A Framework for AI Literacy. (2024.). EDUCAUSE Review. Recuperado 3 de junio de 2024, de https://er.educause.edu/articles/2024/6/a-framework-for-ai-literacy
Equipos académicos y tecnológicos en el Barnard College desarrollaron un marco de alfabetización en inteligencia artificial (IA) para proporcionar una base conceptual para la educación en IA y los esfuerzos de programación en contextos institucionales de educación superior.
El Barnard College es una universidad de artes liberales para mujeres y una institución distinguida dentro del amplio ecosistema de la Universidad de Columbia en la ciudad de Nueva York. Varios equipos campus, ágiles pero pequeños, están trabajando para avanzar en las conversaciones sobre temas de inteligencia artificial generativa (IA). Como miembros de los Servicios de Tecnología Académica y Multimedia Instruccional (IMATS) y el Centro de Pedagogía Comprometida (CEP), han desarrollado programas educativos sobre varios temas de IA para la comunidad de Barnard. Durante el último año, han realizado sesiones de laboratorio abiertas para probar diferentes herramientas de IA basadas en texto e imagen, han recibido oradores invitados sobre derechos de autor y uso justo, han facilitado talleres sobre declaraciones de programas de estudios generativos de IA para profesores, han realizado talleres de instrucción (GenAI 101) y han liderado sesiones de educación individualizadas para departamentos de profesores. Este proceso ha sido continuo e iterativo a medida que las herramientas cambian y las necesidades de los miembros de la comunidad del campus evolucionan. También han implementado encuestas internas, evaluaciones y mecanismos de retroalimentación para comprender mejor las necesidades del profesorado y el personal relacionadas con el uso de herramientas de IA generativas.
La necesidad de la Alfabetización en IA El Barnard College ha establecido varios grupos de trabajo y desarrollado tareas internas para discutir preguntas más grandes sobre el impacto de la IA en la institución. Actualmente, no hay un mandato o recomendación para que los profesores adopten o prohíban la IA en sus aulas. Sin embargo, se anima a los profesores a definir y discutir sus expectativas sobre el uso de la IA en sus tareas. (El CEP ha creado muchos recursos para profesores, incluidos árboles de decisiones para guiar la planificación de los profesores, declaraciones de programas de estudios de muestra, tareas que integran IA generativa y otros materiales, para ayudar a guiar la toma de decisiones sobre si y cómo incorporar IA generativa en el aula). Niveles más altos de alfabetización en IA pueden ayudar a los profesores a tomar decisiones informadas sobre el uso de IA en sus cursos y tareas. En cuanto a los servicios de tecnología académica, el equipo de IMATS ha decidido no implementar ni seguir tecnología de vigilancia de IA para monitorear la integridad académica debido al sesgo y la fiabilidad cuestionable de estas herramientas. Sin embargo, el panorama y las políticas correlativas podrían cambiar a medida que evolucionen las tecnologías de IA generativas.
Un Marco para la Alfabetización en IA
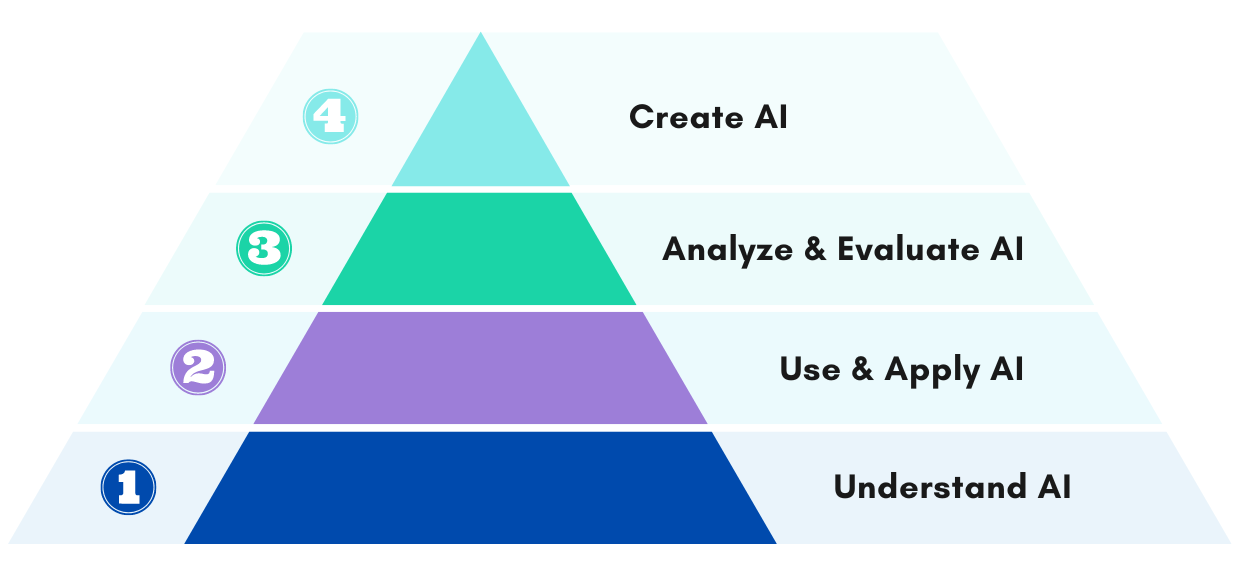
Un marco para la alfabetización en IA fue desarrollado por los miembros de IMATS y CEP para guiar el desarrollo y la expansión de la alfabetización en IA entre el profesorado, los estudiantes y el personal del Barnard College. El marco proporciona una estructura para aprender a utilizar la IA, incluyendo explicaciones de conceptos clave y preguntas a considerar al usarla. La estructura piramidal de cuatro partes fue adaptada del trabajo realizado por investigadores en la Universidad de Hong Kong y la Universidad de Ciencia y Tecnología de Hong Kong. El marco tiene como objetivo adaptarse al nivel actual de alfabetización en IA de las personas y se divide en cuatro niveles:
