Regulation laying down harmonised rules on artificial intelligence (artificial intelligence act), 21 May 2024 European Union, may 2024
Ver la ley
Hoy, el Consejo aprobó una ley pionera que busca armonizar las normas sobre inteligencia artificial (IA), conocida como la Ley de Inteligencia Artificial. Esta legislación emblemática sigue un enfoque «basado en el riesgo», lo que significa que cuanto mayor sea el riesgo de causar daño a la sociedad, más estrictas serán las reglas. Es la primera de su tipo en el mundo y puede establecer un estándar global para la regulación de la IA.
La nueva ley tiene como objetivo fomentar el desarrollo y la adopción de sistemas de IA seguros y confiables en el mercado único de la UE, tanto por actores privados como públicos. Al mismo tiempo, busca garantizar el respeto de los derechos fundamentales de los ciudadanos de la UE y estimular la inversión y la innovación en inteligencia artificial en Europa. La Ley de IA se aplica solo a áreas dentro del derecho de la UE y prevé exenciones para sistemas utilizados exclusivamente con fines militares y de defensa, así como para fines de investigación.
La adopción de la Ley de IA es un hito significativo para la Unión Europea. Esta ley histórica, la primera de su tipo en el mundo, aborda un desafío tecnológico global que también crea oportunidades para nuestras sociedades y economías. Con la Ley de IA, Europa enfatiza la importancia de la confianza, la transparencia y la responsabilidad al tratar con nuevas tecnologías, al tiempo que asegura que esta tecnología en rápida evolución pueda florecer y estimular la innovación europea.
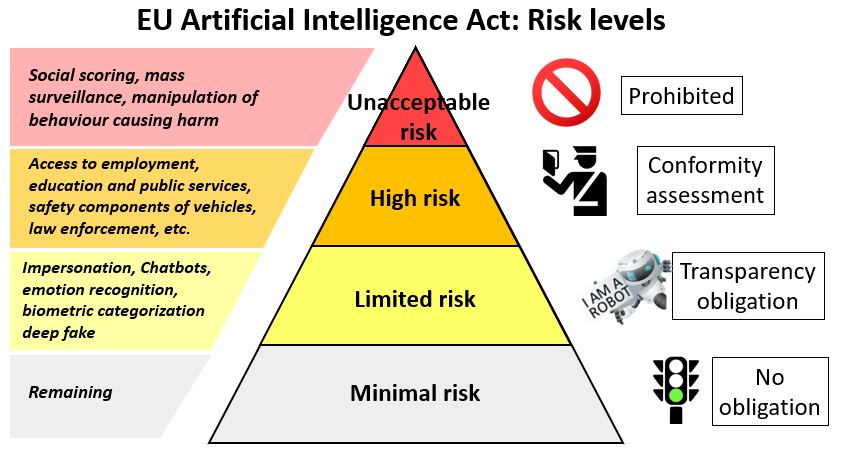
Clasificación de sistemas de IA como de alto riesgo y prácticas prohibidas de IA
La nueva ley clasifica diferentes tipos de inteligencia artificial según su riesgo. Los sistemas de IA que presenten un riesgo limitado estarán sujetos a obligaciones de transparencia muy ligeras, mientras que los sistemas de IA de alto riesgo serán autorizados, pero sujetos a una serie de requisitos y obligaciones para acceder al mercado de la UE. Los sistemas de IA como la manipulación cognitivo-conductual y la puntuación social serán prohibidos en la UE debido a que su riesgo se considera inaceptable. La ley también prohíbe el uso de IA para la vigilancia predictiva basada en perfiles y sistemas que utilizan datos biométricos para categorizar a las personas según categorías específicas como raza, religión u orientación sexual.
Modelos de IA de propósito general
La Ley de IA también aborda el uso de modelos de IA de propósito general (GPAI). Los modelos GPAI que no presenten riesgos sistémicos estarán sujetos a algunos requisitos limitados, por ejemplo, en cuanto a la transparencia, pero aquellos con riesgos sistémicos deberán cumplir con reglas más estrictas.
Nueva arquitectura de gobernanza
Para asegurar una adecuada aplicación, se establecen varios órganos de gobierno:
- Una Oficina de IA dentro de la Comisión para hacer cumplir las reglas comunes en toda la UE.
- Un panel científico de expertos independientes para apoyar las actividades de aplicación.
- Un Consejo de IA con representantes de los estados miembros para asesorar y ayudar a la Comisión y a los estados miembros en la aplicación coherente y efectiva de la Ley de IA.
- Un foro consultivo para las partes interesadas que proporcione experiencia técnica al Consejo de IA y a la Comisión.
Sanciones
Las multas por infracciones a la Ley de IA se establecen como un porcentaje del volumen de negocios anual global de la empresa infractora en el ejercicio financiero anterior o una cantidad predeterminada, lo que sea mayor. Las PYMEs y las start-ups estarán sujetas a multas administrativas proporcionales.
Transparencia y protección de los derechos fundamentales
Antes de que un sistema de IA de alto riesgo sea desplegado por algunas entidades que brindan servicios públicos, se deberá evaluar el impacto en los derechos fundamentales. La regulación también prevé una mayor transparencia respecto al desarrollo y uso de sistemas de IA de alto riesgo. Los sistemas de IA de alto riesgo, así como ciertos usuarios de un sistema de IA de alto riesgo que sean entidades públicas, deberán registrarse en la base de datos de la UE para sistemas de IA de alto riesgo, y los usuarios de un sistema de reconocimiento de emociones deberán informar a las personas naturales cuando estén siendo expuestas a dicho sistema.
Medidas en apoyo de la innovación
La Ley de IA prevé un marco legal favorable a la innovación y tiene como objetivo promover el aprendizaje regulatorio basado en evidencias. La nueva ley contempla que los entornos regulatorios de prueba para la IA, que permiten un entorno controlado para el desarrollo, prueba y validación de sistemas de IA innovadores, también permitan la prueba de sistemas de IA innovadores en condiciones del mundo real.
Próximos pasos
Después de ser firmada por los presidentes del Parlamento Europeo y del Consejo, la ley se publicará en el Diario Oficial de la UE en los próximos días y entrará en vigor veinte días después de esta publicación. La nueva regulación se aplicará dos años después de su entrada en vigor, con algunas excepciones para disposiciones específicas.
Antecedentes
La Ley de IA es un elemento clave de la política de la UE para fomentar el desarrollo y la adopción de IA segura y legal que respete los derechos fundamentales en todo el mercado único. La Comisión (Thierry Breton, comisario de mercado interior) presentó la propuesta de la Ley de IA en abril de 2021. Brando Benifei (S&D / IT) y Dragoş Tudorache (Renew Europe / RO) fueron los ponentes del Parlamento Europeo en este expediente y se alcanzó un acuerdo provisional entre los colegisladores el 8 de diciembre de 2023.