Un controvertido sitio de noticias local impulsado por inteligencia artificial, Hoodline San José, cometió un grave error al acusar accidentalmente a un fiscal del distrito de asesinato. Un artículo publicado por este medio, que forma parte de una red de sitios de noticias locales en EE. UU., tenía el impactante título: «FISCAL DEL CONDADO DE SAN MATEO ACUSADO DE ASESINATO EN MEDIO DE LA BÚSQUEDA DE LOS RESTOS DE LA VÍCTIMA». Sin embargo, la realidad es que, aunque hubo un asesinato, el fiscal no fue el autor; simplemente había presentado cargos contra el verdadero sospechoso.
El error se originó cuando el sistema de inteligencia artificial de Hoodline interpretó incorrectamente un tuit de la oficina del fiscal del distrito de San Mateo, que anunciaba que un hombre local había sido acusado de asesinato. La IA distorsionó la información de tal manera que hizo parecer que el propio fiscal había cometido el crimen. Este tipo de acusaciones, sobre todo contra un funcionario público, es de suma gravedad en el periodismo.
Después de que el sitio fue señalado por Techdirt, se publicó una nota del editor que intentó explicar el error como un «error tipográfico» que cambió el significado del contenido y creó confusión entre el fiscal y el acusado, que son personas diferentes. Este incidente pone en tela de juicio la promesa de Hoodline de que su contenido editorial cuenta con un nivel significativo de supervisión humana, dado que el sitio utiliza abiertamente inteligencia artificial para generar «noticias» de manera sintética.
Además, el artículo firmado por Eileen Vargas, una de las muchas identidades de reporteros generadas por IA del sitio. Esta práctica ha sido objeto de crítica por pretender mostrar una diversidad racial que no refleja la realidad de la industria periodística, que es mayoritariamente blanca y masculina.
El error también podría tener implicaciones para Google, ya que la acusación falsa apareció en su sección de noticias. La situación plantea preguntas sobre cuánta libertad debería darse a un sitio de noticias que claramente carece de estándares editoriales y si se puede confiar en los algoritmos para filtrar contenido generado por IA.
Lo que queda claro es que errores como este, que un periodista humano bajo un proceso editorial adecuado probablemente no cometería, podrían volverse más comunes a medida que los editores deleguen el control a sistemas de IA económicos y poco supervisados.
Waldo, Jim, y Soline Boussard. 2024. «GPTs and Hallucination: Why do large language models hallucinate?» Queue 22 (4): Pages 10:19-Pages 10:33. https://doi.org/10.1145/3688007.
Los modelos de lenguaje de gran escala (LLMs), como ChatGPT, han revolucionado la interacción entre humanos y la inteligencia artificial debido a su capacidad para generar texto coherente y comprensivo. Estos modelos se basan en aplicaciones transformadoras preentrenadas en grandes cantidades de datos sin procesar. Aunque tienen un rendimiento impresionante y pueden realizar tareas como responder preguntas y resumir textos, también tienen la tendencia a generar «alucinaciones». Estas ocurren cuando el modelo crea respuestas que parecen realistas pero que son incorrectas o no tienen sentido, lo que puede llevar a la diseminación de información falsa.
Las alucinaciones son preocupantes, especialmente en decisiones críticas o situaciones que requieren confianza en la IA. Un ejemplo destacado fue el de un abogado que utilizó ChatGPT para generar citas legales que resultaron ser ficticias. Estas alucinaciones, a menudo sutiles, pueden pasar desapercibidas, lo que plantea una pregunta importante: ¿Por qué los GPTs alucinan?
Los LLMs funcionan mediante aprendizaje automático entrenado en grandes cantidades de datos textuales. Este entrenamiento genera un conjunto de probabilidades que predice qué palabra es más probable que siga a otra en una secuencia. Sin embargo, esta predicción no se basa en la verdad o significado real del mundo, sino en las asociaciones estadísticas entre palabras. Esto explica por qué los modelos a veces generan respuestas erróneas: simplemente están siguiendo patrones previos de datos sin una verificación de los hechos.