- Comprender la IA
- Usar y Aplicar la IA
- Analizar y Evaluar la IA
- Crear IA
Es importante tener en cuenta que la IA es un campo amplio con muchos tipos diferentes, y aunque este marco se centra en la IA generativa, puede aplicarse a otras formas de tecnología. Además, no es necesario dominar todos los conceptos de un nivel antes de pasar al siguiente. Por ejemplo, comprender cómo se entrenan los modelos de IA generativa puede ser útil para analizar su impacto en el mercado laboral, pero no es necesario entender todas las complejidades de las redes neuronales para hacerlo.
Nivel 1: Comprender la IA
La base de la pirámide abarca términos y conceptos básicos de IA. La mayor parte de la programación e instrucción en Barnard se ha centrado en los niveles uno y dos (comprender, usar y aplicar IA), ya que esta es una tecnología en rápida evolución y todavía hay mucha falta de familiaridad con ella.
Competencias Clave
- Ser capaz de definir los términos «inteligencia artificial», «aprendizaje automático», «modelo de lenguaje grande» y «red neuronal»
- Reconocer los beneficios y limitaciones de las herramientas de IA
- Identificar y explicar las diferencias entre varios tipos de IA, definidos por sus capacidades y mecanismos computacionales
Conceptos Clave
- Inteligencia artificial, aprendizaje automático, redes neuronales artificiales, modelos de lenguaje grande y modelos de difusión
- Inteligencia artificial estrecha, inteligencia artificial general, inteligencia artificial super, máquinas reactivas, memoria limitada, teoría de la mente y autoconciencia
- Herramientas de IA, como ChatGPT (ver figura 2), Siri, Alexa, Deep Blue y texto predictivo
- Marcos técnicos relacionados con la IA (modelos de código abierto versus modelos cerrados, APIs y cómo se usan)
Preguntas de Reflexión
- ¿Qué tipo de IA es esta?
- ¿Qué tecnologías utiliza esta herramienta de IA?
- ¿Para qué fue diseñada esta herramienta? ¿Qué tipo de información acepta como entrada y devuelve como respuesta (texto, video, audio, etc.)?
- ¿Para qué podría ser particularmente útil esta herramienta?
- ¿Para qué no sería útil?
Nivel 2: Usar y Aplicar la IA
El segundo nivel de fluidez en IA indica que los usuarios pueden utilizar herramientas como ChatGPT para lograr sus objetivos; estos usuarios están familiarizados con las técnicas de ingeniería de solicitudes y saben cómo refinar, iterar y editar colaborativamente con herramientas de IA generativa. La programación diseñada para desarrollar la fluidez en el nivel dos en el Barnard College incluye laboratorios prácticos y la ingeniería colaborativa de solicitudes en tiempo real.
Competencias Clave
- Utilizar con éxito herramientas de IA generativa para obtener respuestas deseadas
- Experimentar con técnicas de solicitud e iterar en el lenguaje de la solicitud para mejorar la salida generada por IA
- Revisar el contenido generado por IA con miras a posibles «alucinaciones», razonamientos incorrectos y sesgos
Conceptos Clave
- Ingeniería de solicitudes, ventanas de contexto, alucinaciones, sesgos, solicitud sin disparador y solicitud con disparador
- Técnicas de solicitud para IA generativa basada en texto, como agregar especificidad, usar contexto y detalles, y pedir al modelo que considere pros y contras o evalúe posiciones alternativas
- Consideraciones de privacidad, confidencialidad y derechos de autor para la información alimentada en las herramientas de solicitud
Preguntas de Reflexión
- ¿Por qué una solicitud generó una respuesta particular?
- ¿Cómo se podría ajustar la solicitud para obtener una respuesta diferente?
- ¿Qué estrategias se pueden utilizar para reducir el sesgo y las alucinaciones?
