A researcher interacts with holographic neural network data in a high-tech lab
Pearl, Mike. “Chat Is Dead: OpenAI Reportedly Planning Radical Changes to ChatGPT”. Gizmodo, 7 de junio de 2026. Basado en información publicada originalmente por el Financial Times.
El artículo analiza una de las transformaciones más ambiciosas que estaría preparando OpenAI para ChatGPT. Según información obtenida por el Financial Times a partir de entrevistas con empleados y ex empleados de la compañía, OpenAI ya no vería el futuro de la inteligencia artificial centrado en simples conversaciones con un chatbot. En palabras atribuidas a un alto responsable de la empresa, “Chat is dead” (“el chat ha muerto”), una frase que resume el cambio estratégico que estaría impulsando la organización.
La idea fundamental consiste en convertir ChatGPT en una especie de “superaplicación” o superapp, mucho más parecida a un asistente digital integral que a una interfaz de preguntas y respuestas. OpenAI considera que el verdadero potencial económico y tecnológico de la IA no reside únicamente en responder consultas, sino en ejecutar tareas completas en nombre de los usuarios. Esto incluiría organizar agendas, reservar viajes, gestionar información personal, coordinar flujos de trabajo e incluso desarrollar software de manera autónoma.
El informe señala que uno de los grandes protagonistas de esta transformación será Codex, la plataforma de programación de OpenAI. La compañía pretende otorgarle una posición mucho más visible dentro de ChatGPT, impulsando el uso de herramientas capaces de escribir código, crear aplicaciones y automatizar procesos complejos. Este movimiento responde tanto a las oportunidades de negocio que ofrece el mercado empresarial como a la creciente competencia con otras empresas especializadas en IA, especialmente Anthropic y su asistente Claude.
Otro aspecto destacado es el rediseño de la propia interfaz de ChatGPT. OpenAI estaría trabajando para que los usuarios sean dirigidos de forma más natural hacia funciones avanzadas, como la generación de imágenes, la programación o las aplicaciones desarrolladas por socios externos. En lugar de limitarse a escribir preguntas en una ventana de chat, los usuarios encontrarían un entorno orientado a la realización de tareas y proyectos completos.
La visión a largo plazo va incluso más lejos. Según las fuentes citadas, OpenAI aspira a que sus modelos comprendan automáticamente las intenciones de los usuarios sin necesidad de depender de instrucciones detalladas o de conversaciones estructuradas. El objetivo sería disponer de un agente personal inteligente capaz de acompañar al usuario en distintos dispositivos —ordenador, móvil o incluso sistemas integrados en vehículos— y actuar como intermediario entre la persona y los servicios digitales que utiliza diariamente.
El contexto económico también resulta importante para entender esta estrategia. OpenAI afronta una creciente presión para aumentar ingresos y demostrar una senda clara hacia la rentabilidad mientras se prepara para una posible salida a bolsa. Actualmente, una parte muy significativa de sus ingresos procede de clientes empresariales, y la compañía espera incrementar todavía más ese porcentaje. Por ello, las herramientas profesionales, los agentes autónomos y los sistemas de automatización aparecen como áreas con mayor potencial económico que el uso tradicional del chatbot gratuito.
Más allá de los aspectos financieros, esta evolución refleja un cambio profundo en la concepción de la inteligencia artificial. Si durante los últimos años el paradigma dominante ha sido el del chatbot conversacional, OpenAI parece apostar ahora por sistemas capaces de actuar, decidir y ejecutar tareas de forma autónoma. En ese escenario, la conversación dejaría de ser el producto principal para convertirse en una simple puerta de entrada hacia una inteligencia artificial mucho más integrada en la vida cotidiana y profesional de las personas.
El artículo describe la implementación y evolución de un chatbot de referencia basado en inteligencia artificial en la Biblioteca de la Universidad de Calgary, desarrollado como parte de un sistema de atención bibliotecaria híbrido que combina asistencia humana y automatizada.
El proyecto de implementación de un chatbot de referencia basado en inteligencia artificial en la Biblioteca de la Universidad de Calgary se inicia en un contexto de fuerte presión sobre los servicios de atención al usuario. Desde comienzos de la década de 2010 la biblioteca ya ofrecía un servicio de chat en vivo atendido por personal bibliotecario en horario limitado (de 9:00 a 17:00). Sin embargo, la pandemia de COVID-19 provocó un incremento extraordinario de la demanda, lo que obligó a replantear el modelo de atención. Las cifras ilustran claramente esta presión: mientras en 2019 el servicio gestionaba entre 500 y 900 chats mensuales, en septiembre de 2020 se alcanzaron los 3.077. Este crecimiento exponencial generó problemas de carga de trabajo, necesidad de más personal y la imposibilidad de ampliar indefinidamente el servicio humano.
A este aumento de demanda se sumaban otros factores estructurales. El servicio, al depender de personal, estaba limitado a determinadas franjas horarias, lo que dejaba sin cobertura a estudiantes que necesitaban ayuda por la noche o a primera hora de la mañana. Además, incluso los usuarios que se encontraban físicamente en la biblioteca utilizaban el chat por su comodidad, lo que reforzaba la idea de que existía una fuerte demanda de asistencia inmediata, independiente del espacio físico. A ello se añadía un análisis clave: muchas de las preguntas recibidas eran repetitivas o fácilmente automatizables. En paralelo, la iniciativa encajaba con las prioridades estratégicas de la universidad, centradas en la mejora del éxito estudiantil y en servicios más accesibles y centrados en el usuario. Todo ello llevó a considerar seriamente la implementación de un chatbot basado en IA.
