
Péter Király, Empirical evaluation library catalogues. Issue 15: SWIB 2019, 2020
Texto completo
¿Cómo se debe describir un libro correctamente? Esta pregunta tiene un pasado largo (y un futuro aún más largo) con varios métodos propuestos que evolucionaron con el tiempo. En la época actual en la historia de la catalogación o, en otras palabras, en el control bibliográfico, vemos el final de un período y el comienzo de uno nuevo. En las últimas décadas, los profesionales e investigadores llamaron la atención sobre los diferentes inconvenientes de la catalogación legible por máquina, en breve MARC (ver frases ingeniosas famosas como «MARC debe morir» o «Síndrome de Estocolmo de MARC»), y hay una investigación intensiva sobre la próximo generación del esquema y el formato de metadatos bibliográficos adecuados, pero MARC no solo sigue con nosotros, sino que también genera la gran mayoría de los registros del catálogo.
Cuando en la década de 1960 Henriette Avram y sus colegas inventaron el formato MARC, el espacio de almacenamiento de información disponible era mucho menor que el de hoy en día, por lo que la información debería estar comprimida, por lo que una de las principales características técnicas del MARC es que siempre que una información puede ser descrita por un elemento de una lista cerrada de términos se optaría por este camino. El registro contiene formas abreviadas, mientras que la norma describe los términos abreviados en detalle. Esto dificulta la comprensión humana de MARC en su forma nativa, pero hace que la legibilidad de la máquina y por lo tanto la validación sea fácil. Al menos en teoría. El problema es que durante los decenios en que la estructura básica del MARC permaneció igual, éste siguió creciendo hasta convertirse en un estándar gigante, con una serie de diccionarios tan pequeños o grandes (que a veces son desarrollados y mantenidos externamente por otras organizaciones, como los esquemas de clasificación del contenido).
El propósito de esta investigación es estimar la calidad de los registros mediante la medición de las características estructurales, y encontrar los registros que podrían mejorarse. Con el análisis estadístico, los bibliotecarios y quienes deseen trabajar con datos o comprenderlos para diferentes fines pueden obtener una visión general del catálogo. Esta visión general podría ser útil también en la transición al nuevo formato bibliográfico. Conocer los datos es necesario cada vez, independientemente del formato. La investigación se manifiesta como un software de código abierto llamado Metadata quality assessment tool for MARC records. El código fuente de la herramienta se encuentra disponible en los siguientes repositorios: https://github.com/pkiraly/metadata-qa-marc (backend con una guía detallada para el usuario), https://github.com/pkiraly/metadata-qa-marc-web (interfaz de usuario basada en la web). Un sitio de demostración con los catálogos de la Universiteitsbibliotheek Gent (Bélgica) está disponible en http://134.76.163.21/gent/.
La forma ideal de flujo de trabajo de aseguramiento de metadatos sigue un ciclo particular (del cual la herramienta cubre los pasos 2-4):
- Ingerir/transferir datos del catálogo a la herramienta de medición
midiendo los registros individuales
- Agregación y análisis estadístico de las métricas de nivel de registro
informando
- Evaluación con expertos en la materia para mejorar los registros dentro del catálogo (si es necesario)
En comparación con otras herramientas MARC de código abierto, la principal característica de ésta, es que maneja la semántica de los datos. La herramienta contiene un modelo Java del estándar MARC21, por lo que lleva un registro de la siguiente información sobre los elementos de datos MARC: nombre, URL de la definición, códigos aceptables y su significado, restricciones de valor, reglas de indexación, funciones FRBR correspondientes, códigos históricos, diccionarios aplicables, nombre del BIBFRAME (si lo hay) y otras reglas. Está construido de manera extensible, por lo que el conjunto de reglas no sólo cubre MARC21, sino también varias variaciones MARC, como la versión MARC de la Deuthche Nationalbibliothek, OCLC MARC (no implementada completamente), y campos definidos localmente en diferentes bibliotecas (Gante, Szeged, Biblioteca Nacional de Finlandia). Cuando la herramienta lee un registro MARC, crea un triplete para cada elemento de datos: ubicación (campo, subcampo, etc.), valor, la definición del elemento de datos. De esta manera, puede validar todos los datos contra su definición. Dado que la definición, o un formato legible por la máquina del estándar MARC no está disponible en ningún otro lugar, la herramienta proporciona una forma de exportar este modelo de datos a un esquema JSON llamado Avram (llamado así por el creador de MARC).
La herramienta ejecuta un par de mediciones. Sus resultados (almacenados en archivos CSV) se visualizan mediante una interfaz web ligera. La interfaz de usuario está destinada al bibliotecario, y también contiene una interfaz de búsqueda para el catálogo, con el fin de conectar los resultados de los análisis y los registros.
