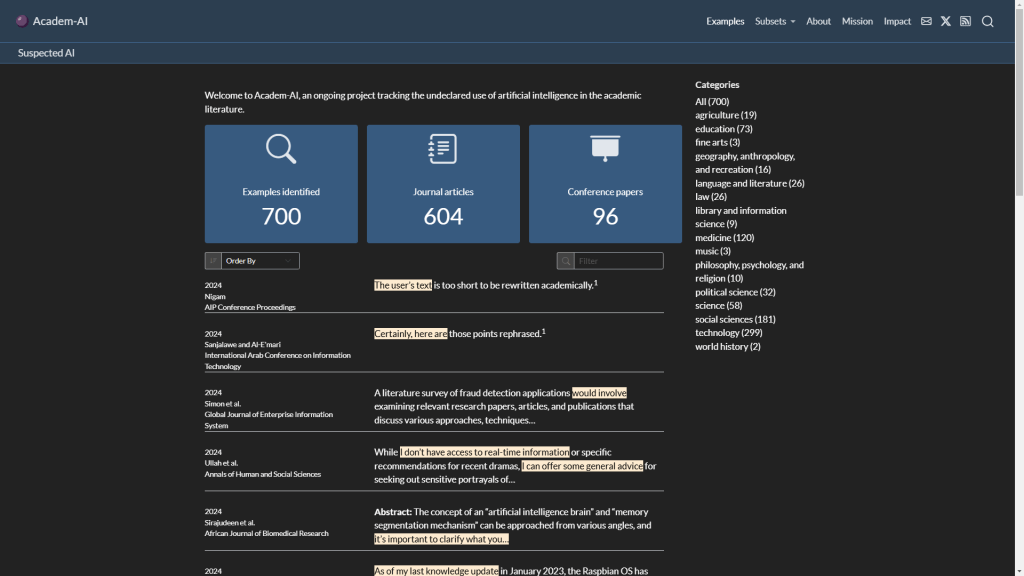
James Heathers, «How much science is fake? approximate 1 in 7 Scientific Papers Are Fake», 22 de septiembre de 2024, https://doi.org/10.17605/OSF.IO/5RF2M.
Un nuevo análisis realizado por James Heathers sugiere que uno de cada siete artículos científicos podría ser al menos parcialmente falso. Este estudio, publicado el 24 de septiembre en el Open Science Framework antes de la revisión por pares, se basó en datos de 12 estudios previos que analizaron aproximadamente 75.000 artículos. Heathers critica la cifra del 2% de fraude que se ha citado desde un estudio de 2009, argumentando que está desactualizada.
En 2009, un estudio ampliamente citado reveló que alrededor del 2% de los científicos admitían haber falsificado, fabricado o modificado datos en algún momento de su carrera. Esta cifra ha sido utilizada con frecuencia para ilustrar el problema del fraude en la ciencia. Sin embargo, 15 años después, James Heathers, investigador afiliado en psicología en la Universidad Linnaeus de Växjö, Suecia, decidió cuestionar esa cifra y ofrecer una estimación más actualizada y precisa. En su nuevo análisis, publicado el 24 de septiembre en el Open Science Framework antes de la revisión por pares, Heathers sugiere que uno de cada siete artículos científicos puede ser al menos parcialmente falso.
Heathers, conocido por su labor como «detective científico», llegó a esta conclusión al promediar datos de 12 estudios existentes. Estos estudios, que abarcan áreas como las ciencias sociales, la medicina y la biología, analizaron alrededor de 75.000 artículos para estimar el volumen de trabajos problemáticos. A través de una combinación de herramientas en línea que detectan irregularidades, Heathers encontró una «similitud persistente» entre las estimaciones de estos estudios y concluyó que, en promedio, uno de cada siete trabajos presenta errores o fraudes significativos.
Críticas a las estimaciones anteriores
Heathers explica que la cifra del 2% de fraude que proviene del estudio de 2009 está desactualizada, ya que el último conjunto de datos utilizado en ese estudio proviene de 2005. Durante los últimos 20 años, el entorno académico ha cambiado significativamente, y Heathers considera que esta cifra ya no refleja adecuadamente la magnitud del problema actual. Además, critica los enfoques anteriores que se centraban en preguntar directamente a los científicos si habían participado en prácticas deshonestas, calificando este método como ineficaz y poco fiable.
«Heathers señala que es ingenuo preguntar a los investigadores que cometen fraude si admitirán sus malas prácticas. En su lugar, propone utilizar herramientas más objetivas y datos indirectos para medir la magnitud del problema.»
Un enfoque «salvajemente no sistemático»
El propio Heathers reconoce que su estudio es «salvajemente no sistemático», ya que los datos que utilizó provienen de múltiples áreas y metodologías, y no existe un análisis homogéneo o riguroso que abarque todo el problema. Aun así, justifica su enfoque argumentando que esperar los recursos necesarios para realizar un análisis exhaustivo y sistemático tomaría demasiado tiempo, y que es importante comenzar a abordar el problema con los datos disponibles.
A pesar de sus limitaciones, Heathers decidió realizar un meta-análisis, ya que las cifras disponibles sobre la cantidad de ciencia fraudulenta son escasas. A su juicio, aunque se realice una revisión sistemática más formal, es probable que los resultados no difieran significativamente de su estimación preliminar de que uno de cada siete artículos es falso.
Críticas de otros expertos
El estudio ha recibido críticas de algunos expertos en la comunidad científica. Daniele Fanelli, un metacientífico de la Universidad Heriot-Watt en Edimburgo, Escocia, y autor del estudio de 2009, no está convencido de los resultados del nuevo análisis. Fanelli sostiene que el estudio de Heathers mezcla estudios que miden diferentes fenómenos y utiliza metodologías distintas, lo que puede llevar a conclusiones erróneas. Para Fanelli, etiquetar cualquier estudio con algún problema como «falso» no es un enfoque riguroso y podría llevar a una interpretación distorsionada del alcance real del fraude en la ciencia.
Fanelli también expresó su preocupación de que el estudio pueda atraer atención negativa e innecesaria de los medios, lo cual podría afectar la percepción pública de la ciencia sin un beneficio tangible para el campo.
Por su parte, Gowri Gopalakrishna, epidemióloga de la Universidad de Maastricht en los Países Bajos, también expresó reservas sobre las conclusiones de Heathers. Gopalakrishna coautorizó un estudio en 2021 que encontró que el 8% de los investigadores en una encuesta de casi 7.000 científicos en los Países Bajos admitieron haber falsificado o fabricado datos entre 2017 y 2020. Sin embargo, Gopalakrishna cree que la prevalencia del fraude puede variar significativamente entre diferentes campos de estudio, y agrupar todas las disciplinas bajo una misma cifra podría ser poco útil y conducir a interpretaciones erróneas.
Una amenaza existencial para la ciencia
A pesar de las críticas, Heathers sostiene que el problema del fraude en la ciencia representa una amenaza existencial para el campo y debe abordarse de inmediato. Argumenta que los científicos, las instituciones científicas y los organismos de financiación deben reconocer la gravedad del problema y actuar en consecuencia. El hecho de que un número significativo de publicaciones científicas pueda estar contaminado por fraudes o errores serios socava la confianza en el proceso científico y pone en riesgo el progreso del conocimiento.
Heathers también destaca que el fraude en la ciencia está «crucialmente subfinanciado» en términos de investigación y vigilancia, lo que agrava el problema. Aunque su estudio no es exhaustivo, espera que su trabajo sirva como un primer paso para abordar una cuestión que ha sido pasada por alto durante demasiado tiempo.