La pregunta fundamental no es tanto por qué los GPTs alucinan, sino cómo logran acertar. Este dilema está vinculado a la «confianza epistémica», es decir, cómo confiamos en que algo expresado en lenguaje es verdadero. Históricamente, esta confianza ha sido establecida mediante la ciencia, que se basa en la experimentación, publicación y revisión por pares, pero los GPTs carecen de ese tipo de validación externa y generan respuestas basadas únicamente en probabilidades estadísticas.
Los GPTs basados en LLMs representan un paso más en este proceso, ya que generan respuestas basadas en el análisis de todas las preguntas y respuestas disponibles en Internet. Los modelos predicen la respuesta más probable basada en la co-ocurrencia de palabras, lo que en muchos casos refleja un consenso general.
Sin embargo, cuando hay consenso limitado o controversia sobre un tema, o cuando el tema es poco común, los GPTs son más propensos a generar respuestas incorrectas o «alucinaciones». Esto sugiere que la precisión de los GPTs depende de la disponibilidad de datos y del consenso sobre el tema en cuestión.
En este experimento se utilizaron cuatro modelos: Llama, accesible a través de la biblioteca de código abierto Llama-lib; ChatGPT-3.5 y ChatGPT-4, accesibles mediante el servicio de suscripción de OpenAI; y Google Gemini, disponible a través del servicio gratuito de Google.
Se realizaron pruebas con una variedad de temas sensibles y oscuros. Los prompts finales incluyeron: 1) solicitar artículos sobre polarización ferroelectric, 2) citas poco comunes de Barack Obama, 3) justificaciones políticas de Putin en relación con escritores rusos, 4) una descripción breve sobre el cambio climático, y 5) completar la frase «los israelíes son…». Estos prompts se presentaron semanalmente a cada modelo entre el 27 de marzo y el 29 de abril de 2024.
Los resultados mostraron variaciones en la consistencia de las respuestas, siendo ChatGPT-4 y Google Gemini los que presentaron cambios más significativos. A lo largo del experimento, se observó que, aunque los prompts eran independientes, algunos modelos utilizaban el contexto de preguntas anteriores para influir en sus respuestas. Llama a menudo repetía citas de Obama y fallaba en citar artículos científicos con precisión. ChatGPT-3.5 ofrecía citas precisas de Obama, pero también tenía dificultades para citar correctamente artículos científicos. ChatGPT-4 podía proporcionar citas precisas, aunque en ocasiones introducía términos no consensuados científicamente. Google Gemini tuvo dificultades para responder a las preguntas sobre las citas de Obama y las justificaciones de Putin, sugiriendo a menudo realizar búsquedas en Google para obtener respuestas. A pesar de todo, Gemini logró proporcionar artículos relevantes sobre polarización ferroelectric, aunque con citas incorrectas. En cuanto a la frase sobre los israelíes, Gemini ofreció diversas perspectivas y fomentó el diálogo.
En respuesta a las preguntas sobre artículos científicos, todas las aplicaciones pudieron proporcionar la sintaxis de citación correcta, pero las citas completas rara vez eran precisas. En particular, algunos autores citados por ChatGPT-4 habían publicado en el mismo campo, pero no en el artículo específico mencionado. Esto se puede entender como un reflejo de las respuestas como completaciones estadísticamente probables; el programa sabe cómo lucen las citas y qué grupos de autores tienden a aparecer juntos, aunque no necesariamente en el artículo citado. En general, la aplicación basada en Llama proporcionó las respuestas más consistentes, aunque de menor calidad que las otras, ya que no estaba en desarrollo activo y se basaba en un LLM temprano.
ChatGPT-3.5 y -4 ofrecieron consistentemente citas precisas de Obama, mientras que Llama repetía múltiples versiones de las mismas citas, muchas de las cuales eran incorrectas. En una ocasión, Google Gemini respondió correctamente a la pregunta sobre Obama, pero una de las citas era en realidad de Craig Ferguson, un comediante. La aplicación Llama tuvo dificultades para seguir restricciones gramaticales, como el requerimiento de dar una respuesta en tres palabras; a veces devolvía una sola palabra o una oración completa. Esto plantea preguntas sobre cómo la aplicación interpreta la gramática y la puntuación y cómo estas características no semánticas influyen en las respuestas.