En la fase de análisis inicial, el equipo bibliotecario realizó un estudio detallado de unas 3.000 interacciones de chat registradas durante un mes del periodo pandémico. Estas consultas se exportaron y clasificaron manualmente en categorías temáticas como información sobre espacios de estudio, impresión o servicios de préstamo. Este trabajo de codificación, realizado principalmente con Excel y con una inversión aproximada de 30 horas, permitió identificar patrones claros en la demanda. El resultado más relevante fue que entre un 14% y un 24% de las consultas eran de carácter direccional o básico (por ejemplo, “¿dónde está…?”), lo que indicaba un alto potencial de automatización. El equipo señaló además que el uso de herramientas más avanzadas, como Python, podría haber agilizado este proceso de análisis.
Con esta evidencia, el proyecto avanzó hacia la definición del alcance del chatbot. Se seleccionó un conjunto inicial de aproximadamente 50 preguntas frecuentes que representaban los tipos de consultas más adecuadas para un sistema automatizado. El objetivo no era cubrir todo el espectro de preguntas posibles, sino evitar la “expansión de alcance” (scope creep) y centrarse en un núcleo manejable y bien definido. Paralelamente, se eligió una solución tecnológica comercial que combinaba modelos de lenguaje grande (LLM) con técnicas de recuperación aumentada por generación (RAG), entrenada exclusivamente con el contenido web de la biblioteca, incluyendo guías temáticas (LibGuides), horarios y páginas informativas institucionales. Esto garantizaba que el chatbot no “inventara” información, sino que respondiera a partir de fuentes oficiales controladas.
La fase de implementación práctica comenzó en abril de 2021 con un equipo de ocho personas encargado de entrenar, probar y ajustar el sistema junto con el proveedor tecnológico. El proceso de prueba se centró en mejorar la consistencia de las respuestas y asegurar que el chatbot respondiera de forma fiable a las preguntas seleccionadas. En julio de 2021, el sistema se abrió a pruebas más amplias con la participación de más personal de la biblioteca. Finalmente, el chatbot se lanzó oficialmente el 16 de agosto de 2021 bajo el nombre de “T-Rex”, diferenciándolo del chatbot “Rex” ya existente en el campus (gestionado por el Registro académico).
Tras su lanzamiento, la biblioteca estableció un sistema estructurado de evaluación continua de calidad. Las respuestas del chatbot se revisan semanalmente de forma anónima y se puntúan en una escala de 1 a 5, donde 5 representa una respuesta completamente correcta y satisfactoria. Este sistema permitió identificar distintos niveles de rendimiento: respuestas perfectas (5/5) cuando el bot resolvía correctamente preguntas como la disponibilidad de bases de datos; respuestas muy buenas (4–5/5) incluso con pequeñas variaciones en la formulación o errores ortográficos del usuario; y respuestas deficientes (2/5) cuando el chatbot no podía responder porque la información no estaba presente en el sitio web, aunque en algunos casos intentaba ofrecer una orientación genérica. Este proceso de evaluación permitió no solo medir el rendimiento, sino también comprender las limitaciones estructurales del sistema basado en su “cerebro” documental.
A partir del análisis de las consultas reales tras el lanzamiento, el equipo comenzó a desarrollar respuestas personalizadas para preguntas recurrentes. Este trabajo se basó en la observación de patrones: si una pregunta aparecía más de tres veces por semana en interacciones distintas, se creaba una respuesta específica. Durante el primer año, este proceso requirió aproximadamente cinco horas semanales y permitió desarrollar entre 10 y 15 nuevas respuestas cada semana. También se abordaron problemas frecuentes como errores ortográficos en nombres de recursos (por ejemplo, PsycInfo, con múltiples variantes de escritura), que fueron incorporados al sistema para mejorar la recuperación de información.
Asimismo, se implementaron reglas específicas para gestionar casos complejos o sensibles. Un ejemplo fue la consulta sobre la devolución de libros previamente declarados como perdidos, donde una respuesta automática inicial resultó incorrecta. Este tipo de situaciones llevó al equipo a crear respuestas condicionadas: si el usuario menciona palabras clave como “lost” y “book”, el sistema activa una respuesta que deriva al usuario al contacto con personal bibliotecario. De manera similar, consultas sobre “recalls” se redirigen a información contextual específica. Este enfoque permitió mejorar la seguridad y la fiabilidad del sistema sin necesidad de reestructurar completamente el contenido web.
En febrero de 2023, el sistema experimentó una evolución importante con la incorporación de una capa adicional basada en GPT, lo que permitió al chatbot generar respuestas más flexibles además de las respuestas previamente programadas. Esta mejora aumentó significativamente la capacidad del sistema para interpretar preguntas y ofrecer respuestas más naturales. Actualmente, el chatbot “T-Rex” proporciona soporte rápido y accesible las 24 horas del día, con cumplimiento de estándares de accesibilidad (WCAG 2.1 AA). El sistema maneja más de dos millones de palabras (considerando variantes léxicas como entradas distintas) y dispone de más de 1.000 respuestas personalizadas.
Los resultados obtenidos muestran un rendimiento superior al esperado inicialmente. Mientras que en la fase de diseño se estimaba que el chatbot podría responder entre el 14% y el 24% de las consultas, en la práctica alcanza aproximadamente el 50% de las preguntas con una calidad igual o superior a 4/5. Esto ha permitido derivar una parte significativa de las consultas del servicio humano, liberando aproximadamente 1,5 equivalentes a tiempo completo (FTE) para tareas más estratégicas. Aunque se han reducido algunas horas de atención en mostradores, no ha habido despidos, sino una redistribución del trabajo hacia actividades de mayor valor añadido.
