
Miller, Claire Cain. «A.I. Is Getting More Powerful, but Its Hallucinations.» The New York Times, May 5, 2025. https://www.nytimes.com/2025/05/05/technology/ai-hallucinations-chatgpt-google.html
Una nueva oleada de sistemas de «razonamiento» de empresas como OpenAI está produciendo información incorrecta con mayor frecuencia. Ni siquiera las empresas saben por qué.
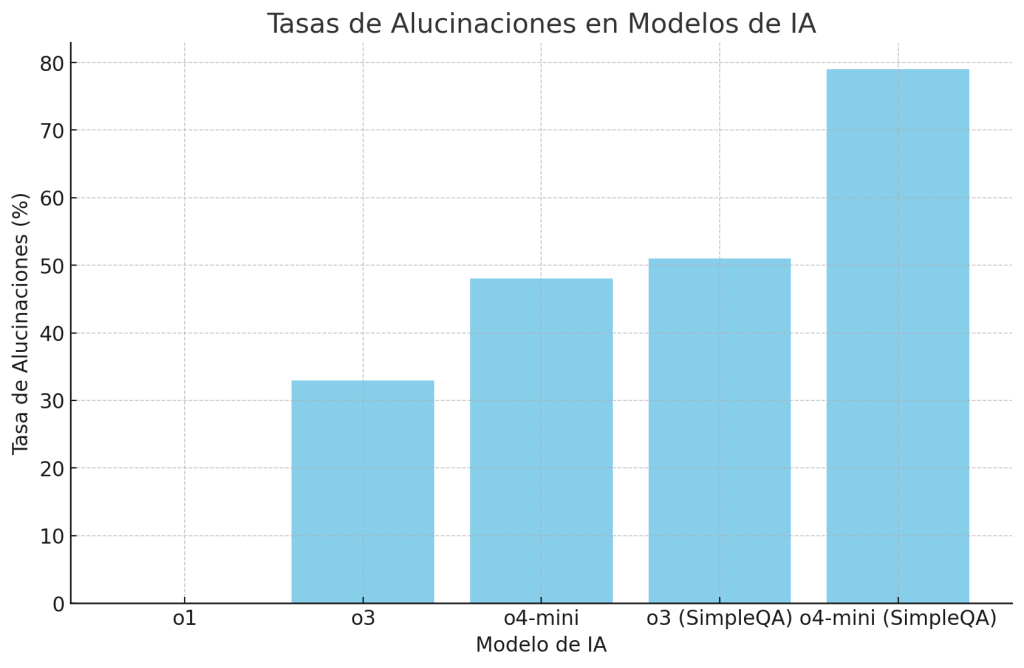
Se aborda el fenómeno de las «alucinaciones» en la inteligencia artificial, un problema crítico que afecta a modelos de lenguaje como ChatGPT y Bard de Google. Estas alucinaciones se refieren a respuestas generadas por IA que, aunque suenan plausibles, son incorrectas o completamente inventadas. Por ejemplo, en una prueba llamada PersonQA, el sistema más potente de OpenAI, denominado o3, presentó una tasa de alucinaciones del 33%, más del doble que su predecesor o1. El modelo o4-mini mostró una tasa aún mayor, alcanzando el 48%. En otra prueba, SimpleQA, las tasas de alucinaciones fueron del 51% para o3 y del 79% para o4-mini
Las alucinaciones son una consecuencia inherente a la manera en que los modelos de lenguaje están diseñados. Estos sistemas funcionan mediante el análisis de grandes volúmenes de datos y el aprendizaje de patrones estadísticos en el lenguaje. Para generar respuestas, no realizan una búsqueda de información en tiempo real ni verifican la precisión de los datos con fuentes externas, sino que se basan en los datos con los que fueron entrenados. Esta falta de verificación en tiempo real, unida a la complejidad de los procesos de generación de texto, puede llevar a que el modelo produzca información que, aunque coherente en su estructura, sea incorrecta o completamente ficticia.