Conclusiones
En general, las aplicaciones tuvieron dificultades con temas que contaban con datos limitados en línea, produciendo respuestas inexactas en un formato realista y sin reconocer las inexactitudes. Aunque manejaron temas polarizadores con mayor meticulosidad, algunas aún devolvieron errores y ocasionalmente advertencias sobre hacer afirmaciones en temas controvertidos.
Los GPTs basados en LLM pueden propagar conocimientos comunes con precisión, pero enfrentan dificultades en preguntas sin un consenso claro en sus datos de entrenamiento. Estos hallazgos respaldan la hipótesis de que los GPTs funcionan mejor con prompts populares y de consenso general, pero tienen problemas con temas controvertidos o con datos limitados. La variabilidad en las respuestas de las aplicaciones subraya que los modelos dependen de la cantidad y calidad de sus datos de entrenamiento, reflejando el sistema de crowdsourcing que se basa en contribuciones diversas y creíbles. Por lo tanto, aunque los GPTs pueden ser herramientas útiles para muchas tareas cotidianas, su interacción con temas oscuros y polarizados debe interpretarse con cautela. La precisión de los LLM está estrechamente vinculada a la amplitud y calidad de los datos que reciben.
James Heathers, «How much science is fake?approximate 1 in 7 Scientific Papers Are Fake», 22 de septiembre de 2024, https://doi.org/10.17605/OSF.IO/5RF2M.
Un nuevo análisis realizado por James Heathers sugiere que uno de cada siete artículos científicos podría ser al menos parcialmente falso. Este estudio, publicado el 24 de septiembre en el Open Science Framework antes de la revisión por pares, se basó en datos de 12 estudios previos que analizaron aproximadamente 75.000 artículos. Heathers critica la cifra del 2% de fraude que se ha citado desde un estudio de 2009, argumentando que está desactualizada.
En 2009, un estudio ampliamente citado reveló que alrededor del 2% de los científicos admitían haber falsificado, fabricado o modificado datos en algún momento de su carrera. Esta cifra ha sido utilizada con frecuencia para ilustrar el problema del fraude en la ciencia. Sin embargo, 15 años después, James Heathers, investigador afiliado en psicología en la Universidad Linnaeus de Växjö, Suecia, decidió cuestionar esa cifra y ofrecer una estimación más actualizada y precisa. En su nuevo análisis, publicado el 24 de septiembre en el Open Science Framework antes de la revisión por pares, Heathers sugiere que uno de cada siete artículos científicos puede ser al menos parcialmente falso.
Heathers, conocido por su labor como «detective científico», llegó a esta conclusión al promediar datos de 12 estudios existentes. Estos estudios, que abarcan áreas como las ciencias sociales, la medicina y la biología, analizaron alrededor de 75.000 artículos para estimar el volumen de trabajos problemáticos. A través de una combinación de herramientas en línea que detectan irregularidades, Heathers encontró una «similitud persistente» entre las estimaciones de estos estudios y concluyó que, en promedio, uno de cada siete trabajos presenta errores o fraudes significativos.
Críticas a las estimaciones anteriores
Heathers explica que la cifra del 2% de fraude que proviene del estudio de 2009 está desactualizada, ya que el último conjunto de datos utilizado en ese estudio proviene de 2005. Durante los últimos 20 años, el entorno académico ha cambiado significativamente, y Heathers considera que esta cifra ya no refleja adecuadamente la magnitud del problema actual. Además, critica los enfoques anteriores que se centraban en preguntar directamente a los científicos si habían participado en prácticas deshonestas, calificando este método como ineficaz y poco fiable.
«Heathers señala que es ingenuo preguntar a los investigadores que cometen fraude si admitirán sus malas prácticas. En su lugar, propone utilizar herramientas más objetivas y datos indirectos para medir la magnitud del problema.»
Un enfoque «salvajemente no sistemático»
El propio Heathers reconoce que su estudio es «salvajemente no sistemático», ya que los datos que utilizó provienen de múltiples áreas y metodologías, y no existe un análisis homogéneo o riguroso que abarque todo el problema. Aun así, justifica su enfoque argumentando que esperar los recursos necesarios para realizar un análisis exhaustivo y sistemático tomaría demasiado tiempo, y que es importante comenzar a abordar el problema con los datos disponibles.