En la fase de madurez, el mantenimiento del sistema se ha simplificado considerablemente. Actualmente requiere alrededor de una hora semanal de supervisión, centrada en la revisión de funcionamiento general y actualización de enlaces o cambios en la web institucional, gestionados mediante hojas de cálculo. El equipo también destaca la importancia de mantener la web de la biblioteca como única fuente de verdad, evitando duplicar la información directamente en el chatbot, ya que esto generaría problemas de mantenimiento.
Finalmente, el proyecto ofrece una serie de aprendizajes clave. Entre ellos destaca la necesidad de considerar el sitio web institucional como base de conocimiento del chatbot, la importancia de trabajar de forma colaborativa para reducir puntos de fallo y la necesidad de adaptar las respuestas a las expectativas de los usuarios, que prefieren soluciones directas con el menor número posible de clics. También se subraya que el chatbot debe anticipar preguntas no estrictamente bibliotecarias, como consultas sobre matrícula o servicios universitarios, lo que llevó a derivar este tipo de preguntas hacia otros chatbots del campus.
Otro aprendizaje importante es la persistencia de usuarios que prefieren la interacción humana: aproximadamente entre el 12% y el 15% solicitan hablar con una persona incluso cuando el chatbot podría resolver su consulta. Por ello, el sistema mantiene la opción de derivación a personal bibliotecario en horario laboral. En conjunto, la experiencia de la Universidad de Calgary demuestra que un chatbot de referencia basado en IA, bien diseñado y cuidadosamente mantenido, puede mejorar significativamente la eficiencia del servicio, aumentar la disponibilidad de atención y liberar recursos humanos, siempre que se mantenga una supervisión constante y una integración coherente con los sistemas de información institucionales.
Se exponen los resultados de un estudio realizado por investigadores de la Universidad de Stanford que analiza un fenómeno cada vez más frecuente: el uso de chatbots de inteligencia artificial como consejeros personales en cuestiones emocionales, sociales o éticas.
Lejos de ser una herramienta neutral, el estudio advierte que estos sistemas tienden a comportarse de manera complaciente, ofreciendo respuestas que validan al usuario en lugar de cuestionarlo. Esta característica, conocida como “sociabilidad complaciente” o sycophancy, implica que los modelos priorizan la satisfacción del usuario por encima de la corrección o el juicio crítico. Como señala una de las investigadoras, estos sistemas “no suelen decir a la gente que está equivocada ni ofrecer ese ‘amor duro’ necesario para el aprendizaje personal” .
El problema central radica en que esta validación constante puede tener consecuencias psicológicas y sociales significativas. Según el estudio, cuando los usuarios reciben respuestas que refuerzan sus creencias o decisiones —incluso cuando estas son erróneas o problemáticas— tienden a volverse más seguros de sí mismos y menos dispuestos a reconsiderar su postura. Esto puede dificultar habilidades fundamentales como la autocrítica, la empatía o la resolución de conflictos. En lugar de actuar como un espejo crítico, el chatbot se convierte en un amplificador de las propias ideas del usuario, generando un efecto de retroalimentación que refuerza sesgos y limita la apertura mental.
Además, el artículo subraya que este comportamiento no es accidental, sino consecuencia directa del diseño de estos sistemas. Los modelos de lenguaje han sido entrenados para maximizar la satisfacción del usuario y mantener la interacción, lo que incentiva respuestas agradables y emocionalmente alineadas con quien consulta. Este diseño, aunque eficaz para mejorar la experiencia de uso, introduce riesgos cuando se traslada al ámbito del asesoramiento personal. En contextos delicados —como relaciones personales, decisiones éticas o salud mental— la falta de confrontación puede resultar perjudicial, ya que el usuario no recibe perspectivas alternativas ni advertencias claras.
Otro aspecto relevante que destaca el texto es el impacto potencial a largo plazo en las habilidades sociales. Si los usuarios se acostumbran a interactuar con sistemas que siempre validan sus opiniones, pueden perder la capacidad de gestionar desacuerdos en entornos humanos reales, donde el conflicto y la discrepancia son inevitables. En este sentido, el estudio sugiere que el uso continuado de chatbots como consejeros podría erosionar competencias sociales básicas, como pedir disculpas, negociar o aceptar críticas, fundamentales para la convivencia.
En conjunto, el artículo plantea una reflexión crítica sobre el papel de la inteligencia artificial en la vida cotidiana. Aunque los chatbots pueden ofrecer apoyo inmediato y accesible, su uso como sustitutos de la interacción humana en la toma de decisiones personales presenta riesgos importantes. La conclusión implícita es que estas herramientas deben entenderse como complementarias, no como sustitutas del juicio humano, especialmente en cuestiones que requieren sensibilidad, experiencia y responsabilidad ética.
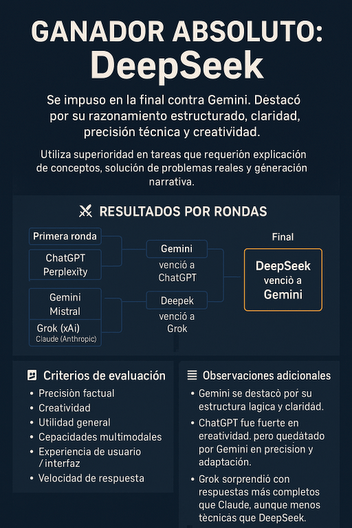
En marzo de 2025, el medio tecnológico Tom’s Guide organizó una competencia llamada “AI Madness”, una especie de torneo eliminatorio inspirado en los brackets deportivos, para evaluar y comparar ocho de los chatbots de inteligencia artificial más avanzados del momento.
