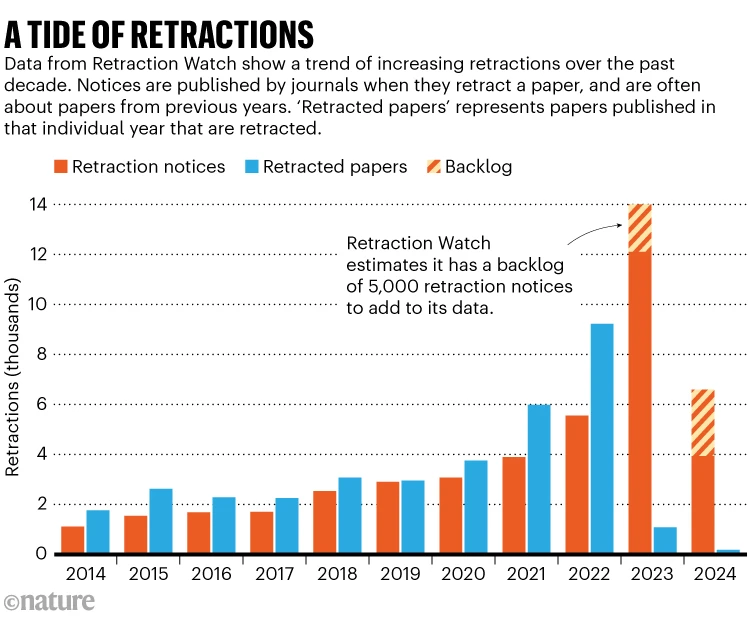
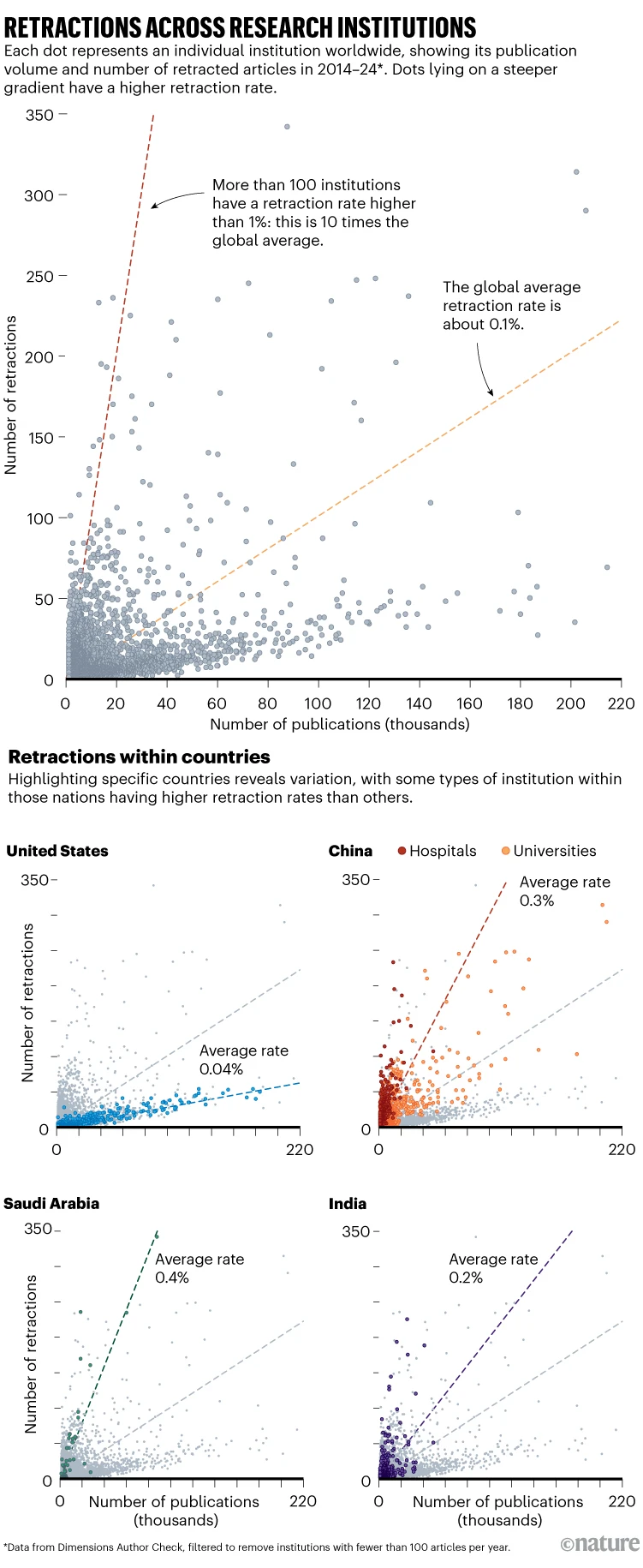
Staiman, Avi. Why Authors Aren’t Disclosing AI Use and What Publishers Should (Not) Do About It. The Scholarly Kitchen, 27 de enero de 2026.