Además, los modelos de lenguaje son inherentemente probabilísticos, lo que significa que seleccionan la «respuesta más probable» en función del contexto, pero no siempre tienen en cuenta si esa respuesta es veraz. En este sentido, las alucinaciones ocurren cuando el modelo «adivina» una respuesta que, aunque sea lingüísticamente plausible, carece de sustancia factual. Por ejemplo, en lugar de verificar hechos o proporcionar citas precisas, el modelo puede generar información coherente pero errónea debido a que los patrones previos en los datos entrenados sugieren que esa información tiene sentido dentro del contexto dado.
El fenómeno de las alucinaciones plantea una amenaza directa a la confiabilidad y utilidad de los sistemas de IA. A medida que estas tecnologías se adoptan en una variedad de sectores, desde el sector educativo hasta la atención médica y el asesoramiento empresarial, los usuarios se encuentran cada vez más en una posición vulnerable al confiar en respuestas generadas por máquinas que podrían ser incorrectas. En contextos como la medicina o el derecho, donde la precisión es crucial, las alucinaciones pueden tener consecuencias graves, desde diagnósticos incorrectos hasta consejos legales erróneos.
La preocupación por este problema es tal que algunos expertos temen que la confianza pública en las IA podría disminuir si las alucinaciones continúan sin control. La percepción de que los sistemas de IA no son completamente fiables podría desalentar a los usuarios de adoptar estas herramientas en áreas críticas. A su vez, esto podría ralentizar el progreso hacia la integración de la IA en sectores importantes de la sociedad, afectando su potencial para revolucionar industrias enteras.
Empresas como OpenAI y Google son conscientes de las limitaciones de sus modelos y están tomando medidas activas para mitigar el problema de las alucinaciones. Una de las estrategias es mejorar los algoritmos de verificación de hechos. Estos algoritmos buscan integrar fuentes de información más confiables y permitir que los modelos contrasten las respuestas generadas con bases de datos verificadas antes de ofrecer una respuesta final. Sin embargo, este proceso presenta desafíos técnicos significativos, ya que requiere una infraestructura adicional que permita a la IA verificar en tiempo real la información antes de presentarla al usuario.
Otra estrategia que se está explorando es la integración de sistemas de retroalimentación más robustos, donde los usuarios pueden señalar respuestas incorrectas y corregir la información. De esta manera, los modelos de IA no solo aprenden de los datos iniciales con los que fueron entrenados, sino también de las interacciones en el mundo real, lo que podría ayudar a disminuir la frecuencia de las alucinaciones con el tiempo. Aunque estas iniciativas son prometedoras, erradicar completamente las alucinaciones sigue siendo un desafío técnico y ético considerable.
A medida que la IA se utiliza en más ámbitos, se hace cada vez más evidente la necesidad de un enfoque más riguroso y transparente en su desarrollo. Es fundamental que los usuarios comprendan las limitaciones actuales de estas tecnologías y reconozcan que las respuestas generadas por IA no siempre son correctas. Esto implica educar al público sobre cómo funcionan estos modelos y la importancia de verificaciones adicionales por parte de los usuarios.
Además, las empresas deben adoptar una postura más abierta en cuanto a la metodología de entrenamiento de sus sistemas y las limitaciones inherentes a estos modelos. La transparencia en cómo se entrenan y actualizan los modelos, y el acceso a las fuentes utilizadas en su entrenamiento, puede ayudar a construir una relación de confianza con los usuarios y disminuir las preocupaciones sobre la exactitud de la información.
En resumen, las alucinaciones en la inteligencia artificial siguen siendo un obstáculo importante para su adopción generalizada y confianza pública. Aunque las empresas tecnológicas están haciendo esfuerzos significativos para mitigar este problema, es evidente que se requiere un enfoque multidisciplinario y más transparencia para abordar de manera efectiva este desafío. A medida que los modelos de IA continúan evolucionando, se espera que las soluciones a las alucinaciones también progresen, lo que permitirá un uso más confiable y preciso de estas tecnologías en una variedad de sectores.