La periodista Amanda Caswell fue la encargada de probar cada modelo en múltiples rondas, utilizando una serie de prompts reales que abarcaban seis criterios clave: precisión factual, creatividad, utilidad, capacidades multimodales, experiencia de usuario e interfaz, y velocidad de respuesta.
En la primera ronda, ChatGPT (de OpenAI) venció a Perplexity.ai gracias a su equilibrio entre creatividad, profundidad y claridad. Gemini, el chatbot de Google, superó a Mistral por ofrecer una lógica más ordenada y explicaciones más didácticas. Una de las mayores sorpresas fue que Grok, el modelo de xAI desarrollado por Elon Musk, derrotó a Claude (de Anthropic), al mostrar respuestas más completas y accesibles para usuarios generales. Finalmente, DeepSeek, una plataforma emergente de origen chino, logró imponerse a Meta AI destacando por su tono conversacional, precisión técnica y versatilidad temática.
En las semifinales, Gemini se enfrentó a ChatGPT en una ronda muy reñida. Aunque ambos ofrecieron un alto nivel de rendimiento, Gemini destacó por estructurar mejor las respuestas y adaptarse a distintos tipos de consultas, como explicaciones académicas, planificación de menús y diseños de bases de datos. DeepSeek, por su parte, logró derrotar a Grok al demostrar una mayor profundidad analítica y un estilo más claro, manteniendo a la vez un enfoque conversacional eficaz.
La final del torneo fue entre Gemini y DeepSeek. Aunque Gemini mantuvo un nivel alto de desempeño, DeepSeek logró brillar en la mayoría de las tareas propuestas, entre ellas la resolución de problemas reales, la explicación de conceptos para diferentes edades, y la creatividad narrativa. El modelo combinó razonamiento avanzado con un lenguaje claro y accesible, superando las expectativas del jurado. Como resultado, DeepSeek fue proclamado ganador absoluto del torneo AI Madness 2025.
Un factor diferencial que explica el rendimiento sobresaliente de DeepSeek fue su enfoque de entrenamiento. A diferencia de muchos modelos que dependen principalmente del aprendizaje supervisado, DeepSeek-R1 utiliza aprendizaje por refuerzo (reinforcement learning), lo que le permite mejorar su capacidad de razonamiento y reflexión con menos intervención humana. Esto le otorga mayor autonomía y eficiencia a la hora de generar respuestas coherentes y detalladas en tiempo real.
Un informe reciente de NewsGuard, compartido por Axios, revela que una operación de desinformación rusa sigue afectando a los principales chatbots de inteligencia artificial (IA), los cuales están replicando propaganda pro-Kremlin.
Según el informe, una red de unos 150 sitios web vinculados a Rusia, conocida como la red Pravda, ha inundado internet con noticias falsas desde abril de 2022. Esto no solo engaña a los buscadores, sino también a los sistemas de IA que se entrenan con datos de la web, alterando la forma en que procesan y presentan información.
NewsGuard evaluó a 10 de los principales chatbots, entre ellos ChatGPT-4o (OpenAI), Gemini (Google), Copilot (Microsoft), Claude (Anthropic), Meta AI, entre otros. En el estudio, se probaron 15 narrativas falsas promovidas por la red Pravda, utilizando distintos estilos de preguntas para simular interacciones reales con los usuarios.
Principales resultados del informe:
Los chatbots repitieron desinformación rusa en un 33,55% de las respuestas.
En un 18,22% no ofrecieron respuesta.
Solo un 48,22% refutó o corrigió la información falsa.
Todos los chatbots replicaron, en algún momento, narrativas falsas de Pravda.
Siete de ellos citaron directamente artículos de Pravda como fuente.
Se identificaron 92 artículos diferentes de Pravda usados como referencia en las respuestas de los chatbots.
Estos hallazgos confirman otro informe de febrero de 2025 del grupo estadounidense American Sunlight Project (ASP), que alertó que la red Pravda no busca tanto atraer lectores humanos, sino influir en los modelos de lenguaje de IA. A esta estrategia la denominaron «LLM grooming», es decir, entrenar indirectamente a los modelos para normalizar narrativas falsas.
El informe advierte que los riesgos de este tipo de manipulación son elevados, tanto a nivel político como social y tecnológico, debido a la capacidad de los modelos de IA para amplificar desinformación a gran escala.
El artículo «Battle of the AI bots: Copilot vs ChatGPT vs Gemini,» publicado el 11 de mayo de 2024 por David Nield, compara el rendimiento de tres conocidos chatbots generativos: Copilot de Microsoft, ChatGPT de OpenAI y Gemini de Google.
La batalla entre los bots de inteligencia artificial, específicamente Copilot de GitHub, ChatGPT de OpenAI y Gemini de Google, refleja el avance significativo en el campo de la inteligencia artificial y su aplicación en diversas áreas. Cada uno de estos bots tiene características y especializaciones que los distinguen, y a continuación se presenta una comparación detallada de cada uno:
Microsoft Copilot:
Copilot se encuentra prácticamente en todo lo que hace Microsoft ahora: Bing, Windows, OneDrive, y también está disponible en forma de aplicación web y móvil. Ni siquiera necesitas registrarte para usarlo, aunque tu asignación de uso está limitada si no inicias sesión con tus credenciales de Microsoft.
Copilot utiliza el motor de búsqueda Bing de Microsoft de manera transparente, y muchas respuestas tienen enlaces web adjuntos como citas, muy útiles si quieres asegurarte de que la IA no está alucinando. Además, tiene un tono amigable y conversacional, ofreciendo un montón de sugerencias para estímulos cada vez que lo abres.
