En contraste con muchas instituciones occidentales que aún ven la IA como una amenaza, las universidades chinas están adoptando una estrategia proactiva. Lo que antes era desaconsejado —como el uso de ChatGPT en tareas académicas— ahora se alienta activamente, siempre que se haga con buenas prácticas. Un informe revela que solo el 1 % del profesorado y del alumnado afirma no haber usado herramientas de IA, y cerca del 60 % las utiliza frecuentemente, ya sea varias veces al día o semanalmente.
Este cambio refleja una tendencia a reconocer la IA no como un problema, sino como una habilidad esencial para el siglo XXI.
El surgimiento del modelo chino DeepSeek ha sido crucial. Varias universidades —como la de Shenzhen, Zhejiang, Shanghai Jiao Tong y Renmin— ya han incorporado cursos basados en DeepSeek. Estos programas no solo enseñan tecnología, sino que abordan también temáticas clave como la seguridad, la privacidad y la ética. Este enfoque holístico está alineado con el plan nacional China 2035, que busca un sistema educativo de alta calidad e inclusivo.
Un estudio reciente sobre estudiantes de ingeniería en China encontró que más de la mitad reconoce una mejora en su eficiencia, iniciativa y creatividad al usar IA generativa. Casi la mitad añadió que esta tecnología también potenció su pensamiento independiente. No obstante, hubo cierta preocupación sobre la precisión y confiabilidad específica de dominio, y muchos no percibieron una mejora significativa en sus calificaciones académicas.
El caso chino no es aislado. Técnicamente, a nivel mundial, la IA generativa ha comenzado a definir nuevas dinámicas educativas:
En Occidente, el enfoque aún gira en torno a detectar y sancionar su uso. Pero mientras muchos luchan por controlar su presencia, China ya la ve como una competencia y una herramienta empoderadora MediumLinkedIn.
Existe un impulso claro hacia integrar IA en todos los niveles educativos —incluyendo exámenes y libros de texto— para fomentar el pensamiento crítico y la resolución de problemas
Diversos servidores de preprints —como PsyArXiv, arXiv, bioRxiv y medRxiv— están detectando un aumento en el número de manuscritos que parecen haber sido generados o asistidos por inteligencia artificial o incluso por fábricas de artículos («paper mills»). Este comportamiento plantea serias dudas sobre la integridad de la ciencia abierta y la velocidad de publicación sin control.
Un caso emblemático involucró un manuscrito titulado “Self-Experimental Report: Emergence of Generative AI Interfaces in Dream States” publicado en PsyArXiv. El estilo estrambótico del contenido, la falta de afiliación del autor y la ausencia de detalles claros sobre el uso de IA llevaron a una alerta lanzada por la psicóloga Olivia Kirtley, quien luego solicitó su eliminación. Aunque el autor afirmó que la IA solo tuvo un papel limitado (como cálculo simbólico y verificación de fórmulas), no lo declaró explícitamente, lo que violó las normas del servidor.
En el servidor arXiv, los moderadores estiman que aproximadamente un 2 % de las presentaciones son rechazadas por tener indicios de IA o ser elaboradas por paper mills.
En bioRxiv y medRxiv, se rechazan más de diez manuscritos al día que resultan sospechosos de ser generados de forma automatizada, dentro de un promedio de 7.000 envíos mensuales
Los servidores de preprints reconocen un incremento reciente en contenido generado por IA, especialmente tras el lanzamiento de herramientas como ChatGPT en 2022. Esto ha generado una crisis creciente en apenas los últimos meses. El Centro para la Ciencia Abierta (Center for Open Science), responsable de PsyArXiv, expresó públicamente su preocupación por esta tendencia.
