Hines, Kristi. «Should You Trust An AI Detector?» Search Engine Journal, 18 de julio de 2023. https://www.searchenginejournal.com/should-you-trust-an-ai-detector/491949/.
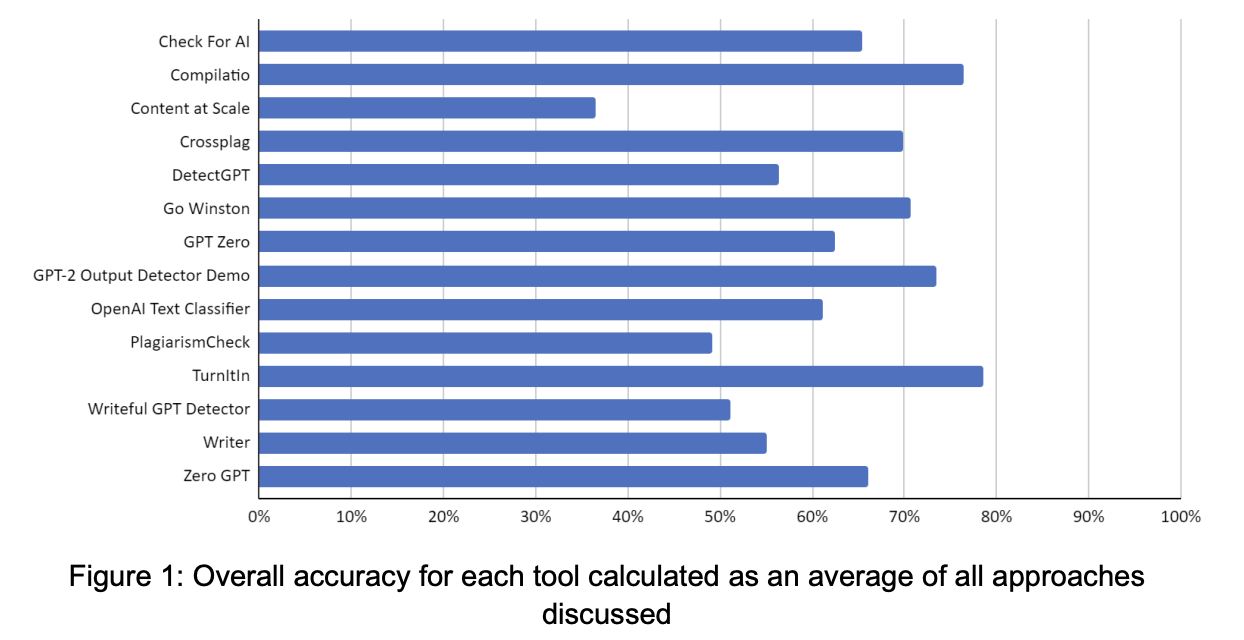
La IA generativa está ganando terreno y se está utilizando cada vez más para crear diversos tipos de contenidos, como texto, imágenes, música y más. Esto ha llevado a una creciente preocupación sobre la fiabilidad de los detectores de IA para discernir entre contenidos generados por humanos y aquellos creados por algoritmos de inteligencia artificial. Turnitin resultó ser la herramienta más precisa en todos los enfoques, seguida de Compilatio y GPT-2 Output Detector.
Detectar y verificar si un contenido fue generado por una IA o por un ser humano es un desafío en constante evolución. A medida que la tecnología de IA avanza, también lo hacen las técnicas para ocultar la autoría de los contenidos generados por algoritmos. Esto puede plantear problemas en términos de veracidad, credibilidad y confiabilidad de la información que se comparte en línea. Para abordar esta preocupación, se han llevado a cabo diversos estudios para evaluar la eficacia de las herramientas de detección de IA en esta tarea. Estos estudios buscan mejorar y perfeccionar los algoritmos de detección y establecer métricas para evaluar su precisión.
Algunos enfoques utilizan marcadores específicos que pueden identificar ciertas características o patrones que son más comunes en contenidos generados por IA. Otros enfoques buscan analizar el estilo y la estructura de los textos o imágenes para identificar indicios de automatización.
¿Son parciales los detectores de IA? Los investigadores encontraron que los detectores de contenidos de IA, especialmente aquellos diseñados para identificar contenidos generados por modelos de lenguaje como GPT, pueden presentar un sesgo significativo en contra de los escritores no nativos de inglés. El estudio descubrió que estos detectores, diseñados para diferenciar entre contenidos generados por IA y contenidos generados por humanos, clasifican erróneamente muestras de escritura en inglés no nativo como generadas por IA, mientras que identifican con precisión muestras de escritura en inglés nativo.
Utilizando muestras de escritura de escritores nativos y no nativos, los investigadores descubrieron que los detectores clasificaban erróneamente más de la mitad de estas últimas muestras como generadas por IA. Los resultados sugieren que los detectores de GPT pueden penalizar involuntariamente a los escritores con expresiones lingüísticas limitadas, lo que subraya la necesidad de prestar más atención a la equidad y solidez de estas herramientas. Esto podría tener implicaciones significativas, sobre todo en contextos evaluativos o educativos, donde los hablantes no nativos de inglés podrían verse inadvertidamente penalizados.