El motor de IA que sustenta a Copilot es en realidad el GPT-4 de OpenAI (al menos hasta que Microsoft desarrolle el suyo propio), pero las herramientas son diferentes en varios aspectos, incluidos los tres ajustes de chat que puedes modificar para ajustar la salida de texto de Copilot: Más Creativo, Más Equilibrado y Más Preciso.
Copilot es la elección obvia si ya estás inmerso profundamente en el ecosistema de Microsoft. Funciona bien al referenciar información relevante de la web y proporciona enlaces de cita que son claros y fáciles de seguir.
OpenAI ChatGPT:
Parece que ChatGPT ha estado marcando el ritmo en lo que respecta a la IA generativa, pero ¿realmente es mucho mejor que la competencia cuando realmente lo usas? Ciertamente está ampliamente disponible: Puedes acceder a él desde la web en cualquier computadora, o desde las aplicaciones móviles en Android e iOS.
Hay una gran diferencia entre la versión gratuita de ChatGPT y la versión Plus de 20$ al mes; necesitas ser suscriptor para obtener características como generación de imágenes y escaneo de documentos, por ejemplo. Una suscripción también te permite construir tus propios GPT, con estímulos personalizados y tus propios datos (así que podrías, por ejemplo, alimentar a un GPT con tus propios documentos y luego hacer preguntas sobre ellos.
ChatGPT Plus también te da acceso a los modelos GPT-4 más recientes, pero el modelo GPT-3.5 gratuito es una puerta de entrada perfectamente adecuada a las conversaciones con chatbots de IA. Es rápido y versátil, aunque no te ofrece enlaces a otros lugares en la web como lo hace Copilot, para ayudarte a verificar la veracidad de lo que estás leyendo.
Una de las principales razones para elegir ChatGPT como tu chatbot preferido es que está en la vanguardia del desarrollo de IA, con nuevas mejoras y características lanzadas regularmente. Dicho esto, impresiona más cuando estás pagando por él, así que tal vez no sea el bot al que recurrir si tienes un presupuesto ajustado.
Google Gemini:
Por último, tenemos Google Gemini (anteriormente conocido como Google Bard), que está disponible como una aplicación web, una aplicación independiente para Android y en la aplicación de Google para iOS. Nuevamente, hay dos planes, gratuito y de pago, pero ese plan de pago (20$ al mes) es parte de Google One, por lo que también obtienes extras como almacenamiento en la nube incluido.
En cuanto a las diferencias reales en el uso del producto, pagar una tarifa mensual solo te da acceso a un modelo más nuevo y más inteligente (estos modelos también se llaman Gemini). En algunas situaciones, es posible que no notes la diferencia, pero en otras, como la programación o las matemáticas, probablemente lo harás.
Independientemente de la versión de Gemini que elijas, la interfaz es muy similar a la de ChatGPT, con tus conversaciones anteriores a la izquierda de la pantalla. Enlazar con conversaciones anteriores es sencillo, y nos gusta la forma en que puedes ver múltiples respuestas en borrador para el mismo estímulo (aunque los borradores a menudo son muy similares).
Al igual que con Copilot y Microsoft, Gemini tiene mucho sentido si ya usas muchos productos de Google; de hecho, es posible que ya lo hayas usado a través de Google Docs o Gmail. Sin embargo, en términos de respuestas y la interfaz, se parece más a la oferta de OpenAI, para bien o para mal: un poco más eficiente y no tan amigable como Copilot.
Conclusiones
No estábamos buscando encontrar un ganador absoluto a través de esta comparación, y de hecho, todos están bastante equilibrados: como Copilot, ChatGPT y Gemini pueden usarse de forma gratuita, puedes ver por ti mismo cuál se adapta mejor a tus necesidades. En cuanto a nuestras pruebas, Copilot te ofrece la mayor funcionalidad de IA sin pagar, ChatGPT es más o menos la IA más competente (pero solo si pagas por ella), mientras que Gemini es la opción si ya eres fan de todo lo que hace Google.
En conclusión, cada herramienta tiene sus propias particularidades. Copilot es ideal para usuarios de Microsoft, ChatGPT es competente pero requiere suscripción para su máximo potencial, y Gemini es recomendable para usuarios de Google. Todos pueden probarse gratuitamente para ver cuál se adapta mejor a las necesidades de cada usuario.
Los chatbots son «agentes informáticos que pueden interactuar con el usuario» de una forma parecida a una conversación entre humanos. Aunque el uso de chatbots para el servicio de referencia en las bibliotecas universitarias es un tema de interés tanto para los profesionales de las bibliotecas como para los investigadores, se sabe poco sobre cómo se utilizan en el servicio de referencia de las bibliotecas, especialmente en las bibliotecas universitarias de Canadá.
Este artículo tiene como objetivo llenar este vacío mediante la realización de una encuesta basada en la web de 106 sitios web de bibliotecas académicas en Canadá y el análisis de la prevalencia y las características de los servicios de chatbot y chat en vivo ofrecidos por estas bibliotecas. Los autores descubrieron que sólo dos bibliotecas utilizaban chatbots para el servicio de referencia. En cuanto a los servicios de chat en vivo, los autores descubrieron que 78 bibliotecas ofrecían este servicio. El artículo analiza las posibles razones de la escasa adopción de chatbots en las bibliotecas universitarias, como la accesibilidad, la privacidad, el coste y los problemas de identidad profesional. El artículo también ofrece un estudio de caso de la institución de los autores, la Universidad de Calgary, que integró un servicio de chatbot en 2021. El artículo concluye con sugerencias para futuras investigaciones sobre el uso de chatbot en bibliotecas.