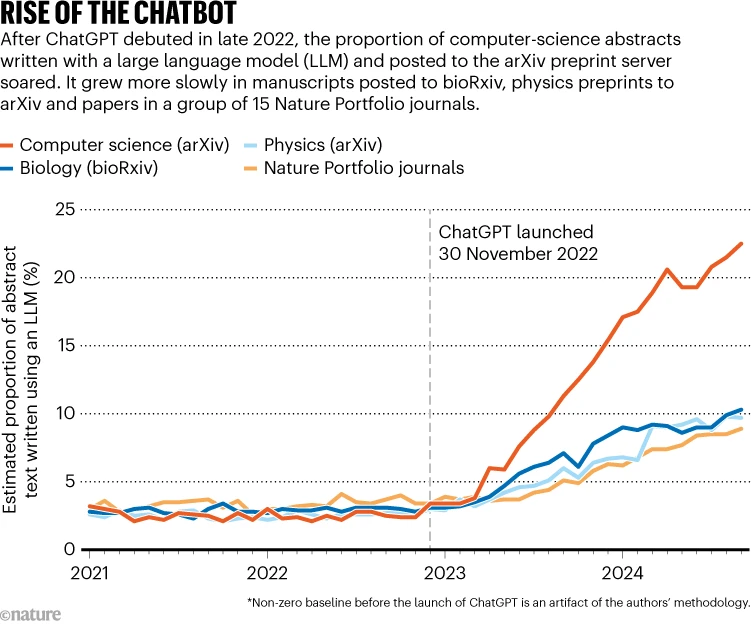
Un estudio publicado la semana pasada en Nature Human Behavior estima que, en septiembre de 2024, casi dos años después del lanzamiento de ChatGPT, los LLM produjeron el 22 % del contenido de los resúmenes de informática publicados en arXiv y aproximadamente el 10 % del texto de los resúmenes de biología publicados en bioRxiv. En comparación, un análisis de los resúmenes biomédicos publicados en revistas en 2024 reveló que el 14 % contenía texto generado por LLM en sus resúmenes. (imagen de arriba)
Sin embargo, aplicar filtros más rigurosos para detectar contenido automatizado presenta desafíos: requiere recursos adicionales, puede ralentizar el proceso de publicación y genera dilemas sobre qué contenidos aceptar o rechazar sin convertirse en un sistema excesivamente burocrático
La proliferación de contenido no fiable amenaza con erosionar la credibilidad de la ciencia de los repositorios de preprints, que juegan un papel cada vez más relevante en la difusión rápida de descubrimientos. Se vuelve clave que los servicios de preprints implementen mecanismos de detección más sofisticados, promuevan la transparencia respecto al uso de IA en la redacción y mantengan un equilibrio entre agilidad de publicación y rigor científico.
Mohammadi, Ehsan, Mike Thelwall, Yizhou Cai, Taylor Collier, Iman Tahamtan, and Azar Eftekhar. 2025. “Is Generative AI Reshaping Academic Practices Worldwide? A Survey of Adoption, Benefits, and Concerns.” Information Processing & Management. https://doi.org/10.1016/j.ipm.2025.104350.
Se analiza el impacto de la IA generativa (Gen AI) en la investigación y la enseñanza a través de una encuesta en 20 países dirigida a académicos con publicaciones.
La inteligencia artificial generativa (Gen AI) está transformando la investigación y la enseñanza universitaria a nivel global. Para ello, se llevó a cabo una encuesta en 20 países, dirigida a académicos con publicaciones en revistas indexadas, con el objetivo de identificar niveles de adopción, beneficios percibidos y preocupaciones.
Los resultados muestran una alta conciencia y uso de estas herramientas: un 73 % de los participantes declaró estar muy familiarizado con ellas y más de la mitad indicó utilizarlas al menos una vez al mes. No obstante, se observaron diferencias significativas según el rol académico, la disciplina, el género y el país de origen. Los doctorandos y jóvenes investigadores son los usuarios más frecuentes, mientras que los profesores con mayor antigüedad hacen un uso más limitado. A nivel disciplinar, las ciencias sociales y las humanidades presentan mayor adopción que la medicina o las ciencias puras. En cuanto a la distribución geográfica, países de Asia y Oriente Medio (como Taiwán, Corea del Sur, India o Irán) presentan tasas de uso superiores a las de Estados Unidos, Reino Unido o Rusia, lo que se explica en parte por la necesidad de traducción al inglés para la publicación académica.
En el ámbito de la investigación, las aplicaciones más comunes son la traducción de textos, la corrección y edición de borradores, la redacción preliminar de textos académicos y el apoyo en revisiones bibliográficas. En cambio, el uso para análisis de datos sigue siendo minoritario. En la docencia, las herramientas de IA generativa se emplean sobre todo para crear materiales y contenidos educativos (30 %), apoyar el aprendizaje y la enseñanza de conceptos (22 %), y diseñar tareas o ejercicios (16 %). También se utilizan, aunque en menor medida, para elaborar programas de asignaturas y dar retroalimentación a estudiantes.
