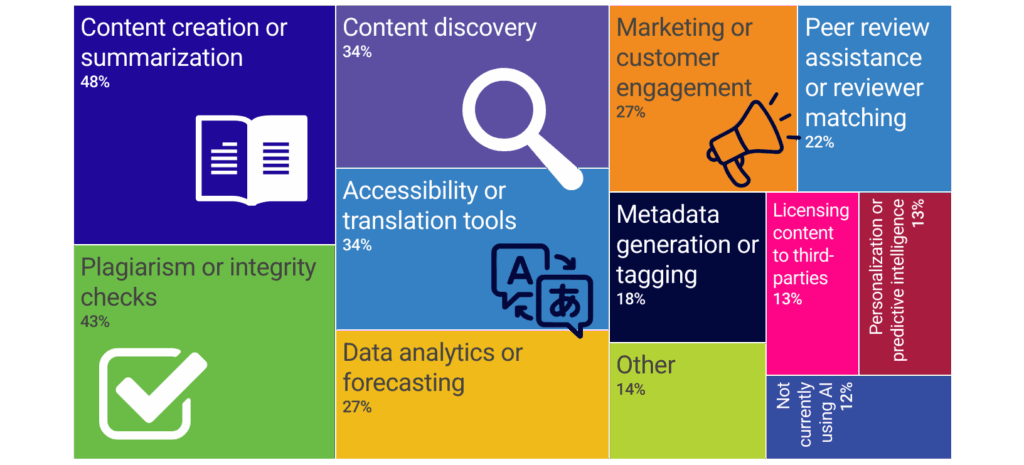
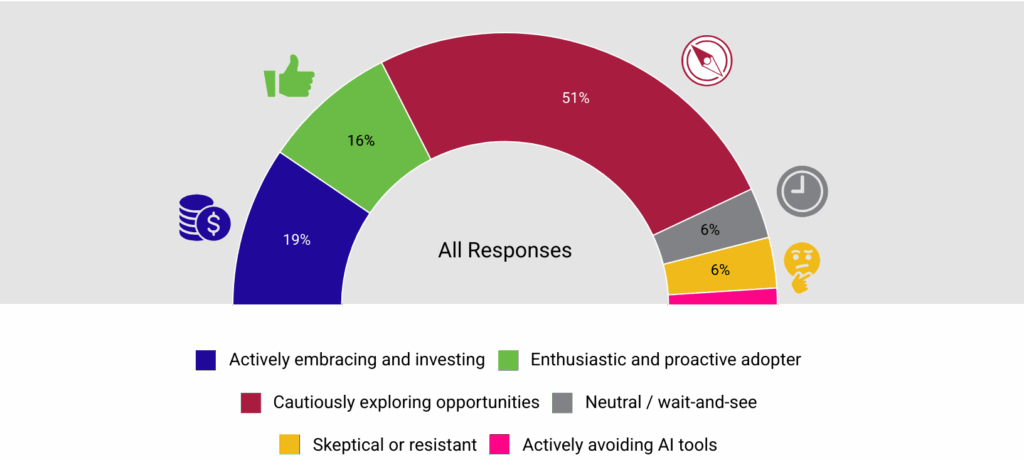
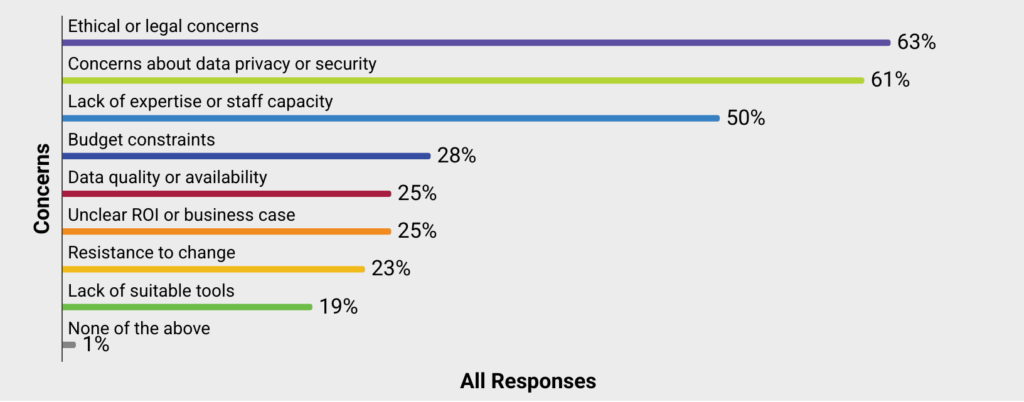
Winemiller, Sam. 2026. “OpenAlex and Values‑Aligned Tools.” ACRLog, 26 de enero de 2026. https://acrlog.org/2026/01/26/openalex-and-values-aligned-tools/
Se hace una llamada a la comunidad académica y bibliotecaria para cuestionar la hegemonía de herramientas comerciales en la evaluación científica y abrazar alternativas abiertas como OpenAlex —no solo por su utilidad técnica, sino también por su potencial para reflejar y reforzar valores compartidos de acceso abierto, inclusión y control comunitario sobre las infraestructuras que sostienen el conocimiento global.