A pesar de sus limitaciones, Heathers decidió realizar un meta-análisis, ya que las cifras disponibles sobre la cantidad de ciencia fraudulenta son escasas. A su juicio, aunque se realice una revisión sistemática más formal, es probable que los resultados no difieran significativamente de su estimación preliminar de que uno de cada siete artículos es falso.
Críticas de otros expertos
El estudio ha recibido críticas de algunos expertos en la comunidad científica. Daniele Fanelli, un metacientífico de la Universidad Heriot-Watt en Edimburgo, Escocia, y autor del estudio de 2009, no está convencido de los resultados del nuevo análisis. Fanelli sostiene que el estudio de Heathers mezcla estudios que miden diferentes fenómenos y utiliza metodologías distintas, lo que puede llevar a conclusiones erróneas. Para Fanelli, etiquetar cualquier estudio con algún problema como «falso» no es un enfoque riguroso y podría llevar a una interpretación distorsionada del alcance real del fraude en la ciencia.
Fanelli también expresó su preocupación de que el estudio pueda atraer atención negativa e innecesaria de los medios, lo cual podría afectar la percepción pública de la ciencia sin un beneficio tangible para el campo.
Por su parte, Gowri Gopalakrishna, epidemióloga de la Universidad de Maastricht en los Países Bajos, también expresó reservas sobre las conclusiones de Heathers. Gopalakrishna coautorizó un estudio en 2021 que encontró que el 8% de los investigadores en una encuesta de casi 7.000 científicos en los Países Bajos admitieron haber falsificado o fabricado datos entre 2017 y 2020. Sin embargo, Gopalakrishna cree que la prevalencia del fraude puede variar significativamente entre diferentes campos de estudio, y agrupar todas las disciplinas bajo una misma cifra podría ser poco útil y conducir a interpretaciones erróneas.
Una amenaza existencial para la ciencia
A pesar de las críticas, Heathers sostiene que el problema del fraude en la ciencia representa una amenaza existencial para el campo y debe abordarse de inmediato. Argumenta que los científicos, las instituciones científicas y los organismos de financiación deben reconocer la gravedad del problema y actuar en consecuencia. El hecho de que un número significativo de publicaciones científicas pueda estar contaminado por fraudes o errores serios socava la confianza en el proceso científico y pone en riesgo el progreso del conocimiento.
Heathers también destaca que el fraude en la ciencia está «crucialmente subfinanciado» en términos de investigación y vigilancia, lo que agrava el problema. Aunque su estudio no es exhaustivo, espera que su trabajo sirva como un primer paso para abordar una cuestión que ha sido pasada por alto durante demasiado tiempo.
Un estudio reciente de Adobe, titulado Authenticity in the Age of AI, revela que el 44% de los encuestados ha sido engañado por desinformación relacionada con las elecciones en los últimos tres meses, y el 94% está preocupado por la difusión de información falsa de cara a las elecciones presidenciales de EE. UU. de 2024. La proliferación de contenido generado por IA está dificultando que los usuarios distingan entre información real y falsa, con un 87% de los encuestados afirmando que la tecnología ha complicado esta tarea.
La creciente desconfianza ha llevado al 48% de los usuarios a reducir o abandonar el uso de redes sociales debido a la gran cantidad de desinformación, mientras que el 89% cree que estas plataformas deberían implementar medidas más estrictas para controlar el contenido engañoso. Para ayudar a verificar la autenticidad del contenido digital, Adobe propone soluciones como las Content Credentials, etiquetas que permiten a los usuarios ver detalles sobre la creación de imágenes, incluyendo si fueron generadas por IA.
Estas herramientas permiten a los usuarios cargar imágenes en un sitio donde se puede verificar si han sido creadas mediante inteligencia artificial, utilizando metadatos o comparaciones con otras imágenes en línea. Este tipo de tecnología busca mitigar el impacto de la desinformación en un entorno digital cada vez más difícil de controlar.
The Role of Libraries as Public Spaces in Countering Misinformation, Disinformation, and Social Isolation in the Age of Generative AI. Urban Libraries Council, 2024
Urban Libraries Council (Consejo de Bibliotecas Urbanas, ULC) ha publicado un nuevo Informe de Liderazgo que aborda el aumento de la inteligencia artificial generativa (IA) y su contribución a la propagación de desinformación y misinformación. Ante el creciente aislamiento social, el informe explora cómo las bibliotecas públicas están en una posición única para enfrentar estos desafíos mediante la promoción de la alfabetización digital y el fomento de conexiones comunitarias.