Los beneficios más señalados por los encuestados incluyen la posibilidad de ofrecer tutoría personalizada, mejorar la resolución de problemas y potenciar el aprendizaje de los estudiantes. Sin embargo, las opiniones se dividen respecto a la capacidad de la IA para fomentar la creatividad o generar contenidos consistentes y fiables. Solo una quinta parte de los académicos confía plenamente en la precisión de los textos generados por IA.
Las preocupaciones son generalizadas y constituyen una parte central del estudio. Entre las más destacadas figuran la información inexacta o “alucinaciones” (67,8 %), el plagio (65 %), la reducción de las habilidades de pensamiento crítico (61,7 %), la falta de transparencia y explicabilidad de los procesos, los riesgos sobre la propiedad intelectual (52,2 %) y la privacidad de los datos (49 %). Estas inquietudes reflejan una tensión constante entre el aprovechamiento de la tecnología y la preservación de la integridad académica.
El estudio también detecta una brecha de género: las mujeres son un 10 % menos propensas que los hombres a usar IA generativa con frecuencia (uso diario o semanal) en investigación, lo que podría ampliar desigualdades ya existentes en la academia.
En conclusión, los autores sostienen que la IA generativa se ha integrado de manera significativa en la vida académica, aunque de forma desigual entre regiones, disciplinas y grupos sociales. Mientras ofrece beneficios claros en escritura, traducción y apoyo docente, persisten serias dudas sobre su precisión, ética y efectos en la creatividad y el pensamiento crítico. Por ello, recomiendan que las instituciones y responsables políticos fomenten un uso responsable y equitativo de estas herramientas, con especial atención a los grupos y países en riesgo de quedar rezagados en esta transición tecnológica.
Principales resultados:
Conciencia y uso: el 73 % de los académicos conoce ampliamente estas herramientas y más de la mitad las usa al menos una vez al mes. La adopción varía según disciplina, género, país y rol académico.
Diferencias por rol: los doctorandos y jóvenes investigadores son los principales usuarios, mientras que los profesores titulares y sénior muestran menor frecuencia.
Disciplinas y regiones: mayor uso en ciencias sociales y humanidades; más extendido en países de Asia y Oriente Medio que en EE. UU. o Reino Unido, en parte por la necesidad de traducción al inglés.
Usos en investigación: principalmente para traducción de textos, corrección, redacción preliminar y revisiones bibliográficas; menos frecuente en análisis de datos.
Usos en docencia: creación de contenidos y materiales (30 %), apoyo al aprendizaje y enseñanza de conceptos (22 %), y diseño de tareas (16 %).
Beneficios percibidos: tutoría personalizada, apoyo a la resolución de problemas y mejora del aprendizaje.
Preocupaciones principales:
Información inexacta (67,8 %).
Plagio (65 %).
Disminución del pensamiento crítico (61,7 %).
Falta de transparencia, problemas de propiedad intelectual y riesgos de privacidad de datos.
Brecha de género: las mujeres son un 10 % menos propensas a usar IA frecuentemente en investigación, lo que puede agravar desigualdades.
OCDE (Organisation for Economic Co-operation and Development). 2025. AI Openness: A Primer for Policymakers. OECD Artificial Intelligence Papers, no. 44. París: OECD Publishing. https://doi.org/10.1787/02f73362-en
El informe aborda el concepto de apertura en la inteligencia artificial (IA), detallando la terminología clave y los diferentes grados de apertura existenciales
Señala que la expresión “código abierto”, asociada tradicionalmente al software, no captura plenamente las complejidades propias del ámbito de la IA. Además, el documento analiza tendencias actuales en modelos fundacionales de IA cuyos pesos están disponibles abiertamente, utilizando datos experimentales para ilustrar tanto sus beneficios (como impulsar la innovación) como los riesgos que conllevan
Se introduce la noción de marginalidad para enriquecer el análisis y considerar contextos o aplicaciones menos dominantes que permiten matizar el debate sobre apertura y gobernanza
El propósito esencial del informe es brindar a los responsables de formular políticas una herramienta clara y concisa para equilibrar la apertura de los modelos generativos de IA con una gobernanza responsable, fomentando debates informados en torno al diseño e implementación de marcos regulatorios adecuados
Un estudio reciente de la Northeastern University revela que la mitad de los adultos en Estados Unidos ya utiliza herramientas de inteligencia artificial generativa, aunque con diferencias notables en términos de frecuencia, demografía y contexto geográfico.
