Blair, Elizabeth. “How an AI-Generated Summer Reading List Got Published in Major Newspapers.” NPR, May 20, 2025. https://www.npr.org/2025/05/20/nx-s1-5405022/fake-summer-reading-list-ai
El 20 de mayo de 2025, NPR informó que varios periódicos estadounidenses, incluidos el Chicago Sun-Times y una edición del Philadelphia Inquirer, publicaron una lista de lectura de verano que contenía títulos de libros ficticios atribuidos a autores reales. Esta lista fue generada parcialmente por inteligencia artificial y distribuida por King Features, una unidad de Hearst Newspapers.
En un episodio reciente que pone de relieve los crecientes retos en la era de la inteligencia artificial, varios medios estadounidenses de renombre publicaron una lista de libros recomendados para el verano, entre los que se incluían títulos completamente inventados, pero atribuidos a autores reales y prestigiosos. La lista fue elaborada por King Features, una filial de Hearst Newspapers, y distribuida a sus periódicos asociados como parte de un paquete editorial estacional.
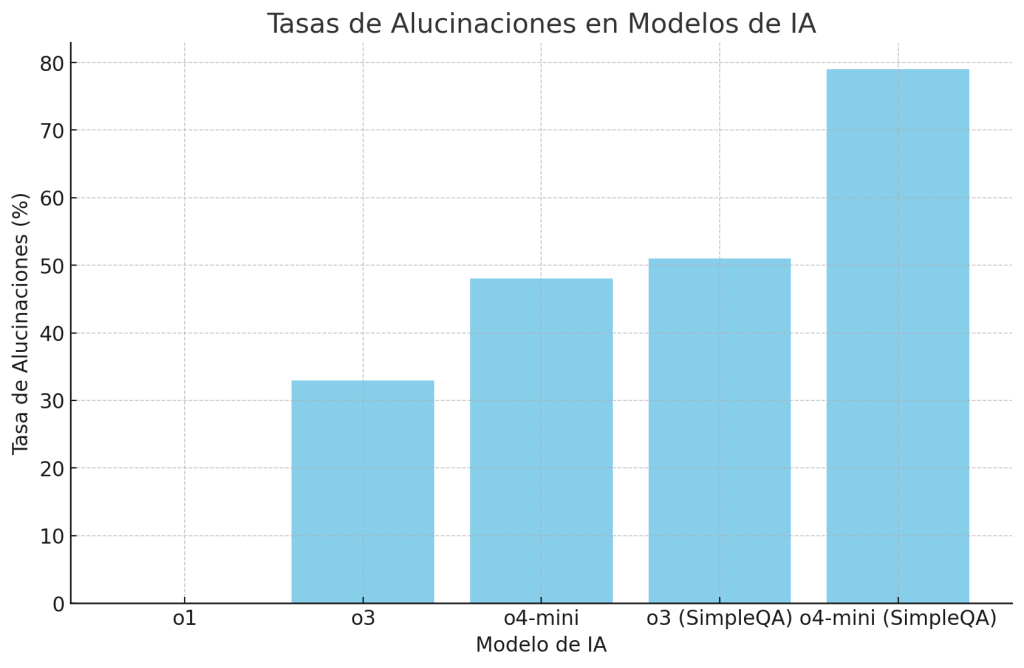
La lista se presentó como una selección de “libros esenciales para el verano”, pero contenía falsedades sorprendentes: títulos ficticios atribuidos a autores reales como Isabel Allende, Percival Everett y Cormac McCarthy, entre otros. Por ejemplo, uno de los libros inventados fue Tidewater Dreams de Allende, que no existe. Solo 5 de los 15 libros recomendados eran auténticos.
El contenido fue redactado por Marco Buscaglia, un colaborador independiente habitual. Buscaglia admitió haber utilizado una herramienta de inteligencia artificial (cuya identidad no se especifica en el artículo) para generar sugerencias literarias, y reconoció que no verificó si los títulos realmente existían. Esta falta de comprobación permitió que los títulos ficticios pasaran desapercibidos hasta que varios lectores y profesionales del mundo editorial empezaron a señalar errores tras la publicación.
Tanto el Chicago Sun-Times como el Philadelphia Inquirer, dos de los periódicos que publicaron la lista, han respondido asegurando que no fueron responsables directos del contenido, ya que este provenía del servicio editorial de King Features. Ambos medios han revisado internamente lo sucedido y se han comprometido a implementar controles más estrictos para evitar la publicación de información generada por IA sin revisión humana.
Este incidente ha generado un intenso debate sobre la ética y la práctica del uso de herramientas de IA en el periodismo. Aunque su uso puede ser eficiente, especialmente en tareas rutinarias o de apoyo, esta situación demuestra los peligros de confiar en la IA para generar contenido sin validación. La precisión, la reputación de los medios y la confianza del público están en juego.
También plantea interrogantes sobre la relación entre las agencias de contenido sindicadas y los periódicos locales. Al depender de servicios externos para llenar espacio en sus páginas —especialmente en secciones como cultura o estilo de vida— los medios corren el riesgo de ceder parte del control editorial y de comprometer su credibilidad si no ejercen la debida supervisión.
Los medios implicados han iniciado una reflexión sobre cómo deben gestionarse las colaboraciones con creadores de contenido y cómo utilizar la inteligencia artificial sin poner en riesgo la exactitud y la responsabilidad informativa. El caso también es un ejemplo de cómo el público, cada vez más atento y crítico, puede detectar errores que escapan a los filtros editoriales.
Este caso evidencia los límites del uso de la IA generativa en periodismo, sobre todo cuando no se combina con una revisión editorial rigurosa. La confianza en los medios, ya erosionada por otros factores en los últimos años, se ve aún más amenazada por errores de este tipo, que pueden parecer triviales, pero que en el fondo comprometen principios fundamentales como la veracidad y la responsabilidad.