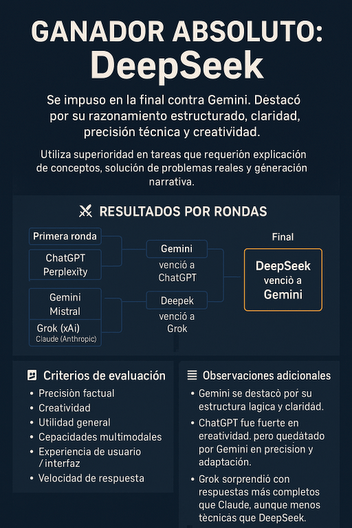
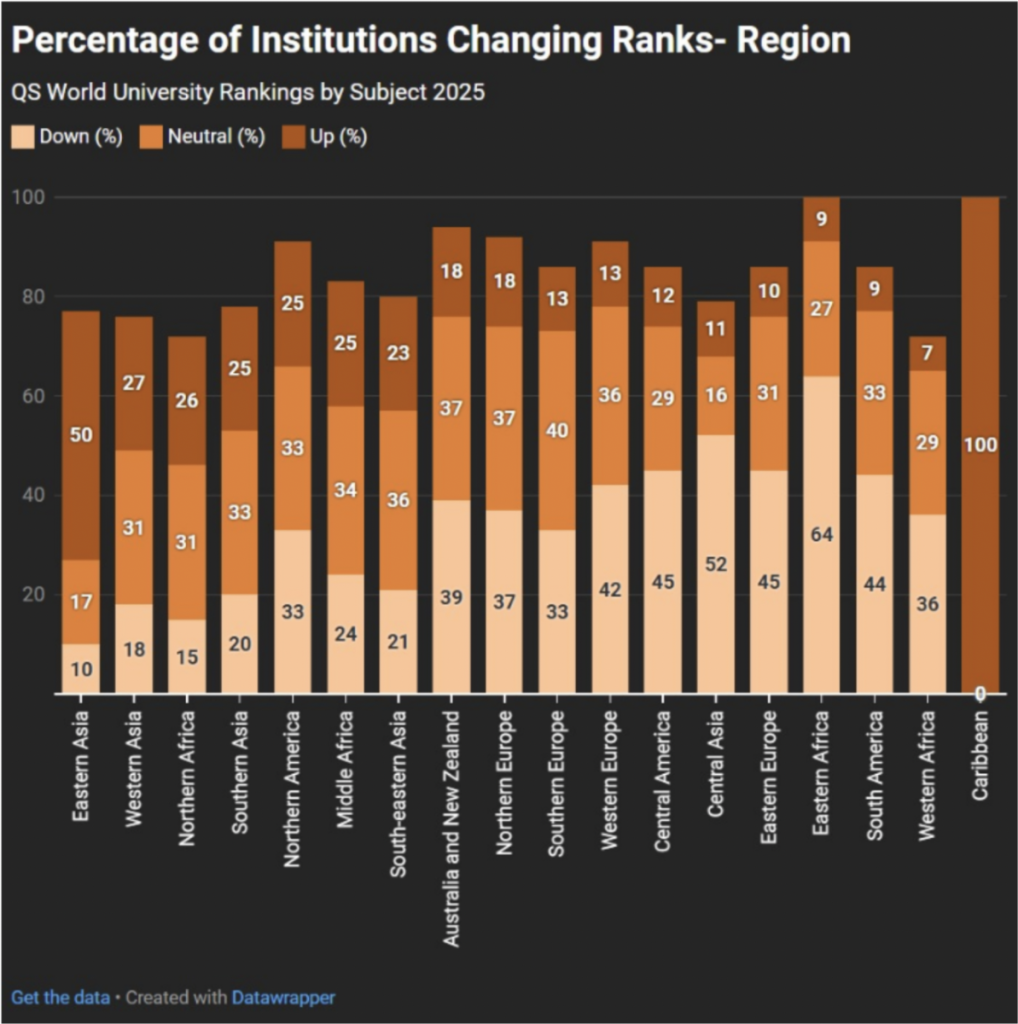
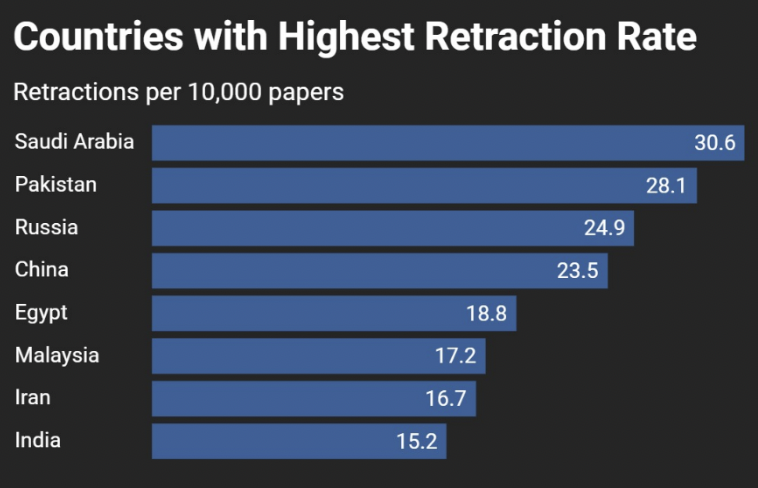
Weare, William H., Jaena Alabi, y John Fullerton. “What’s Working and What Isn’t: An Exploratory Study of Current Reference Models in Large Academic Libraries.” portal: Libraries and the Academy 25, n.º 4 (2025): 753-780. https://preprint.press.jhu.edu/portal/sites/default/files/09_25.4weare.pdf
El estudio analiza los modelos actuales de servicio de referencia en grandes bibliotecas universitarias, con el objetivo de identificar qué prácticas funcionan bien, cuáles presentan dificultades y cómo los cambios organizacionales afectan estas funciones.