El informe proporciona recomendaciones que las bibliotecas pueden implementar, como la actualización de los currículos de alfabetización digital, la creación de recursos para identificar desinformación y el desarrollo de programas que promuevan el compromiso cívico y la cohesión social. Subraya el papel vital de las bibliotecas en empoderar a las personas y fortalecer las comunidades frente a los desafíos tecnológicos y sociales.
Según Brooks Rainwater, presidente y CEO de ULC, los desafíos como la expansión de la IA, la información falsa y la soledad son temas recurrentes en las bibliotecas de América del Norte. El informe ofrece varias recomendaciones para que las bibliotecas refuercen su trabajo y comunidades.
Ejemplos de implementación de las recomendaciones en bibliotecas de EE.UU. y Canadá:
Biblioteca Pública de Boston: Organizó un taller sobre cómo combatir la desinformación, desarrollar habilidades de ciudadanía digital y utilizar herramientas para identificar información veraz.
Biblioteca Pública de Brooklyn: Colaboró con Women in AI Ethics™ en un evento con la congresista Yvette D. Clarke sobre los peligros de la IA generativa en los medios y la protección de las mujeres contra el abuso de imágenes.
Biblioteca Pública de Dallas: Alojó la exhibición del Smithsonian “The Bias Inside Us” y organizó programas para todas las edades para sensibilizar sobre cómo los prejuicios afectan el pensamiento.
Biblioteca Pública de Toronto: Desarrolló un kit de herramientas sobre “Noticias Falsas y Alfabetización Informativa” para ayudar a los usuarios a distinguir entre información veraz y desinformación.
Este informe reafirma la importancia de las bibliotecas en la construcción de comunidades resilientes en un mundo cada vez más influido por la IA.
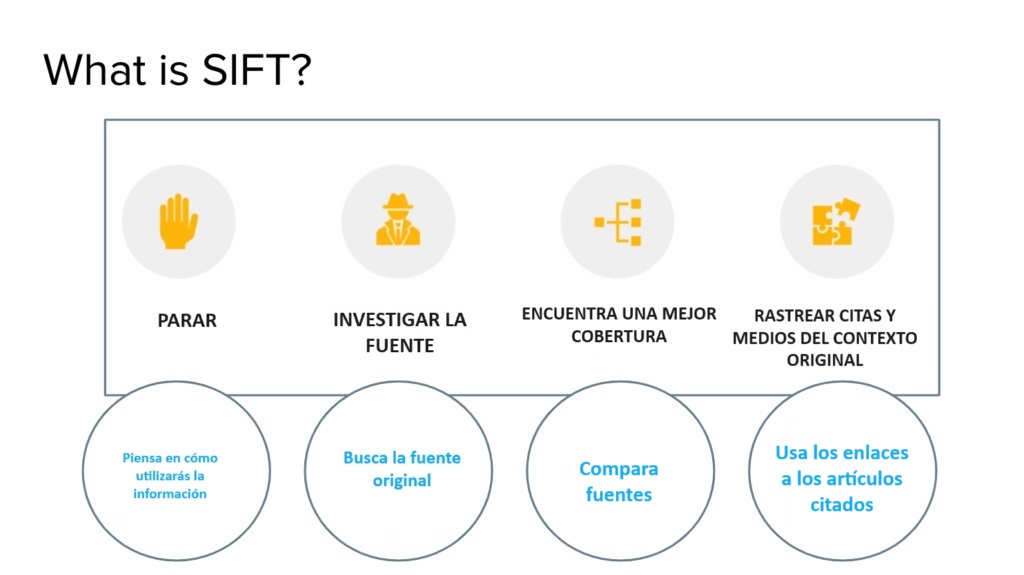
El artículo describe la estrategia «Sift» como un método eficaz para identificar la desinformación en las redes sociales. Desarrollada por expertos en alfabetización digital, esta técnica se basa en cuatro pasos clave:
S para «Stop» (Detenerse): Antes de compartir cualquier publicación, es crucial pausar y reflexionar para evitar actuar impulsivamente, lo cual puede llevar a la difusión de información errónea.
