Tay, Aaron. The Blank Box Problem: Why It’s Harder Than Ever to Know What to Type Into an AI Search Bar. Publicado el 10 de enero de 2026 en Aaron Tay’s Musings about Librarianship (Substack). https://aarontay.substack.com/p/the-blank-box-problem-why-its-harder
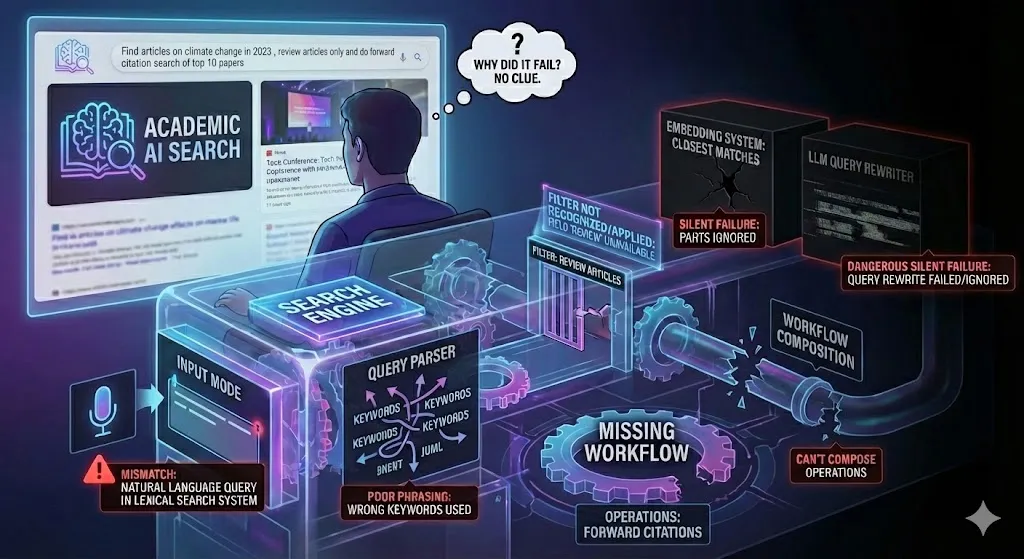
Se aborda un fenómeno importante y creciente en la forma en que interactuamos con las tecnologías de búsqueda potenciada por inteligencia artificial. Aaron Tay describe el llamado “problema de la caja vacía”, que se refiere a la interfaz minimalista y aparentemente sencilla que caracteriza a las nuevas herramientas de búsqueda con IA: una simple barra de texto en blanco donde el usuario debe escribir su consulta sin ninguna guía explícita. Aunque esta simplicidad visual puede parecer atractiva, Tay argumenta que en realidad introduce una complejidad mucho mayor para el usuario, quien ahora enfrenta un desafío mucho más grande para formular preguntas efectivas. La ausencia de señales visuales, filtros o estructuras de consulta claras que existían en los motores de búsqueda tradicionales provoca que el usuario quede desorientado y no sepa qué tipo de entrada es la más adecuada para obtener resultados precisos o útiles.
En la era previa a la inteligencia artificial, muchas plataformas de búsqueda ofrecían herramientas como operadores booleanos, menús desplegables y categorías que ayudaban a los usuarios a acotar y precisar sus consultas. Estas herramientas, aunque a veces complejas, proporcionaban un marco de referencia sobre cómo interactuar con la base de datos o motor de búsqueda. Sin embargo, las interfaces modernas con IA, como los chatbots y asistentes inteligentes, presentan una única caja de texto sin indicaciones claras sobre qué esperar. Esto crea dos niveles de ambigüedad para el usuario: por un lado, no está seguro de cómo debe redactar su consulta —si debe usar términos técnicos, lenguaje natural, frases completas, comandos específicos o prompts diseñados para la IA—, y por otro lado, desconoce qué tipo de capacidades tiene el sistema, qué preguntas puede responder con precisión y cuáles no. Esta doble incertidumbre dificulta la confianza en el sistema y genera una sensación de trial and error constante, en la que los usuarios prueban diferentes formas de preguntar sin saber cuál será la mejor.
Además, Aaron Tay compara esta situación actual con la experiencia de años anteriores en entornos académicos y profesionales, donde las bases de datos especializadas exigían un aprendizaje de formatos y comandos específicos para ser usadas eficazmente. A pesar de ser más técnicas, esas plataformas ofrecían a los usuarios un marco claro y reglas definidas para construir consultas. En contraste, la actual “caja vacía” no ofrece ningún tipo de feedback inmediato ni estructura clara, por lo que los usuarios desarrollan sus propias “teorías populares” o intuiciones sobre cómo deben preguntar, a menudo basadas en ensayo y error o en compartir trucos entre comunidades en línea. Este fenómeno evidencia la falta de transparencia en cómo los modelos de IA interpretan el lenguaje y procesan las solicitudes, dejando a los usuarios sin un entendimiento real sobre la arquitectura interna que guía la generación de respuestas.
Finalmente, el artículo enfatiza que esta simplicidad superficial puede resultar contraproducente, ya que la interfaz minimalista esconde un funcionamiento interno complejo que no se comunica al usuario. Esto crea una brecha entre la experiencia del usuario y la tecnología, dificultando no solo la eficacia en la búsqueda, sino también la confianza y la adopción plena de estas nuevas herramientas. Aaron Tay sugiere que para superar este desafío, es necesario repensar el diseño de las interfaces de búsqueda con IA, de modo que se mantenga la accesibilidad y simplicidad, pero se agreguen señales claras y transparencia sobre las capacidades reales del sistema. Solo así se podrá equilibrar la promesa de la inteligencia artificial con la necesidad humana de entender y controlar las herramientas que utilizamos diariamente.