Los investigadores también destacan la necesidad de seguir investigando para hacer frente a estos sesgos y perfeccionar los métodos de detección actuales para garantizar un panorama digital más equitativo y seguro para todos los usuarios.
En otro estudio sobre texto generado por IA, los investigadores documentan la optimización de ejemplos en contexto basada en la sustitución (SICO), que permite a los grandes modelos lingüísticos (LLM) como ChatGPT eludir la detección de los detectores de texto generado por IA. En el estudio se utilizaron tres tareas para simular situaciones reales de uso de los LLM en las que es crucial detectar el texto generado por IA: redacciones académicas, preguntas y respuestas abiertas y reseñas comerciales.
También se probó SICO frente a seis detectores representativos -incluidos modelos basados en la formación, métodos estadísticos y API- que superaron sistemáticamente a otros métodos en todos los detectores y conjuntos de datos.
Los investigadores comprobaron que SICO era eficaz en todos los escenarios de uso probados. En muchos casos, el texto generado por SICO era indistinguible del texto escrito por humanos. Sin embargo, también pusieron de relieve el posible mal uso de esta tecnología. Dado que SICO puede ayudar a que el texto generado por IA evada la detección, los actores malintencionados también podrían utilizarla para crear información engañosa o falsa que parezca escrita por humanos.
Ambos estudios señalan el ritmo al que el desarrollo de la IA generativa supera al de los detectores de texto de IA, y el segundo hace hincapié en la necesidad de una tecnología de detección más sofisticada.
Los investigadores de un tercer estudio recopilaron estudios anteriores sobre la fiabilidad de los detectores de IA, seguidos de sus datos, y publicaron varias conclusiones sobre estas herramientas.
- Aydin & Karaarslan (2022) revelaron que iThenticate, una popular herramienta de detección de plagio, encontró altas tasas de coincidencia con el texto parafraseado por ChatGPT.
- Wang et al. (2023) descubrieron que es más difícil detectar código generado por IA que contenido en lenguaje natural. Además, algunas herramientas mostraron sesgos, inclinándose por identificar el texto como generado por IA o escrito por humanos.
- Pegoraro et al. (2023) descubrieron que detectar texto generado por ChatGPT es muy difícil, y que la herramienta más eficaz lograba una tasa de éxito inferior al 50%.
- Van Oijen (2023) reveló que la precisión global de las herramientas en la detección de texto generado por IA era sólo de alrededor del 28%, y que la mejor herramienta lograba sólo un 50% de precisión. Por el contrario, estas herramientas eran más eficaces (alrededor del 83% de precisión) en la detección de contenido escrito por humanos.
- Anderson et al. (2023) observaron que la paráfrasis reducía notablemente la eficacia del detector de salida GPT-2.
Utilizando 14 herramientas de detección de texto generadas por IA, los investigadores crearon varias docenas de casos de prueba en diferentes categorías, entre ellas:
Texto escrito por humanos.
Texto traducido.
Texto generado por IA.
Texto generado por IA con ediciones humanas.
Texto generado por IA con parafraseo de IA.
La mayoría de las herramientas probadas mostraron un sesgo hacia la clasificación precisa del texto escrito por humanos, en comparación con el texto generado o modificado por IA. El estudio destacó también el riesgo de falsas acusaciones y casos no detectados. Los falsos positivos fueron mínimos en la mayoría de las herramientas, excepto en GPT Zero, que presentó una tasa elevada.
Los casos no detectados eran preocupantes, sobre todo en el caso de los textos generados por IA que habían sido editados por personas o parafraseados por máquinas. La mayoría de las herramientas tenían dificultades para detectar este tipo de contenidos, lo que supone una amenaza potencial para la integridad académica y la imparcialidad entre los estudiantes. Turnitin resultó ser la herramienta más precisa en todos los enfoques, seguida de Compilatio y GPT-2 Output Detector.
Los investigadores sugieren que abordar estas limitaciones será crucial para implantar eficazmente herramientas de detección de texto generadas por IA en entornos educativos, garantizando la detección precisa de conductas indebidas y minimizando al mismo tiempo las acusaciones falsas y los casos no detectados.
¿Deberíamos confiar en las herramientas de detección de IA basándose en los resultados de estos estudios? Aunque los detectores de IA han demostrado cierta precisión a la hora de detectar texto generado por IA, también han mostrado sesgos, problemas de usabilidad y vulnerabilidades ante las técnicas de elusión Se necesitan mejoras para corregir los sesgos, aumentar la robustez y garantizar una detección precisa en diferentes contextos. La investigación y el desarrollo continuados son cruciales para fomentar la confianza en los detectores de IA y crear un panorama digital más equitativo y seguro.