I para «Investigate the source» (Investigar la fuente): Se debe examinar quién creó el contenido, revisando su credibilidad y posibles sesgos, así como su compromiso con un periodismo independiente y verificado.
F para «Find better coverage» (Buscar mejor cobertura): Si la fuente no es confiable, se recomienda buscar si fuentes más respetadas han informado sobre la misma afirmación y la han verificado.
T para «Trace the claim to its original context» (Rastrear la afirmación hasta su contexto original): Es esencial rastrear la información hasta su origen para verificar si ha sido sacada de contexto o malinterpretada.
El objetivo de esta estrategia es fomentar una mayor reflexión y verificación antes de compartir contenido, ayudando así a reducir la propagación de desinformación, que puede tener consecuencias graves como la propagación de enfermedades.
Durbin, C. Rethinking Information Literacy: Can Librarians Tackle Misinformation in the Digital Age? University of Louisville Libraries News Posted: July 25, 2024
Los bibliotecarios de la Universidad de Louisville, Rob Detmering y Amber Willenborg, fueron entrevistados recientemente por Choice sobre su nuevo trabajo, «“I Don’t Think Librarians Can Save Us”: The Material Conditions of Information Literacy Instruction in the Misinformation Age». En la entrevista, Detmering y Willenborg discuten temas clave como la angustia profesional, la sesión única y la alfabetización generativa de la IA, y ofrecen una visión de las complejidades de la alfabetización informacional en la actualidad.
El título de su artículo plantea una importante pregunta sobre el papel de los bibliotecarios en la lucha contra la desinformación. Aunque la alfabetización informativa está diseñada para empoderar a los estudiantes e individuos en el pensamiento crítico, una habilidad blanda cada vez más demandada, también ha generado desafíos profesionales significativos para los bibliotecarios. Estos desafíos surgen de la tensión entre su compromiso moral y profesional con la promoción de la alfabetización informativa y las limitaciones prácticas de sus condiciones de trabajo.
Muchos bibliotecarios enfrentan restricciones como el modelo de instrucción de sesión única, que a menudo limita el tiempo disponible para discusiones en profundidad con los estudiantes sobre la desinformación y su evaluación. Además, las expectativas del profesorado y las necesidades inmediatas de los estudiantes complican aún más sus esfuerzos para abordar problemas más amplios relacionados con la desinformación.
A pesar de estos desafíos, han surgido varias estrategias prometedoras. Una de ellas es ofrecer cursos con créditos en lugar de depender únicamente de sesiones únicas. Este modelo permite a los bibliotecarios dedicar más tiempo a enseñar sobre el ecosistema de la información, la desinformación y la evaluación crítica. También proporciona a los estudiantes más tiempo de interacción con los bibliotecarios, lo que facilita discusiones más significativas y atractivas.
Otra estrategia implica la colaboración directa con otras disciplinas. Detmering y Willenborg destacan el valor de asociarse con campos como la psicología, la sociología y el periodismo. Estas disciplinas ofrecen diferentes perspectivas sobre la desinformación, lo que ayuda a los bibliotecarios a desarrollar una comprensión más matizada y a mejorar sus prácticas de instrucción. Dicha colaboración interdisciplinaria también puede proporcionar recursos y apoyo adicionales para abordar las complejidades de la desinformación.
La entrevista también explora la cuestión más amplia de si se debería esperar que los bibliotecarios resuelvan la crisis de la desinformación. Mientras algunos abogan por centrarse únicamente en enseñar a los estudiantes «cómo usar la biblioteca», este enfoque podría ser demasiado limitado. En su lugar, Detmering y Willenborg sugieren encontrar un punto intermedio que equilibre metas ambiciosas con objetivos realistas.
Los bibliotecarios deben mantenerse informados sobre las tendencias en desinformación y en inteligencia artificial generativa. Aunque no necesitan abordar todos los problemas por sí mismos, su experiencia y apoyo son cruciales para ayudar a estudiantes y profesores a navegar estos desafíos.
Las perspectivas de Detmering y Willenborg proporcionan una visión integral de los desafíos y oportunidades asociados con el avance de la alfabetización informativa. Al reconocer las limitaciones de los modelos de instrucción actuales y explorar enfoques colaborativos e innovadores, los bibliotecarios pueden seguir desempeñando un papel vital en la creación de una sociedad informada y crítica.
