Van Buskirk, Ian, Marilena Hohmann, Ekaterina Landgren, Johan Ugander, Aaron Clauset y Daniel B. Larremore. Consensus and Fragmentation in Academic Publication Preferences. arXiv:2603.00807v1 [cs.DL], 28 de febrero de 2026
Este trabajo analiza cómo los investigadores toman decisiones sobre dónde publicar sus trabajos científicos y hasta qué punto existen patrones de consenso o, por el contrario, fragmentación dentro de las comunidades académicas.
Los autores parten de la premisa de que la elección de la revista o del canal de publicación no es un proceso puramente individual, sino que refleja dinámicas colectivas dentro de cada disciplina científica. Estas decisiones están influenciadas por múltiples factores —prestigio de las revistas, redes académicas, incentivos institucionales o visibilidad— y, en conjunto, configuran un sistema complejo de preferencias compartidas que puede ser estudiado mediante herramientas de análisis de redes y ciencia de datos. El objetivo central del artículo es identificar si las comunidades científicas muestran patrones claros de acuerdo sobre qué revistas son más relevantes o si, por el contrario, el sistema editorial está caracterizado por una pluralidad de preferencias que fragmenta el espacio de publicación.
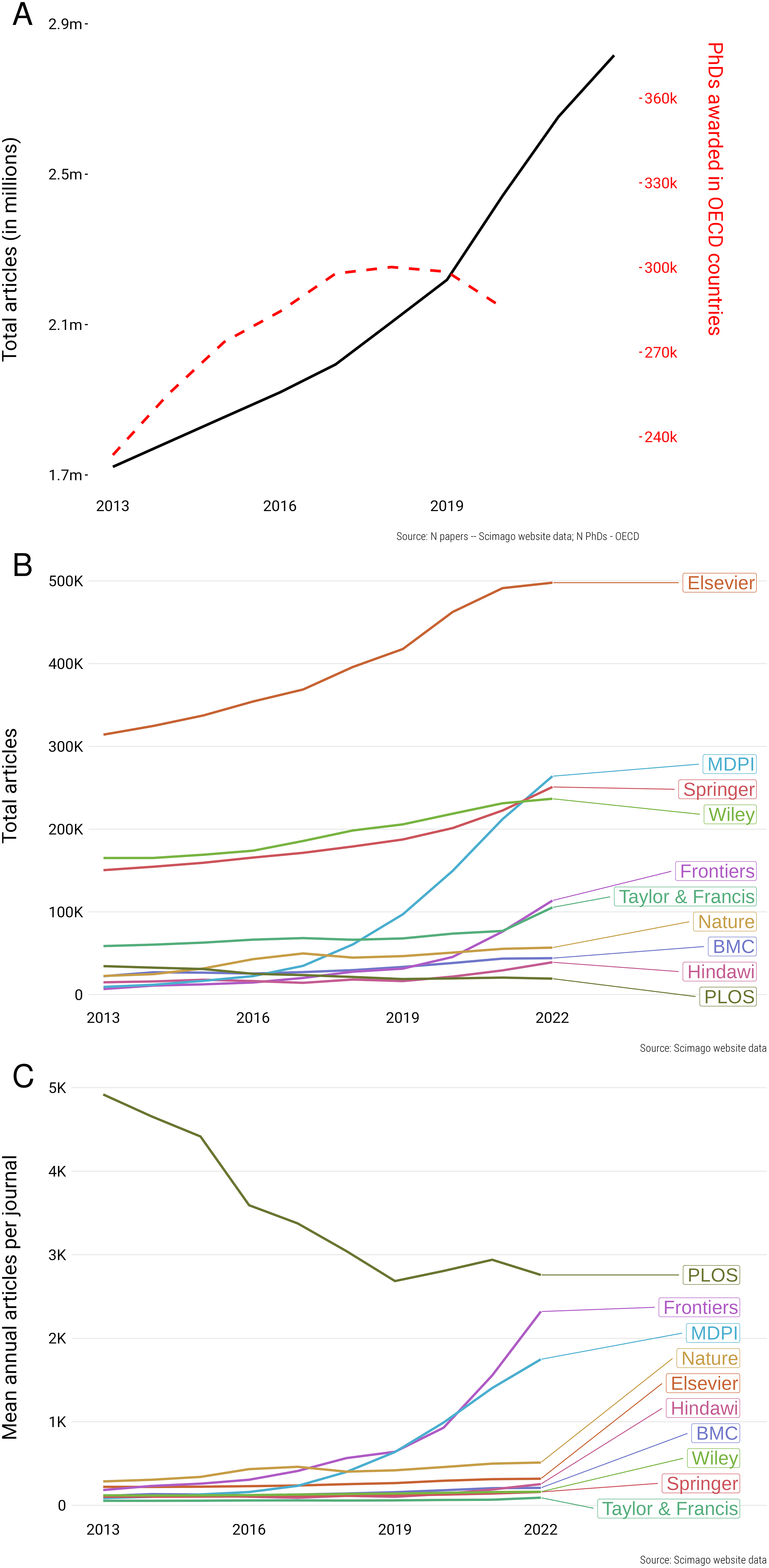
Para abordar esta cuestión, los autores desarrollan un enfoque cuantitativo que combina datos de publicaciones académicas con modelos de redes y análisis estadístico. A partir de estos datos reconstruyen un mapa de las preferencias de publicación de los investigadores, observando cómo los científicos de distintas áreas tienden a concentrar sus envíos en determinados grupos de revistas. Este enfoque permite detectar estructuras emergentes en el sistema editorial: por un lado, núcleos de consenso donde muchos investigadores convergen en un pequeño conjunto de revistas consideradas centrales; y por otro, regiones de fragmentación en las que las preferencias se dispersan entre múltiples opciones. El análisis muestra que estas estructuras no son uniformes en todas las disciplinas: algunas comunidades presentan jerarquías editoriales muy claras, mientras que otras exhiben una distribución más diversificada de canales de publicación.