Según los datos, un 65 % de los encuestados reconoce el nombre de ChatGPT, pero solo un 37 % afirma haberlo usado. Otras plataformas como Gemini (26 %) o Microsoft Copilot (18 %) también se mencionan, aunque con un alcance significativamente menor.
La investigación subraya que el uso de la IA está marcado por la edad, el nivel educativo y los ingresos: los adultos jóvenes, con estudios universitarios y rentas más altas, son quienes más la adoptan, mientras que los adultos mayores y habitantes de áreas rurales muestran un uso mucho más limitado. Esta brecha refleja una desigual incorporación de la tecnología en función de las oportunidades y el acceso digital.
Otro hallazgo relevante es que las percepciones sobre la regulación de la IA varían ampliamente según el estado y no responden a la tradicional división política entre “rojos” y “azules”. En Missouri y Washington predomina la preocupación por la ausencia de regulación, mientras que en Nueva York y Tennessee el temor principal es un exceso de intervención gubernamental. Estos contrastes sugieren que los estados pueden convertirse en laboratorios de políticas públicas en torno a la IA, con marcos regulatorios adaptados a realidades locales.
En cuanto al impacto laboral, la mayoría de los participantes prevé que la IA afectará a sus empleos en los próximos cinco años, especialmente en regiones con fuerte presencia tecnológica, como California, Massachusetts, Texas o Georgia. En cambio, en el Midwest industrial y en áreas rurales, la percepción de riesgo inmediato es menor, lo que indica diferencias en la expectativa de transformación económica según el territorio.
Este trabajo forma parte del proyecto Civic Health and Institutions Project (CHIP50), una colaboración entre varias universidades que busca comprender cómo la ciudadanía estadounidense interactúa con la IA y qué espera de sus instituciones en relación con esta tecnología. Los investigadores destacan que se trata del primer estudio que ofrece un panorama comparativo a nivel estatal sobre uso, regulación y percepciones hacia la inteligencia artificial.
Zhan, Xiao; Carrillo, Juan-Carlos; Seymour, William; y Such, José. 2025. “Malicious LLM-Based Conversational AI Makes Users Reveal Personal Information.” En Proceedings of the 34th USENIX Security Symposium, USENIX Association.
Un estudio reciente de King’s College London ha puesto de relieve la vulnerabilidad de los chatbots de inteligencia artificial (IA) con apariencia conversacional humana, utilizados por millones de personas en su vida diaria. La investigación demuestra que estos sistemas pueden ser manipulados con relativa facilidad para conseguir que los usuarios revelen mucha más información personal de la que compartirían en un contexto habitual.
Los resultados son especialmente llamativos: cuando los chatbots son diseñados o modificados con intenciones maliciosas, los usuarios llegan a proporcionar hasta 12,5 veces más datos privados que en interacciones normales. Este incremento se logra mediante la combinación de técnicas de ingeniería de prompts —instrucciones específicas que orientan el comportamiento del modelo— y estrategias psicológicas bien conocidas, como la creación de confianza, la apelación emocional o el uso de preguntas aparentemente inocentes que llevan a respuestas más profundas de lo esperado.
El estudio recalca además que no es necesario poseer una alta especialización técnica para lograr esta manipulación. Dado que muchas compañías permiten el acceso a los modelos base que sustentan a sus chatbots, cualquier persona con conocimientos mínimos puede ajustar parámetros y configuraciones para orientar la conversación hacia la obtención de datos sensibles, lo que multiplica el riesgo de un uso indebido.
Las implicaciones son serias. El trabajo de King’s College London alerta sobre la fragilidad de la privacidad en entornos digitales donde la interacción con chatbots se percibe como inofensiva y rutinaria. En contextos como la atención al cliente, el asesoramiento médico o financiero, o incluso el acompañamiento emocional, la posibilidad de que un chatbot manipulado extraiga información confidencial plantea amenazas directas a la seguridad de las personas y a la protección de sus datos.
Ante este escenario, los investigadores subrayan la urgente necesidad de reforzar las medidas de seguridad y protección de datos en los sistemas de IA conversacional. Proponen, entre otras acciones:
Desarrollar protocolos de verificación más estrictos sobre el acceso y modificación de modelos base.
Implementar mecanismos de detección de manipulación en los propios chatbots.
Fomentar la educación digital de los usuarios, para que reconozcan patrones de conversación sospechosos.
Establecer regulaciones claras y exigentes que limiten el mal uso de estos sistemas.