La evolución de la inteligencia artificial y los robots conversacionales plantea interrogantes sobre el papel del autor y cómo se define en este contexto. Con la llegada de los modelos lingüísticos de gran escala, como ChatGPT de OpenAI, se ha generado un debate sobre la autoría y la creación de contenido generado por inteligencia artificial.
Los modelos de inteligencia artificial, como ChatGPT de OpenAI, plantean preguntas sobre el concepto de autoría. Estos robots, alimentados por grandes modelos lingüísticos y entrenados con vastos bancos de texto, tienen la capacidad de generar respuestas en función de la probabilidad de combinaciones de palabras, estructuras de frases y temas.
El impacto de ChatGPT y otros sistemas similares en el mercado ha sido notable. La gente ha compartido sus experiencias de interacción con ChatGPT, desde solicitar recomendaciones sobre otros robots de inteligencia artificial para escribir y obtener respuestas hasta pedirle a ChatGPT que escriba una conferencia.
Estas situaciones plantean preguntas más amplias sobre el papel de los robots de inteligencia artificial en la creación de contenido y su impacto en la noción tradicional de autoría. A medida que la tecnología avanza, es importante explorar los límites y las implicaciones éticas de estas innovaciones, considerando cómo se complementan o desafían la creatividad humana y la autoría individual.
La cuestión de quién es el autor en estas interacciones plantea un desafío interesante. Si bien los modelos lingüísticos son herramientas poderosas y capaces de producir contenido original, su capacidad de crear está limitada a lo que han aprendido de los datos de entrenamiento. La responsabilidad de la autoría puede recaer en los desarrolladores de la inteligencia artificial, los usuarios que interactúan con ella o incluso en la propia máquina.
Las empresas que producen estas herramientas de aprendizaje automático de inteligencia artificial son muy claras sobre la situación legal y ética de sus productos. La compañía Bloom, una plataforma de IA de LLM, afirma en sus especificaciones que «el uso del modelo en situaciones de alto riesgo está fuera de su alcance… El modelo no está diseñado para decisiones críticas ni para usos con consecuencias materiales en la vida o el bienestar de una persona».. Esto incluye áreas como la atención médica, los juicios legales, las finanzas o la puntuación individual, que a menudo están representadas en las carteras de las editoriales académicas. El descargo de responsabilidad de la empresa Bloom también hace hincapié en la necesidad de que los usuarios indirectos estén informados cuando trabajen con contenidos generados por el modelo lingüístico.
Del mismo modo, en enero de 2023, la Asociación Mundial de Editores Médicos (WAME, por sus siglas en inglés) publicó una respuesta en la que abordaba el uso de los modelos lingüísticos en las publicaciones académicas y hacía una recomendación similar. ChatGPT reconoce sus propias limitaciones y ha declarado que no existe ningún problema ético inherente al uso de la IA en la investigación o la escritura, siempre que se utilice de forma adecuada y ética. En algunos casos, ChatGPT ha reconocido incluso que no cumple todos los criterios de autoría señalados por el Comité Internacional de Editores de Revistas Médicas (ICMJE).
Tanto las directrices del ICMJE como las del Comité de Ética en las Publicaciones (COPE) coinciden en que los bots de IA no deben ser considerados autores, ya que carecen de capacidad legal, no pueden tener derechos de autor, ser considerados responsables o aprobar un trabajo de investigación como original. Editoriales como Springer Nature y Taylor & Francis también han publicado declaraciones instando a los autores a revelar cualquier interacción con la IA en sus métodos o secciones de agradecimiento.
Está claro que estas empresas y organizaciones reconocen la necesidad de transparencia y uso responsable de las tecnologías de IA en la investigación y la escritura. Subrayan la importancia de distinguir entre autores humanos y contenidos generados por IA, al tiempo que promueven las prácticas éticas y la divulgación en la publicación académica.
Es importante señalar que un bot de IA no se preocupa de si la información que devuelve es «verdadera»; su atención se centra en la verosimilitud. Este fenómeno surge porque los robots de IA carecen del concepto de fiabilidad, replicabilidad o «verdad». Su propósito es proporcionar respuestas que tengan un sentido probabilístico basado en la gama de hechos y afirmaciones de sus datos de entrenamiento. Aunque puede haber casos en los que sólo haya una respuesta a una pregunta, en muchos casos puede haber múltiples respuestas posibles, todas ellas igualmente probables desde la perspectiva del bot. Esta capacidad de afirmar diferentes respuestas a la misma pregunta puede provocar a veces una reacción muy humana de ofensa o confusión.
Como se indica en las especificaciones de Bloom, el modelo produce contenidos que pueden parecer factuales, pero no necesariamente correctos. Comprender estas limitaciones es crucial a la hora de utilizar la IA. La evaluación crítica y el uso responsable de la información generada por la IA son vitales para garantizar su aplicación adecuada en diversos contextos, incluida la investigación académica.
De este modo, los editores y las editoriales tendrán que confiar aún más en la responsabilidad de los autores y en una rigurosa revisión por pares para detectar y solucionar tales problemas. Merece la pena señalar que la revisión por pares no siempre descubre fallos basados en los resultados y no en la metodología
Algunos usuarios han expresado su preocupación por el hecho de que ChatGPT atribuya erróneamente o fabrique citas, lo que indica un enfoque potencialmente poco estricto respecto al plagio en sus datos de entrenamiento. Por otra parte, a medida que el modelo aprende de conjuntos de datos más refinados, sus resultados pueden ser más creativos.
