Johnson, L.R., et al. (2018). How Important Are Data Curation Activities to Researchers? Gaps and Opportunities for Academic Libraries. Journal of Librarianship and Scholarly Communication, 6(General Issue), eP2198. https://doi.org/10.7710/2162-3309.2198
Curaduría de datos, según la definición de la Escuela de Posgrado en Biblioteconomía y Ciencias de la Información de la Universidad de Illinois: «es la gestión activa y continua de los datos a lo largo de su ciclo de vida de vida y utilidad.»
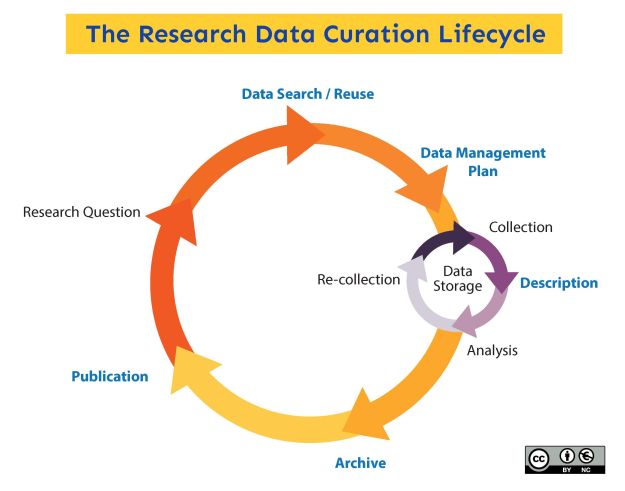
Por su parte, Sayeed Choudhury, Decano Asociado de Gestión de Datos de Investigación de la Universidad Johns Hopkins (JHU, por sus siglas en inglés) y líder de Data Conservancy, detalla las actividades iterativas de Data Curation:
- Conservar: Recolección y cuidado de los datos de la investigación.
- Compartir: Revelar el potencial de los datos en todos los dominios
- Descubrir: Promover la reutilización y las nuevas combinaciones de datos
Según Alation: «En la práctica, la curación de datos se ocupa más del mantenimiento y la gestión de los metadatos que de la propia base de datos y, con ese fin, gran parte del proceso de curación de datos gira en torno a la gestión de metadatos como el esquema, la estructura de tablas y columnas, el uso.. Los curadores de datos no sólo crean, administran y mantienen los datos, sino que también pueden participar en la determinación de las mejores prácticas para trabajar con esos datos. Los curadores de datos a menudo presentan los datos en un formato visual como un gráfico, un tablero o un informe».
Para techrepublic, Los procesos de recolección de datos de diversas fuentes y su integración en repositorios proporcionan un valor añadido mucho más valioso que estando en bases de datos independientes, ya que de esta manera pueden ser remezclados y rehutilizados con diferentes propósitos. Ya que la curaduría digital implica mantener, preservar y agregar valor a los datos de la investigación digital a lo largo de su ciclo de vida, incluyendo la organización, descripción, limpieza, mejora y conservación de los datos para uso público.
El proceso conlleva:
- Detección y recuperación de datos.
- Mantener la calidad de datos.
- Agregar valor.
- Proporcionar la reutilización de los datos a lo largo del tiempo.
- Maximizare el acceso.
Por lo tanto, ¿Qué importancia tienen las actividades de curación de datos para los investigadores? Brechas y oportunidades para las bibliotecas académicas.
La curación de datos promete ser un servicio emergente para las bibliotecas universitarias, pero los investigadores activamente «curan» sus datos de varias maneras, incluso si la terminología no siempre se adecua a la situación. Sobre la base de las evaluaciones de necesidades de usuario realizadas en el pasado a través de encuestas y grupos focales, los autores buscaron la opinión directa de los investigadores sobre la importancia y la utilización de actividades específicas de curación de datos.
De este modo entre el el 21 de octubre de 2016 y el 18 de noviembre de 2016, el equipo de estudio realizó grupos focales con 91 participantes en seis instituciones académicas diferentes para determinar qué actividades de curación de datos eran más importantes para los investigadores, qué actividades estaban actualmente en curso y qué nivel de satisfacción tenían con los resultados.
Los resultados muestran que los investigadores participan activamente en una variedad de actividades de curación de datos, y si bien consideraron que la mayoría de las actividades de curación de datos son muy importantes, la mayoría de la muestra manifestó su insatisfacción con el estado actual de curación de datos en su institución. Estos hallazgos demuestran brechas y oportunidades específicas para que las bibliotecas universitarias enfoquen sus servicios de curación de datos para satisfacer de manera más efectiva las necesidades de los investigadores. Para de este modo, las bibliotecas de investigación participen en estos servicios más activamente invirtiendo y promoviendo servicios altamente valorados que actualmente muchos investigadores no pueden utilizar.