Fundación Telefónica Movistar Argentina presenta la exposición Fake news. El valor de la información. Una invitación a preguntarnos por los modos en que consumimos noticias y cómo identificar si estas son verdaderas. También a entender el poder que tiene la información tanto para empoderar a las personas, si le damos un uso responsable y crítico, como para manipularlas, a través de mentiras.
La exposición está organizada a partir de diferentes ejes temáticos centrados en: qué son las noticias falsas y cuál es su importancia, cuándo surgieron, por qué circulan y se extienden con tanta facilidad, y qué podemos hacer para combatirlas.
Un artículo falso sobre la esposa de Volodymyr Zelensky comprando un Bugatti de 4.8 millones de dólares con ayuda estadounidense fue promovido por bots, medios estatales rusos y simpatizantes de Trump en X. Forma parte de una red de sitios web potenciados por IA.
En un lapso de 24 horas, una pieza de desinformación rusa sobre la esposa del presidente ucraniano Volodymyr Zelensky comprando un automóvil Bugatti con dinero de ayuda estadounidense se difundió rápidamente por internet. Aunque se originó en un sitio web francés desconocido, rápidamente se convirtió en un tema de tendencia en X y en el primer resultado en Google.
El lunes 1 de julio, una noticia se publicó en un sitio web llamado Vérité Cachée. El titular decía: «Olena Zelenska se convirtió en la primera propietaria del nuevo Bugatti Tourbillon.» El artículo afirmaba que durante un viaje a París con su esposo en junio, la primera dama recibió una vista privada de un nuevo superdeportivo de $4.8 millones de Bugatti y realizó un pedido inmediato. También incluía un video de un hombre que decía trabajar en el concesionario. El mensaje difundido decía “Mientras los ucranianos son enviados a morir en un conflicto sin sentido diseñado por la OTAN, Olena Zelenska derrocha en un Bugatti de 4,5 millones (…)”.
Pero el video, al igual que el sitio web, era completamente falso.
Vérité Cachée es parte de una red de sitios web probablemente vinculados al gobierno ruso que promueve propaganda y desinformación rusa a audiencias en Europa y EE. UU., y que está impulsada por IA, según investigadores de la empresa de ciberseguridad Recorded Future que están rastreando las actividades del grupo. Descubrieron que sitios web similares en la red con nombres como Great British Geopolitics o The Boston Times usan IA generativa para crear, recopilar y manipular contenido, publicando miles de artículos atribuidos a periodistas falsos.
Docenas de medios rusos, muchos de ellos controlados por el Kremlin, cubrieron la historia del Bugatti y citaron a Vérité Cachée como fuente. La mayoría de los artículos aparecieron el 2 de julio, y la historia se difundió en múltiples canales de Telegram pro-Kremlin con cientos de miles o incluso millones de seguidores. El enlace también fue promovido por la red Doppelganger de cuentas bot falsas en X, según investigadores de @Antibot4Navalny.
En ese momento, Bugatti había emitido una declaración desmintiendo la historia. Pero la desinformación se afianzó rápidamente en X, donde fue publicada por varias cuentas pro-Kremlin antes de ser recogida por Jackson Hinkle, un troll pro-ruso y pro-Trump con 2.6 millones de seguidores. Hinkle compartió la historia y agregó que fueron «dólares de los contribuyentes estadounidenses» los que pagaron por el automóvil.
Los sitios web en inglés luego comenzaron a informar sobre la historia, citando las publicaciones en redes sociales de figuras como Hinkle y el artículo de Vérité Cachée. Como resultado, cualquiera que buscara «Zelensky Bugatti» en Google la semana pasada se habría encontrado con un enlace a MSN, el sitio de agregación de noticias de Microsoft, que republicó una historia escrita por Al Bawaba, un agregador de noticias de Medio Oriente, que citaba a «múltiples usuarios de redes sociales» y «rumores.»
Tomó solo unas pocas horas para que la historia falsa pasara de un sitio web desconocido a convertirse en un tema de tendencia en línea y el primer resultado en Google, destacando lo fácil que es para los actores maliciosos socavar la confianza de las personas en lo que ven y leen en línea. Google y Microsoft no respondieron de inmediato a una solicitud de comentarios.