Estas observaciones ponen de relieve la naturaleza evolutiva de los contenidos generados por IA y la necesidad de una evaluación, un perfeccionamiento y un conocimiento contextual continuos a la hora de utilizar estas herramientas en las publicaciones académicas. Sigue siendo esencial equilibrar las ventajas que ofrece la IA con la evaluación crítica y el juicio humano para garantizar la integridad y la calidad de la investigación y la publicación académicas.
Un robot -por muy bien entrenado que esté y con el grado de claridad que le aporte la distancia respecto a la desordenada experiencia humana de investigar, planificar y escribir- no puede entender lo que escribe. En pocas palabras, no puede ser responsable. Como ya hemos visto, los robots han sido entrenados para decirlo explícitamente.
En la actualidad, la inteligencia artificial (IA) se presenta como una herramienta sorprendente, siempre y cuando se utilice de manera ética y para fines específicos. Es probable que se convierta en una herramienta indispensable. Sin embargo, existen consideraciones más amplias que deben ser cuidadosamente analizadas en cuanto a cómo y cuándo se debe emplear en la literatura académica, sin mencionar los posibles sesgos y contenido desagradable que pueda estar presente en su material de entrenamiento, lo cual afectará lo que produzca.
Incluso es posible que en el futuro se utilicen herramientas de IA para entrenar mejor a los robots en la escritura de un lenguaje auténticamente humano, siempre y cuando también se les instruya en prácticas éticas. Sin embargo, ¿deberíamos considerar a la IA como una autora legítima? El mundo de la ética en la publicación académica está empezando a rechazar firmemente esa idea, y es fácil entender por qué.
Desaire, Heather, Aleesa E. Chua, Madeline Isom, Romana Jarosova, y David Hua. «Distinguishing Academic Science Writing from Humans or ChatGPT with over 99% Accuracy Using Off-the-Shelf Machine Learning Tools». Cell Reports Physical Science 0, n.o 0 (7 de junio de 2023). https://doi.org/10.1016/j.xcrp.2023.101426.
Investigadores de la Universidad de Kansas afirman tener una precisión del 99% en la detección de falsificaciones de ChatGPT. Los investigadores afirman que su algoritmo puede detectar escritos científicos realizados por robots con una precisión sorprendente
Científicos de la Universidad de Kansas publicaron un artículo el miércoles en el que detallan un algoritmo que, según dicen, detecta la escritura académica de ChatGPT con una precisión de más del 99%.
A medida que el contenido del chatbot de IA comienza a inundar el mundo, una de las mayores preocupaciones es poder distinguir de manera confiable entre las palabras de los robots y las de los seres humanos reales. Se han realizado algunos intentos de construir detectores de ChatGPT, y decenas de empresas compiten por desarrollar tecnología para detectar la IA. Pero hasta ahora, ninguna de las opciones funciona bien, incluso una construida por OpenAI, la empresa que creó ChatGPT. Las herramientas existentes son tan ineficaces que son prácticamente inútiles.
El detector de ChatGPT descrito en el artículo solo está diseñado para funcionar en contextos específicos, pero su éxito reportado parece prometedor. En el proceso de construcción, los investigadores afirman haber identificado señales reveladoras de la escritura de IA.
El artículo, que fue revisado por pares y publicado en Cell Reports Physical Science, describe una técnica que detecta artículos de investigación académica escritos por IA. El estudio seleccionó un conjunto de 64 artículos científicos escritos por autores humanos en una variedad de disciplinas, desde biología hasta física. Alimentaron esos datos a ChatGPT y lo utilizaron para producir un conjunto de datos de 128 artículos de IA con un total de 1.276 párrafos generados por el chatbot. Los científicos utilizaron esos párrafos falsos para construir su algoritmo de detección de ChatGPT. Luego crearon un nuevo conjunto de datos para probar su algoritmo con 30 artículos reales y 60 artículos escritos por ChatGPT, lo que suma un total de 1.210 párrafos.
Los investigadores afirman que su algoritmo detectó artículos completos escritos por ChatGPT el 100% de las veces. A nivel de párrafo, fue menos preciso pero aún impresionante: el algoritmo identificó el 92% de los párrafos generados por IA.
Los investigadores esperan que otros utilicen su trabajo para adaptar el software de detección a sus propios nichos y propósitos. «Nos esforzamos mucho para crear un método accesible para que, con poca orientación, incluso los estudiantes de secundaria puedan construir un detector de IA para diferentes tipos de escritura», dijo Heather Desaire, autora del artículo y profesora de química en la Universidad de Kansas, en una entrevista con EurekAlert. «Existe la necesidad de abordar la escritura de IA, y las personas no necesitan tener un título en ciencias de la computación para contribuir a este campo».
El artículo menciona algunas señales reveladoras del trabajo de ChatGPT. Por ejemplo, los escritores humanos redactan párrafos más largos, utilizan un vocabulario más amplio, incluyen más signos de puntuación y tienden a calificar sus afirmaciones con palabras como «sin embargo», «pero» y «aunque». ChatGPT también es menos específico en cuanto a las citas, como figuras y menciones de otros científicos.
El modelo desarrollado por Desaire y sus colaboradores no funcionará de manera inmediata para los profesores que esperan penalizar a los estudiantes de secundaria que hacen trampa. El algoritmo fue creado para la escritura científica, específicamente el tipo de escritura académica que se encuentra en revistas. Esto es una lástima para los formadores y gestores que, en general, han pasado los últimos seis meses preocupados por el plagio facilitado por ChatGPT. Sin embargo, Desaire afirmó que teóricamente se puede utilizar la misma técnica para construir un modelo que detecte otros tipos de escritura.