- ¿Cómo se puede verificar el sesgo y las alucinaciones en la salida de la IA?
Nivel 3: Analizar y Evaluar la IA
Analizar y evaluar la IA implica una comprensión meta más compleja de la IA generativa. En este nivel, los usuarios deben poder reflexionar críticamente sobre resultados, sesgos, ética y otros temas más allá de la ventana de solicitud. Un ejemplo de programación en este nivel es un evento que contó con la participación de un experto que discutió las actuales preguntas sobre derechos de autor y propiedad intelectual en torno a la IA y los impactos ambientales y climáticos que la IA generativa podría tener. Por supuesto, uno puede participar en conversaciones sobre estas preguntas e ideas sin conocer todas las definiciones de IA. Sin embargo, la familiaridad con los niveles anteriores en la pirámide informa la comprensión básica y el vocabulario del individuo, ayudando a comprender cómo se intersecta la IA con otros campos.
Competencias Clave
Examinar la IA en un contexto más amplio, incorporando conocimientos de la disciplina o intereses de uno Critique herramientas de IA y ofrezca argumentos a favor o en contra de su creación, uso y aplicación Analizar consideraciones éticas en el desarrollo e implementación de IA
Conceptos Clave
Perspectivas críticas sobre la IA (Los siguientes ejemplos no pretenden ser exhaustivos.) Sostenibilidad ambiental Trabajo Privacidad Derechos de autor Sesgo de raza, género, clase y otros Desinformación
Preguntas de Reflexión
¿Qué otras perspectivas o marcos podrían ser útiles para evaluar las implicaciones del uso de herramientas de IA generativa? ¿De dónde podrían venir los sesgos en la IA? ¿De qué manera el uso de herramientas de IA generativa se alinea o diverge de tus valores personales?
Nivel 4: Crear IA
En este nivel de fluidez en IA, los usuarios pueden interactuar con la IA a nivel de creador. Por ejemplo, los usuarios pueden construir sobre APIs abiertas para crear su propio LLM o aprovechar la IA para desarrollar nuevos sistemas. Actualmente, Barnard ofrece menos programación en el nivel cuatro que en los otros tres niveles, pero ha habido talleres en el Centro de Ciencias Computacionales que proporcionan instrucción técnica relacionada con la construcción de modelos de IA y aprendizaje automático. Es importante involucrar a las personas en todos los niveles de fluidez en IA.
Competencias Clave
Sintetizar el aprendizaje para conceptualizar o crear nuevas ideas, tecnologías o estructuras relacionadas con la IA. Alcanzar este nivel de alfabetización podría incluir lo siguiente: Concebir nuevos usos para la IA Construir software que aproveche la tecnología de IA Proponer teorías sobre la IA
Preguntas de Reflexión
¿Qué es único y humano acerca de tus ideas, tecnologías o estructuras? ¿Cómo podrían diferir de lo que podría crear una IA? ¿Qué características específicas de IA otorgan ventajas únicas a las ideas, tecnologías o estructuras?
Conclusion y Próximos Pasos
Si bien este marco de alfabetización en IA no es exhaustivo, proporciona una base conceptual para los esfuerzos de educación y programación en IA, especialmente en contextos institucionales de educación superior. La intención es mantener la neutralidad con respecto al uso de IA, reconociendo que la alfabetización tecnológica puede llevar a la decisión de no usarla. El impacto de la IA en la educación superior probablemente será significativo, afectando las admisiones, la investigación y los planes de estudio. La educación y la alfabetización básica son los primeros pasos para que una comunidad se involucre productivamente con esta tecnología en rápida evolución.
Existen muchos posibles próximos pasos que el Barnard College podría tomar relacionados con la IA generativa, pero específicamente en relación con el marco de alfabetización en IA, los equipos de IMATS y CEP pueden explorar «ascender» en la pirámide de alfabetización en la programación, los recursos y los eventos a medida que crece la conciencia y la alfabetización básica. Actualmente, la mayoría de nuestras ofertas se encuentran en los niveles uno y dos, pero esperamos cambiar nuestro enfoque de programación a los niveles dos y tres. Una encuesta reciente reveló que un número significativo de profesores y estudiantes aún nunca han usado IA generativa y tienen percepciones negativas sobre estas herramientas, por lo que nuestros equipos también están explorando formas de facilitar mejor el compromiso práctico y crítico.
Otro objetivo de la iniciativa de alfabetización en IA es resaltar el aspecto humano de estas tecnologías. Si bien el uso de IA generativa puede sentirse casi como alquimia, convirtiendo el texto simple en oro a través de tecnología de caja negra, está muy construido sobre el conocimiento humano, que tiene sus propios sesgos e inequidades. Usar una lente crítica al interactuar con la IA generativa puede ayudar a los usuarios a identificar sesgos existentes y evitar que los usuarios los agraven.