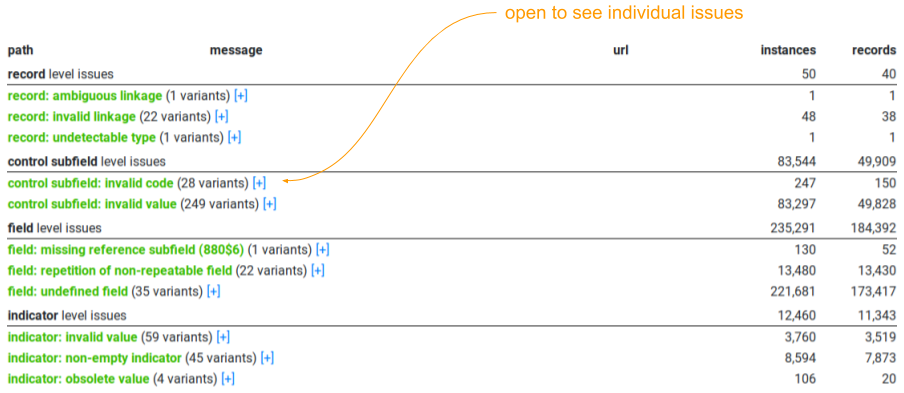
Los resultados de la validación agrupados por tipos de error (CC BY-SA)

Errores individuales. Las columnas son: ubicación (donde se produjo el error), valores problemáticos, enlace con la norma, número de ocurrencias, número de registros (CC BY-SA)
El análisis de validación itera todas las partes de los registros y comprueba si el valor se ajusta a las reglas de contenido, por ejemplo, si tiene una abreviatura adecuada, si la codificación de la fecha representa una fecha real o si los números ISBN/ISSN son válidos. Agrupa los errores según su ubicación (nivel de registro, campo de control, subcampo, etc.). Un problema común en casi todos los catálogos es que utilizan elementos de datos definidos localmente pero sin publicar su documentación. En esos casos, no es posible decidir si el valor de tal elemento sigue las reglas o no, por lo que la interfaz de usuario proporciona dos estadísticas: los errores que incluyen estos problemas y los errores «claros». El resultado de la validación de 16 catálogos de diferentes bibliotecas.

Este análisis comprobó cómo se distribuyen los grupos de campos y subcampos en la colección. Los grupos de campos son las grandes categorías bajo las cuales la norma MARC enumera los campos individuales, tales como Números y Código (campos 01X-09X), o Edición, Impresión (25X-28X). Las tablas resultantes muestran cuántos registros contienen un elemento de datos particular (tanto en recuento como en porcentaje), muestra las ocurrencias, sus tendencias centrales (media, desviación estándar, mínimo, máximo). La herramienta también muestra los términos principales dentro del elemento de datos, y el usuario puede ver qué registros contienen ese elemento.
Análisis funcional
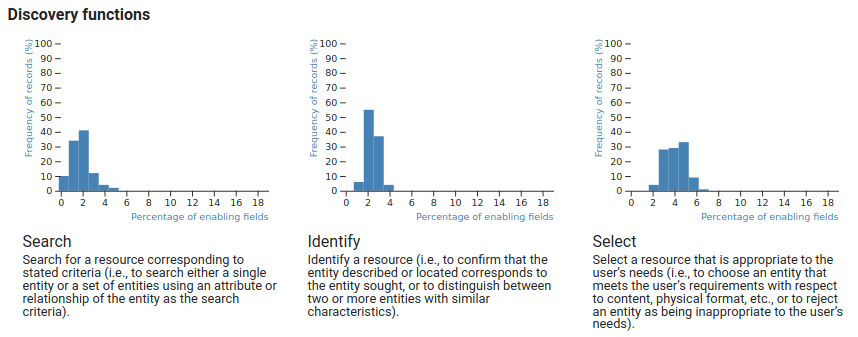
Análisis funcional (detalles). El eje y representa el número de registros, el eje x representa el porcentaje de los campos habilitantes disponibles en los registros.(CC BY-SA)
El FRBR define 12 funciones (como buscar, identificar, clasificar, mostrar) que deben ser apoyadas por los registros bibliográficos. Delsey inicializó un mapa entre estas funciones y los elementos de datos individuales. El análisis en esta etapa comprueba cuántas porciones de los elementos de datos pertenecientes a una función están disponibles en cada registro, y luego visualiza los histogramas del soporte de las funciones. Dado que un registro habitual contiene unos 200 elementos de datos, mientras que el mapa maneja más de 2000 elementos que apoyan funciones (el MARC21 define unos 3000 elementos), incluso los registros «más ricos» no pueden apoyar más del 10-15% de las funciones, por lo que los histogramas muestran un apoyo relativo. Su uso previsto es comparar el soporte de las funciones individuales, de modo que el bibliotecario puede concluir que un catálogo tiene más datos que apoyan la selección que la búsqueda.