Uno de los hallazgos más relevantes del estudio es que el sistema de publicación científica funciona como una red de coordinación social. Las decisiones individuales de los investigadores están influidas por lo que hacen sus pares, lo que genera dinámicas colectivas de imitación, reputación y señalización. Publicar en determinadas revistas actúa como una señal de calidad y legitimidad dentro de la comunidad científica, lo que refuerza la concentración de envíos en ciertos títulos. Sin embargo, esta dinámica también puede producir fragmentación cuando diferentes subcomunidades científicas desarrollan sus propios circuitos editoriales o cuando emergen nuevas revistas y plataformas que compiten con las tradicionales. De este modo, el sistema editorial no es completamente centralizado ni completamente disperso, sino que presenta una estructura híbrida caracterizada por clusters o comunidades de publicación.
El artículo también examina las implicaciones de estos patrones para la evaluación científica y la difusión del conocimiento. Cuando existe un fuerte consenso en torno a unas pocas revistas, estas adquieren un poder simbólico considerable, lo que puede reforzar desigualdades en la visibilidad de la investigación y consolidar jerarquías académicas. Por el contrario, una mayor fragmentación puede favorecer la diversidad de enfoques y la aparición de nuevos espacios de comunicación científica, aunque también puede dificultar la identificación de estándares comunes de calidad. En este sentido, el estudio sugiere que comprender la estructura de preferencias de publicación es fundamental para analizar fenómenos como la concentración editorial, la influencia de los rankings de revistas o el impacto de políticas de ciencia abierta.
Finalmente, los autores destacan que su enfoque ofrece una nueva perspectiva cuantitativa para estudiar el ecosistema de la publicación científica, integrando métodos de análisis de redes, ciencia computacional y sociología de la ciencia. Este tipo de análisis permite comprender mejor cómo se forman los consensos en torno a determinadas revistas, cómo surgen nichos editoriales especializados y cómo evolucionan las comunidades científicas a lo largo del tiempo. En última instancia, el estudio aporta evidencia empírica sobre las dinámicas colectivas que subyacen a la comunicación académica y abre nuevas líneas de investigación sobre la gobernanza del sistema de publicación científica, especialmente en un contexto marcado por la expansión del acceso abierto, la proliferación de nuevas revistas y los cambios en los mecanismos de evaluación de la investigación.