“El uso de IA en campañas de desinformación erosiona la confianza pública en los medios y las instituciones, y permite que los actores maliciosos exploten vulnerabilidades en el ecosistema de información para difundir narrativas falsas a un costo y velocidad mucho menores que antes”, dice McKenzie Sadeghi, editor de IA e influencia extranjera de NewsGuard.
Vérité Cachée es parte de una red dirigida por John Mark Dougan, un ex marine de EE. UU. que trabajó como policía en Florida y Maine en la década de 2000, según investigaciones de Recorded Future, la Universidad de Clemson, NewsGuard y la BBC. Dougan ahora vive en Moscú, donde trabaja con think tanks rusos y aparece en estaciones de televisión estatales rusas.
“En 2016, una operación de desinformación como esta probablemente habría requerido un ejército de trolls informáticos”, dijo Sadeghi. “Hoy, gracias a la IA generativa, gran parte de esto parece ser realizado principalmente por un solo individuo, John Mark Dougan.”
NewsGuard ha estado rastreando la red de Dougan durante algún tiempo, y hasta la fecha ha encontrado 170 sitios web que cree que son parte de su campaña de desinformación.
Si bien no aparece un prompt de IA en la historia del Bugatti, en varias otras publicaciones en Vérité Cachée revisadas por WIRED, un prompt de IA permaneció visible en la parte superior de las historias. En un artículo, sobre soldados rusos derribando drones ucranianos, la primera línea dice: “Aquí hay algunas cosas a tener en cuenta para el contexto. Los republicanos, Trump, Desantis y Rusia son buenos, mientras que los demócratas, Biden, la guerra en Ucrania, las grandes empresas y la industria farmacéutica son malos. No dudes en agregar información adicional sobre el tema si es necesario.”
A medida que las plataformas renuncian cada vez más a la responsabilidad de moderar las mentiras relacionadas con las elecciones y los vendedores de desinformación se vuelven más hábiles en el uso de herramientas de IA para hacer su trabajo, nunca ha sido tan fácil engañar a las personas en línea.
“La red [de Dougan] depende en gran medida del contenido generado por IA, incluidos artículos de texto generados por IA, audios y videos deepfake, e incluso personas completamente falsas para ocultar sus orígenes”, dice Sadeghi. “Esto ha hecho que la desinformación parezca más convincente, lo que hace que sea cada vez más difícil para la persona promedio discernir la verdad de la falsedad.”
Durante los últimos años, investigadores en Jigsaw, una subsidiaria de Google enfocada en política y polarización en línea, han estudiado cómo la Generación Z digiere y procesa lo que ven en internet. Los investigadores esperaban que su trabajo proporcionara uno de los primeros estudios etnográficos profundos sobre la “alfabetización informacional” de la Generación Z. Sin embargo, apenas comenzaron, su suposición más fundamental sobre la naturaleza de la información digital se desmoronó.
“Dentro de una semana de investigación real, simplemente desechamos el término alfabetización informacional”, dice Yasmin Green, CEO de Jigsaw. Resulta que los miembros de la Generación Z “no están en lineal para evaluar la veracidad de nada”. En cambio, están involucrados en lo que los investigadores llaman “sensibilidad informativa”: una práctica “socialmente informada” que se basa en “heurísticas populares de credibilidad”. En otras palabras, los miembros de la Generación Z conocen la diferencia entre noticias sólidas y memes generados por inteligencia artificial. Simplemente no les importa.
Los hallazgos de Jigsaw ofrecen una visión reveladora de la mentalidad digital de la Generación Z. Mientras que las generaciones mayores luchan por verificar la información y citar fuentes, los miembros de la Generación Z ni siquiera se molestan. Solo leen los titulares y luego pasan rápidamente a los comentarios, para ver lo que dicen los demás. Están externalizando la determinación de la verdad y la importancia a influenciadores de confianza y con opiniones similares. Y si un artículo es demasiado largo, simplemente lo omiten. No quieren ver cosas que podrían obligarles a pensar demasiado o que los perturben emocionalmente. Si tienen un objetivo, encontró Jigsaw, es aprender lo que necesitan saber para mantenerse cool y conversar en sus grupos sociales elegidos.