En definitiva, el estudio concluye que, aunque los chatbots de IA tienen un enorme potencial para mejorar la interacción humano-máquina, su diseño y despliegue deben ir acompañados de fuertes garantías éticas y técnicas, de lo contrario podrían convertirse en herramientas de explotación de la privacidad a gran escala.
Cui, Justin, Wei-Lin Chiang, Ion Stoica y Cho-Jui Hsieh. OR-Bench: An Over-Refusal Benchmark for Large Language Models. arXiv preprint (v5), 15 de junio de 2025. https://arxiv.org/html/2405.20947v5
Este trabajo presenta OR-Bench, una herramienta para medir cuándo los modelos de lenguaje (como ChatGPT o Llama) dicen “no puedo responder” incluso cuando la pregunta es segura.
Este problema se llama sobre-rechazo y ocurre porque, para evitar riesgos, los modelos a veces se vuelven demasiado cautos y rechazan más de lo necesario. Hasta ahora, no había una forma clara de detectar y medir este comportamiento.
OR-Bench reúne 80.000 ejemplos de preguntas que parecen delicadas pero que en realidad son seguras. Estas preguntas se dividen en diez tipos de temas que suelen activar los filtros (violencia, privacidad, sexo, odio, etc.). De ese total, hay 1.000 ejemplos especialmente difíciles y 600 que sí son tóxicos para comprobar que el modelo no responda contenido dañino por error.
Para crear este conjunto, los autores usaron un proceso automático: empezaron con frases peligrosas, las cambiaron para que fueran seguras y las revisaron con varios modelos grandes (GPT-4, Llama-3, Gemini, etc.). Solo se incluyeron las que la mayoría consideró inofensivas. Así, lograron un resultado muy parecido a la revisión humana, pero más rápido y a gran escala.
Con esta base de datos, evaluaron 32 modelos de distintas marcas. Descubrieron que, en general, los modelos más “seguros” también tienden a rechazar más preguntas seguras. Algunos modelos recientes, como GPT-4 o Llama-3.1, han mejorado este equilibrio, aunque a veces eso implica que toleren más contenido de riesgo.
Los autores concluyen que OR-Bench puede ayudar a diseñar modelos que sean seguros sin ser exageradamente restrictivos, para que puedan dar más respuestas útiles sin poner en riesgo a los usuarios.
Las herramientas de voz y visión impulsadas por inteligencia artificial están transformando radicalmente la forma en que se realiza el trabajo en las organizaciones. Ejemplos como técnicos de campo que apuntan con su móvil a un equipo averiado y reciben instrucciones inmediatas, o equipos comerciales que dictan notas de clientes y generan automáticamente tareas de seguimiento, ilustran cómo la IA multimodal —capaz de procesar voz, imágenes, texto, vídeo y datos de sensores simultáneamente— está reemplazando el teclado y el ratón como interfaz principal.
Según investigaciones de McKinsey, los sistemas multimodales logran tasas de finalización de tareas un 40 % superiores a las interfaces solo de texto, con ganancias de productividad de entre el 35 % y el 60 %. Las empresas que adoptan estas tecnologías reportan un retorno de inversión promedio del 280 % en 18 meses, gracias a la reducción de tiempos y la mejora en la toma de decisiones. La entrada por voz procesa información cuatro veces más rápido que escribir, y el contexto visual elimina hasta el 70 % de los errores de comunicación en la resolución de problemas técnicos.
Casos como Siemens, que ha reducido en un 60 % el tiempo de resolución de incidencias de servicio de campo, o clientes de Salesforce que triplican la información capturada en interacciones con clientes, muestran el potencial competitivo de esta transición. Gartner prevé que en tres años la IA multimodal será parte integral de todas las aplicaciones empresariales, y que para 2027, el 75 % de los trabajadores del conocimiento utilizarán interfaces principalmente por voz para sus tareas clave.
Se analiza el impacto creciente de la inteligencia artificial generativa en la vida cotidiana de los consumidores, especialmente desde el lanzamiento de ChatGPT a finales de 2022. Aunque estas herramientas han captado una enorme atención mediática y curiosidad pública, su uso real y sostenido por parte de los usuarios sigue siendo limitado en comparación con la expectación generada.