Análisis de la materia (clasificación)

Figura 5. En la sección «Análisis de la materia (clasificación)») (CC BY-SA)
En el MARC, hay campos para apoyar diferentes métodos de la descripción del contenido. El análisis comprueba todos estos campos y explora cómo se utilizan: cuántos registros tienen por lo menos un contenido, cuántos términos se adjuntan al registro, qué tipos de esquemas de clasificación o sistemas de organización del conocimiento (SCO) se utilizan, cuáles son los campos adicionales junto al término (como la fuente del término, la versión del SCO, etc.) La interfaz de usuario proporciona enlaces a la lista de términos individuales dentro de un SCO, donde los enlaces de los términos desencadenan las búsquedas.
Análisis del nombre de la autoridad
Los nombres de las autoridades son más similares que los temas en cuanto a que proporciona nombres normalizados para personas, reuniones, sociedades e incluso títulos, que pueden o no contener información adicional, como identificadores de vocabularios, fechas y títulos asociados al nombre, naturaleza de la contribución en el registro actual. Este análisis sigue la estructura del análisis del tema.

Figura 6. (en la sección ‘Integridad ponderada’) (CC BY-SA)
Integridad de los campos MARC
La simple integridad tiene la misma importancia para cada campo. En la literatura, se sugieren dos soluciones para agregar pesos de campos para enfatizar la importancia. Thompson y Traill configuran un cálculo de puntuación para 19 elementos de datos que dan puntos por ocurrencias (en el rango de 0 a teóricamente ilimitado). Su propósito era seleccionar lo mejor de los proveedores de registros MARC proporcionados junto con los libros electrónicos. Carlstone siguió una estrategia similar pero estaba interesada en los registros MARC de series electrónicas (aquí un registro puede tener números negativos si pierde determinados elementos de datos). La herramienta implementa ambos análisis y proporciona visualizaciones para los histogramas de puntuación (tanto para la puntuación total como para los factores individuales).
Planes futuros
En el próximo período, nos gustaría concentrarme en los detalles del KOS, particularmente en dos cuestiones 1) si el registro se refiere a un KOS jerárquico, ya sea que utilice términos genéricos o específicos (situados cerca o lejos de los términos de nivel superior de la jerarquía) 2) si vemos el catálogo como un gráfico en el que los registros representan los nodos y los sujetos representan los bordes que conectan los registros entre sí, ¿cuál es la naturaleza de esta red? Otra dirección de desarrollo es mejorar la herramienta para cubrir otros formatos como PICAplus y UNIMARC. Trabajo en estas tareas con Verbundzentrale des GBV (Göttingen), ZBW – Leibniz-Informationszentrum Wirtschaft (Hamburgo) y la Agence bibliographique de l’emseignement supérieur (Montpellier). Estamos buscando una cooperación adicional con bibliotecas, por lo que si está interesado en esta investigación, ponte en contacto en pkiraly.github.io/contact/
References:
- Jakob Voß (2019) Avram Specification v0.4.0 (2019-05-09) https://format.gbv.de/schema/avram/specification
- Tom Delsey (2002) Functional analysis of the MARC 21 bibliographic and holdings formats. Tech. report, Library of Congress, 2002. Prepared for the Network Development and MARC Standards Office Library of Congress. Second Revision: September 17, 2003. https://www.loc.gov/marc/marc-functional-analysis/original_source/analysis.pdf.
- Kelly Thompson and Stacie Traill (2017) Implementation of the scoring algorithm described in Leveraging Python to improve ebook metadata selection, ingest, and management, Code4Lib Journal, Issue 38, 2017-10-18. http://journal.code4lib.org/articles/12828
- Jamie Carlstone (2017) Scoring the Quality of E-Serials MARC Records Using Java, Serials Review, 43:3-4, pp. 271-277, DOI: 10.1080/00987913.2017.1350525 URL: https://www.tandfonline.com/doi/full/10.1080/00987913.2017.1350525
- Péter Király (2019) Validating 126 million MARC records. In DATeCH2019 Proceedings of the 3rd International Conference on Digital Access to Textual Cultural Heritage pp. 161-168. DOI 10.1145/3322905.3322929