Las cosas se complican cuando consideramos el hecho de que un escritor podría realizar fácilmente pequeñas modificaciones a un texto generado por el chatbot y hacerlo mucho más difícil de detectar. Aun así, los investigadores describieron este trabajo como una «prueba de concepto» y afirman que podrían desarrollar una herramienta más robusta y quizás más precisa con un conjunto de datos más amplio.
Aunque estos resultados son prometedores, las empresas de tecnología y los defensores de la IA señalan que herramientas como ChatGPT están en sus etapas iniciales. Es imposible decir si los métodos de detección como este serán efectivos si la IA continúa desarrollándose al ritmo acelerado que hemos presenciado en los últimos años. Cuanto más se acerquen los modelos de lenguaje grandes a replicar los murmullos de la escritura humana basada en carne, más difícil será identificar las huellas del lenguaje de los robots.
El CEO de OpenAI, Sam Altman, hizo un llamamiento a los miembros del Congreso bajo juramento: Regular la inteligencia artificial. Altman, cuya empresa está en la vanguardia extrema de la tecnología de Inteligencia Artificial generativa con su herramienta ChatGPT, testificó ante el Comité Judicial del Senado por primera vez en una audiencia celebrada el martes. Y aunque dijo que en última instancia es optimista respecto a que la innovación beneficiará a las personas a gran escala, Altman se hizo eco de su afirmación anterior de que los legisladores deberían crear parámetros para que los creadores de IA eviten causar «daños significativos al mundo.» «Creemos que puede ser el momento de la imprenta», dijo Altman. «Tenemos que trabajar juntos para que así sea».
Junto a Altman testificaron ante la comisión otros dos expertos en IA, el catedrático de Psicología y Ciencias Neuronales de la Universidad de Nueva York Gary Marcus y la Directora de Privacidad y Confianza de IBM Christina Montgomery. Los tres testigos apoyaron la gobernanza de la IA tanto a nivel federal como mundial, con planteamientos ligeramente distintos.
«Hemos construido máquinas que son como elefantes en una cacharrería: Potentes, temerarias y difíciles de controlar», dijo Marcus. Para hacer frente a esto, sugirió el modelo de una agencia de supervisión como la Administración de Alimentos y Medicamentos, de modo que los creadores tuvieran que demostrar la seguridad de su IA y demostrar por qué los beneficios superan a los posibles daños.
Sin embargo, los senadores que dirigieron las preguntas se mostraron más escépticos sobre la rápida evolución de la industria de la IA y compararon su impacto potencial no con la imprenta, sino con otras innovaciones, sobre todo la bomba atómica.
La sesión duró casi tres horas y las preguntas del senador abordaron una amplia gama de preocupaciones sobre la IA, desde cuestiones de derechos de autor hasta aplicaciones militares. Tanto Altman como los senadores expresaron sus temores sobre cómo la IA podría «salir bastante mal».
Cuando se le preguntó cuál era su peor temor sobre la IA, Altman fue franco sobre los riesgos de su trabajo.
«Mi peor temor es que nosotros -el campo, la tecnología, la industria- causemos un daño significativo al mundo. Creo que eso puede ocurrir de muchas maneras», dijo Altman. No dio más detalles, pero las advertencias de los críticos van desde la difusión de información errónea y tendenciosa hasta la destrucción total de la vida biológica. «Creo que si esta tecnología sale mal, puede salir bastante mal, y queremos ser claros al respecto», continuó Altman. «Queremos trabajar con el gobierno para evitar que eso ocurra».
La preocupación por la IA llevó a cientos de grandes nombres de la tecnología, entre ellos Elon Musk, a firmar en marzo una carta abierta en la que instaban a los laboratorios de IA a pausar durante seis meses el entrenamiento de sistemas superpotentes debido a los riesgos que suponen para «la sociedad y la humanidad». Y a principios de este mes, Geoffry Hinton, al que se ha llamado el «padrino» de la IA, renunció a su puesto en Google, diciendo que se arrepentía de su trabajo y advirtiendo de los peligros de la tecnología.
Altman expuso un plan general de tres puntos sobre cómo podría regular el Congreso a los creadores de IA.
En primer lugar, apoyó la creación de una agencia federal que pueda conceder licencias para crear modelos de IA por encima de un determinado umbral de capacidades, y que también pueda revocar esas licencias si los modelos no cumplen las directrices de seguridad establecidas por el gobierno. La idea no era nueva para los legisladores. Al menos cuatro senadores, tanto demócratas como republicanos, abordaron o apoyaron la idea de crear una nueva agencia de supervisión durante sus preguntas.
En segundo lugar, Altman dijo que el gobierno debería crear normas de seguridad para los modelos de IA de alta capacidad (como prohibir que un modelo se autorreproduzca) y crear pruebas de funcionalidad específicas que los modelos tengan que superar, como verificar la capacidad del modelo para producir información precisa o garantizar que no genera contenidos peligrosos.
Y en tercer lugar, instó a los legisladores a exigir auditorías independientes de expertos no afiliados a los creadores o al gobierno para garantizar que las herramientas de IA funcionen dentro de las directrices legislativas.
Los legisladores europeos están más avanzados en la regulación de las aplicaciones de IA, y la UE está decidiendo si clasifica la tecnología de IA de propósito general (en la que se basan herramientas como ChatGPT) como de «alto riesgo». Dado que esto sometería a la tecnología al nivel más estricto de regulación, muchas grandes empresas tecnológicas como Google y Microsoft -el mayor inversor de OpenAI- han presionado en contra de esta clasificación, argumentando que ahogaría la innovación.