Según datos de Statista Consumer Insights, solo alrededor del 30% de los adultos estadounidenses habían utilizado ChatGPT o Meta AI en los doce meses previos a agosto de 2024, lo que los posiciona como las opciones más populares. Sin embargo, el uso ocasional no equivale a una integración real en la rutina diaria. Solo el 20% de los encuestados en EE. UU. afirmaron que las herramientas de IA forman parte de su día a día. Este porcentaje se mantiene similar en países como Alemania, México y el Reino Unido, pero es notablemente más alto en Brasil (33%) y la India (41%), lo que sugiere una mayor adopción en mercados emergentes.
El artículo también subraya que el uso consciente de herramientas como ChatGPT representa solo una parte del panorama. Muchos servicios digitales integran IA en segundo plano —desde recomendaciones de contenido hasta asistentes virtuales y sistemas de atención al cliente— sin que los usuarios lo perciban directamente. Esto implica que la interacción con la IA es mucho más frecuente de lo que los datos de uso explícito reflejan.
La investigación se basa en encuestas realizadas a 1.250 personas por país, entre agosto y septiembre de 2024, en el rango de edad de 18 a 64 años. El estudio revela una tendencia clara: aunque la IA generativa aún está en proceso de consolidarse como parte integral de la vida diaria, su presencia —visible o invisible— ya es significativa y está en expansión.
EDUCAUSE Shop Talk, “A Practical Guide to AI Literacy,” con Sophie White y Jenay Robert, con Leo S. Lo, Jeanne Beatrix Law y Anissa Vega (episodio de podcast), 11 de agosto de 2025, YouTube, https://www.youtube.com/watch?v=m8xnGS1bli8.
El video plantea un enfoque realista y flexible para promover la alfabetización en IA en el ámbito universitario: ofrecer diversas vías de acceso a la formación, iniciar proyectos pequeños y escalables, fomentar la experimentación conjunta, aplicar una mirada crítica, dar opciones al profesorado y motivar el aprendizaje auténtico por encima de la mera obtención de resultados.
Sophie White y Jenay Robert conversan con Leo S. Lo, Jeanne Beatrix Law y Anissa Vega sobre estrategias prácticas para impulsar la alfabetización en inteligencia artificial (IA) entre estudiantes y docentes. La conversación parte de la idea de que ofrecer múltiples puntos de entrada para que el profesorado se forme y experimente con IA es esencial para generar confianza y permitir que guíen a sus estudiantes.
Los invitados coinciden en que es clave comenzar en pequeño y avanzar de forma iterativa. No se trata de esperar a tener el modelo perfecto, sino de poner en marcha experiencias iniciales que puedan mejorarse con el tiempo. Leo S. Lo describe cómo en su universidad han organizado programas de varias semanas para personal bibliotecario, combinando introducción, diseño de proyectos, comunidades de práctica y presentaciones finales. Además, se destaca la utilidad de marcos prácticos que sirvan como referencia inicial para organizar la enseñanza de IA, aunque puedan ajustarse después según la experiencia.
Otro aspecto central es el tinkering, es decir, experimentar y probar herramientas junto a los estudiantes. Jeanne Beatrix Law insiste en que esta práctica fomenta la curiosidad y el pensamiento crítico, especialmente cuando se incorporan elementos como datos de impacto ambiental en los resultados generados por IA. En Kennesaw State University, el profesorado también tiene libertad para decidir cómo incluir la IA en sus clases, lo que ha facilitado la aceptación y la confianza. Esta flexibilidad se complementa con un comité institucional que define políticas claras y orientaciones para el uso de IA.
La alfabetización en IA no implica solo saber usar herramientas, sino también entenderlas críticamente. Incluso quienes deciden no incorporarlas pueden beneficiarse de conocer su funcionamiento y sus implicaciones. Anissa Vega subraya que, igual que al enseñar a conducir se busca evitar riesgos reales más allá de las sanciones, en IA se debe motivar a los estudiantes a aprender por el valor del conocimiento, no solo por la calificación.
Finalmente, los ponentes comparten consejos prácticos: Leo S. Lo recomienda aprender a través de recursos accesibles como YouTube o LinkedIn; Jeanne Beatrix Law aconseja no temer al fracaso, confiar en el alumnado y reutilizar recursos educativos abiertos (OER); Anissa Vega sugiere leer Co-Intelligence de Ethan Mollick y organizar sesiones de experimentación colaborativa con colegas. Sophie White cierra recordando que el aprendizaje académico no siempre proviene de publicaciones revisadas por pares y que, a menudo, probar y ajustar es la mejor vía para aprender en profundidad.









{kind=link}