La academia necesita desvincular de las entidades corporativas nuestra capacidad para comprender y evaluar la actividad académica. Compañías como Elsevier y Clarivate han integrado efectivamente métodos de evaluación en la academia que dependen de sus herramientas propietarias (Scopus y SciVal; Web of Science y Journal Citation Reports e InCites, respectivamente). De manera conveniente, estos productos también emiten juicios sobre la “legitimidad” de los lugares de publicación académica y sobre si son valiosos como líneas dentro de un expediente de promoción o para decisiones de suscripción bibliotecaria, lo que plantea preguntas sobre posibles conflictos de interés. Uno podría suponer que las revistas propiedad de Elsevier rara vez se excluyen del corpus de Scopus, por ejemplo.
La necesidad de separar la indexación y evaluación de la actividad académica del control corporativo coincide con la necesidad de recuperar cierto grado de control sobre todo el sistema de publicación académica. Un camino posible sería un cambio significativo hacia espacios gestionados por instituciones académicas, sociedades científicas o alianzas académicas, en lugar de editores con fines de lucro; sin embargo, un obstáculo básico para este cambio es la indexación inconsistente e incompleta de dichos espacios en gráficos de conocimiento científico como Scopus y Web of Science. En su reciente artículo sobre el tema, Nazarovets et al. (2026) concluyen con esta sugerencia: “…la visibilidad desigual de las UJs [revistas universitarias] resalta un punto ciego estructural en la evaluación global de la investigación: a menos que infraestructuras más inclusivas como DOAJ y OpenAlex sean ampliamente reconocidas y mejoradas en cuanto a cobertura y fiabilidad de metadatos, grandes partes de la producción académica permanecerán invisibles incluso si se decide abandonar WoS [Web of Science] y Scopus.” Este es solo uno de los posibles beneficios de invertir en infraestructura abierta como OpenAlex (tal como lo recomienda la UNESCO). La infraestructura abierta puede definirse como herramientas y recursos fundamentales, gratuitos, sobre los cuales se puede realizar, compartir y explorar la ciencia y la investigación abierta.
Para quienes no estén familiarizados con OpenAlex, es esencialmente una gran base de datos de trabajos académicos y metadatos relacionados. OpenAlex se centra en la inclusión amplia de trabajos académicos, en contraste con la “curaduría” de fuentes legítimas practicada por servicios propietarios. Posee una interfaz web y puede consultarse mediante API, pero en esencia es una infraestructura dedicada al dominio público a través de la licencia CC0, mantenida activamente por una organización sin fines de lucro (501(c)3). Por supuesto, depender de datos de citas reportados por los editores puede ser cuestionable, pero mientras trabajamos en reconocer y recompensar otros tipos de evidencia sobre el impacto de la investigación, al menos podemos usar datos de citas lo más completos posibles.
¿Es OpenAlex tan bueno como sus competidores? Según mi experiencia, suele ser igual o mejor para la mayoría de propósitos, como generar listas de publicaciones de autores, incluyendo preprints, o analizar tendencias de publicación en acceso abierto de una institución a lo largo del tiempo. La mayoría de quienes lo han explorado a fondo parecen coincidir. Culbert et al. (2024) analizaron la cobertura de referencias de OpenAlex en comparación con Web of Science y Scopus, encontrándola “comparable”, incluso antes de las recientes mejoras de OpenAlex, que incluyeron más de 50 millones de trabajos nuevos. En una revisión de Katina, Ho (2025) calificó a OpenAlex como “…una alternativa prometedora y fiable a las bases de datos de citas tradicionales por suscripción para investigadores, administradores universitarios, instituciones de investigación y organismos gubernamentales interesados en actividades de investigación y colaboraciones potenciales.” Otras herramientas de descubrimiento académico, como Overton, utilizan OpenAlex como fuente de datos fundamental.
Cada persona necesitará probarlo para evaluar si su usabilidad cumple con sus estándares, pero para quienes dudan, basta considerar que el simple uso de estas herramientas puede ser una pequeña contribución hacia un futuro diferente para la infraestructura de investigación. Los coordinadores involucrados en la Declaración de Barcelona sobre Información de Investigación Abierta comentaron sobre el compromiso de la declaración de apoyar infraestructuras para información de investigación abierta:
“Lo que creemos importante para las organizaciones es asumir seriamente su responsabilidad de apoyar estas infraestructuras, las cuales solo pueden existir y desarrollarse si son usadas y apoyadas. Esto incluye apoyo financiero, pero también puede involucrar participación en la gobernanza y contribuciones en especie, como aportar datos y mejorar su calidad. En cuanto a las contribuciones financieras, la Universidad de la Sorbona es un gran ejemplo: cuando se dieron de baja de Web of Science, redirigieron parte de ese presupuesto a apoyar OpenAlex. En general, abogamos por hacer de las inversiones en infraestructura abierta una parte integral de los presupuestos institucionales.”
Para muchos en bibliotecas universitarias, no contamos con recursos significativos para invertir o desinvertir, aunque votar con nuestro dinero sigue siendo una opción si tenemos autorización para hacerlo. Sin embargo, lo que sí está dentro de nuestro ámbito de influencia es aprender sobre infraestructura alineada con valores y usarla, aprovechando nuestras posiciones como profesionales de la información para enseñar y motivar a otros a usar infraestructura alineada con valores. En mi institución, hemos empezado con proyectos pequeños, como integrar OpenAlex en nuestra plataforma local de perfiles académicos y trabajar para añadir nuestro repositorio institucional como fuente de datos para OpenAlex. Ya sea OpenAlex u otra herramienta alineada con valores, podemos “votar” con nuestro uso como un pequeño acto diario de apoyo o resistencia. Enseñando sobre estas herramientas, pequeños actos individuales se convierten en poder colectivo.