Para ello, los autores entrevistaron a 15 responsables de servicios de referencia en universidades “land-grant” con alta matrícula (más de 20.000 estudiantes), situadas en Estados Unidos, utilizando un enfoque cualitativo con entrevistas semiestructuradas entre 2018 y 2019. Los entrevistados representaban instituciones sin programa acreditado de ciencias de la información, lo cual evitaba contar con un grupo de profesionales locales del gremio que pudiera distorsionar las dinámicas normales del servicio. Las entrevistas, con duración entre 43 y 73 minutos, fueron transcritas, codificadas y analizadas para identificar modelos de referencia, decisiones de personal y los factores que guiaban los cambios entre las diversas aproximaciones.
Los hallazgos revelan que no existe un modelo universal de referencia aplicado por todas las bibliotecas: muchas adoptan combinaciones adaptadas a su contexto institucional. Los autores identificaron siete enfoques dominantes: tradicional (con bibliotecarios atendiendo físicamente en escritorio), escritorio único combinado (referencia + circulación), peer-to-peer (estudiantes como asistentes de referencia), servicios escalonados (tiered), servicio “on call”, modelo de referencia por derivación (referral) y chat (o referencia virtual). En la práctica, los modelos no son mutuamente excluyentes; muchas bibliotecas combinan distintos enfoques según turno, necesidades del usuario o capacidades del personal. Un patrón frecuente es consolidar múltiples servicios en un solo mostrador para simplificar la experiencia del usuario y reducir la fragmentación de puntos de servicio.
Tres temas centrales atraviesan las decisiones institucionales: (1) la consolidación hacia un escritorio único de servicios, motivada por la necesidad de simplificar la experiencia del usuario y disminuir la confusión entre múltiples mostradores; (2) la retirada progresiva de bibliotecarios del servicio presencial directo, con la intención de liberar su tiempo para tareas especializadas, colaboración, docencia o proyectos externos; y (3) el aumento del uso de estudiantes en los puestos frontales de atención, como primer nivel de contacto, delegando a personal profesional preguntas más complejas. Entre las razones que impulsan estos movimientos destacan la reducción de la demanda presencial (caída de estadísticas de referencia), presiones institucionales para que los bibliotecarios asuman funciones de mayor impacto, cambios administrativos o de clasificación investigadora de la universidad, y un cuestionamiento sobre la eficiencia de tener personal altamente cualificado atendiendo consultas triviales.
Asimismo, el estudio señala que en muchas bibliotecas el volumen de consultas profundas es muy bajo; usando la escala READ (Reference Effort Assessment Data), varios entrevistados reportaron que un gran porcentaje de las preguntas corresponden a niveles bajos de complejidad, lo que sugiere que podrían atenderlas asistentes bien entrenados. Al mismo tiempo, se reconoce que la naturaleza de las preguntas ha evolucionado: aunque disminuye el volumen de preguntas básicas, los desafíos que llegan suelen ser más complejos y requieren intervención experta. En algunos casos, las instituciones mantienen el modelo tradicional por razones de identidad profesional, inercia institucional o porque sus bibliotecarios valoran el contacto directo con los usuarios.
En resumen, este estudio aporta evidencia cualitativa de que el futuro de los servicios de referencia en bibliotecas universitarias grandes se orienta hacia modelos híbridos, adaptativos y escalonados, más que hacia una sustitución total del servicio presencial o su configuración en un solo modelo rígido. La elección óptima depende del contexto institucional, cultura organizativa, recursos humanos y expectativas de los usuarios.