaciones, frases y/o oraciones. Intenta determinar el significado real basado en algoritmos de Procesamiento del Lenguaje Natural (NLP), que le permiten reconocer conceptos similares. Una búsqueda utilizando la minería de texto puede identificar hechos, relaciones e inferencias que no son del todo obvios.
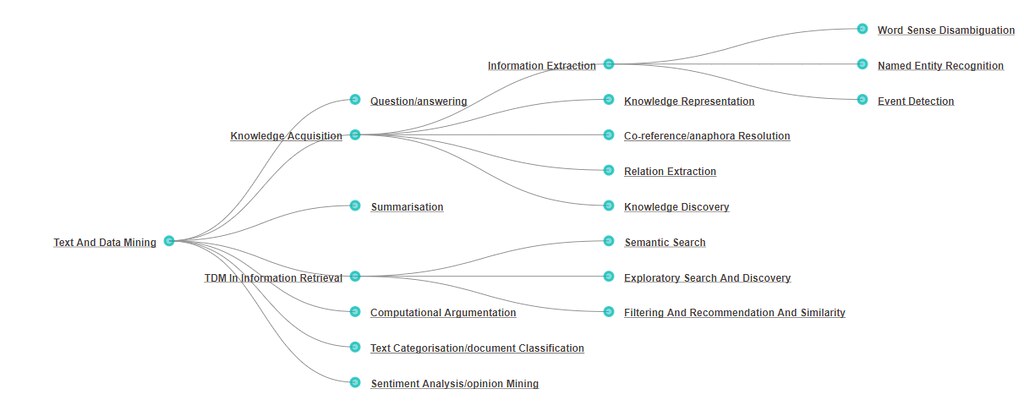
¿CÓMO FUNCIONA, ESTA MINERÍA DE TEXTO Y DATOS?
La extracción de textos puede dividirse en cinco pasos:

1. Recolección: Recopilación de datos de diferentes recursos, tales como sitio web, correos electrónicos, comentarios de clientes, archivo de documentos. Dependiendo de la aplicación, este proceso puede ser completamente automatizado o guiado por una persona encargada de realizar este proceso.
2. Preprocesamiento: La identificación del contenido y la extracción de características representativas
3. Limpieza de textos: eliminación de cualquier información innecesaria o no deseada, como los anuncios de las páginas.
4. Tokenización: un ordenador sólo «ve» una cadena de caracteres, sin poder identificar, por ejemplo, párrafos, frases o palabras. La Tokenización divide el texto en entidades significativas (palabras, oraciones, etc.) dados los espacios en blanco presentes y las puntuaciones.
5. Extracción de características (también llamada selección de atributos): es el proceso de caracterización.
Un ejemplo puede ilustrar estos cinco pasos:
Imagina que estás vendiendo calendarios de animales. Si deseas saber si es una buena inversión para que se anuncie en los sitios web de blogs, y por lo tanto, te gustaría conocerqué porcentaje de las entradas en el blog están hablando de los animales.
En primer lugar, es necesario reunir todos los textos de todas las entradas de blog que puedas encontrar. Dado que puede haber cientos de miles de estos textos en Internet, probablemente no quieras descargarlos manualmente, uno por uno. Así que necesitas software para rastrear la web, descargar los artículos que encuentre y organizarlos en una base de datos apropiada.
En segundo lugar, querrás preprocesar el material recolectado para que las siguientes herramientas (discutidas en los pasos 3 a 5) puedan trabajar más eficientemente. Por ejemplo, querrás eliminar anuncios, menús de páginas web, código fuente de las páginas web HTML, etc. A continuación, es posible que desees calcular algunas características (extracción de características) para tu colección de textos. Por ejemplo, es posible que desees conocer el número de palabras de cada mensaje, de modo que pueda rechazar las que son demasiado pequeñas (por ejemplo, 10 palabras) o demasiado grandes (por ejemplo, 10 000 palabras). Tales entradas en su base de datos probablemente no son representativas y pueden ser errores generados por su software utilizado en el primer paso. Para obtener estos recuentos de palabras, primero tendrás que dividir los textos (serie de caracteres) en palabras (tokenización).
En el tercer paso, es posible que desees crear índices. Por ejemplo, para enumerar qué palabras se han encontrado en qué textos. Puedes pensar en esto como el índice de un libro. Sin un índice, es muy difícil localizar la información sobre un tema específico. Pero con un índice, es mucho más fácil y rápido encontrar lo que está buscando. Esto también es cierto para el software que busca palabras en su enorme base de datos blog.
Luego, en el cuarto paso, querrás extraer los textos para extraer alguna información que le ayudará a contestar sus preguntas. En este caso, querrás identificar palabras que se refieran a animales. Un nombre de entidad reconocedora de animales tratará de reconocer cada palabra que se refiera a un animal, como perro, gato, gatito, felino, mamífero, petirrojo americano, Turdus migratorius, etc. También es posible que desees ejecutar lo que se conoce como’ algoritmos sintácticos‘ para identificar qué palabras son sustantivos y cuáles verbos. Se necesitan muchos algoritmos para distinguir, por ejemplo, el uso de cat en «Tengo un gato hermoso» y que «ejecute cat file. txt en su línea de comandos para mostrar el texto.o rechazar «Se movió como una araña» Evidentemente, se necesita mucha inteligencia para llevar a cabo esta tarea con precisión.
A continuación, en el quinto paso, se desea realizar análisis y trazar gráficos. Por ejemplo, puedes requerir una gráfica de barra que muestre el porcentaje de artículos del blog que hablan sobre los animales para cada uno de los diez sitios web de alojamiento de blog más importantes. Con esta información, por ejemplo, puedes convencer a tus colaboradores de que es una buena idea invertir dinero en publicidad para calendarios de animales en whatablog. com.
Este artículo fue escrito como parte del proyecto OpenMinTeD por: Jiakang Chang (EMBL-EBI), Christian O’ Reilly (EPFL), Nancy Pontika (Open University) Gareth Owen (EMBL-EBI), Kenneth Haug (EMBL-EBI), Martine Oudenhoven (LIBER)