- El problema central
En esta serie de dos artículos, Avi Staiman analiza un fenómeno creciente en las publicaciones académicas: aunque muchos investigadores utilizan herramientas de inteligencia artificial (IA) en diversas fases de su trabajo —desde la búsqueda de literatura, redacción de textos o apoyo en el análisis de datos—, muy pocos lo revelan explícitamente en sus manuscritos. Las políticas de muchas revistas y editoriales requieren este tipo de declaraciones, pero la práctica demuestra que casi nadie cumple con ellas y la razón no es simplemente desobediencia, sino un problema de incentivos, claridad y cultura editorial.
Los editores esperaban que al exigir a los autores que explicaran su uso de IA se fomentara una mayor transparencia, permitiendo que revisores y equipos editoriales evaluaran si ese uso era apropiado y cómo influía en la investigación. Sin embargo, esto no ha ocurrido en la práctica: con encuestas que muestran que más de la mitad de los investigadores (por ejemplo, un 62 %) usan IA en algún punto de su flujo de trabajo, solo una fracción mínima declara esa asistencia en sus artículos publicados.
- ¿Por qué los autores no revelan su uso de IA?
Staiman identifica varias razones clave:
a) Miedo a consecuencias negativas
Muchos autores temen que revelar el uso de IA sea interpretado como una señal de menor rigor, creatividad o capacidad académica, lo que podría influir negativamente en decisiones editoriales o de revisión por pares. Aunque las políticas puedan presentarse como neutrales, la percepción de estigma hace que los investigadores prefieran no mencionar su uso de IA.
b) Falta de claridad en las políticas
Las directrices actuales son muy heterogéneas y a menudo vagas: unas solo piden una declaración general, mientras que otras exigen documentación extensiva, incluyendo registros de chats con herramientas de IA. Esto causa confusión y lleva a los autores a preguntarse qué, cuándo y cómo deben declarar.
c) Carga burocrática sin incentivos
Muchas de estas exigencias demandan tiempo y esfuerzo significativos sin beneficios claros para los autores, lo que dificulta su adopción voluntaria.
d) Falta de consciencia del propio uso de IA
Algunos autores no se dan cuenta de que están empleando IA porque esta está integrada de manera invisible en herramientas cotidianas (por ejemplo, asistentes de escritura o búsqueda).
e) Confusión entre IA y plagio
Existe la percepción equivocada de que usar IA es equivalente a plagiar o engañar, lo que lleva a algunos autores a ocultar su uso deliberadamente en lugar de explicarlo con transparencia.
f) Políticas sin mecanismos de cumplimiento
Solo existiendo normas formales sin mecanismos claros de verificación o consecuencias percibidas, muchos autores simplemente apuestan a que no se les pedirá pruebas o explicaciones posteriores.
- ¿Qué no deben hacer los editores?
En el primer artículo, Staiman también advierte sobre lo que no es útil para resolver este problema:
Invertir fuertemente en herramientas de detección automática de IA, ya que son poco fiables y tienden a reforzar la idea de que el uso de IA es inherentemente sospechoso en lugar de normal.
- Cómo deberían abordar los editores el uso de IA (Parte 2)
En el segundo artículo de la serie, Staiman propone un cambio de foco fundamental: no se trata de documentar cada paso del uso de IA, sino de asegurar confianza en los resultados, reproducibilidad y responsabilidad científica.
a) Formular la pregunta correcta
En lugar de preguntar “¿Cómo usaste IA?”, los editores deberían centrarse en preguntas clásicas de integridad científica:
¿Los datos son fiables y transparentes?
¿Los métodos están claros y pueden reproducirse?
¿El análisis es robusto y verificable?
Este enfoque sitúa las preocupaciones en resultados y calidad de la investigación, no en la herramienta en sí.
b) Declaraciones estructuradas y de bajo coste
Staiman recomienda que las revistas implementen formularios simples donde los autores marquen categorías de uso de IA (p.ej., búsqueda, análisis, generación de código, revisión lingüística), en lugar de exigir narrativas detalladas o capturas de pantalla. Esto reduce la carga y mejora la consistencia en las declaraciones.
c) Requisitos escalonados según el riesgo
No todos los usos de IA implican el mismo nivel de riesgo para la reproducibilidad. Por ejemplo:
Edición de texto y traducción – no debería requerir declaración exhaustiva.
Análisis de datos o generación de código científico – sí debería requerir declaraciones específicas y mayor escrutinio editorial.
d) Afirmaciones explícitas de responsabilidad
Una declaración formal de autoría que afirme que el autor se responsabiliza plenamente de todos los elementos científicos, independientemente de las herramientas utilizadas, puede ayudar a centrar el debate en la integridad científica y no en la tecnología.
e) Educación y cambio cultural
Es clave que editores y revisores reciban entrenamiento para evaluar el impacto del uso de IA sobre la metodología y la reproducibilidad, y no para juzgar la estética o estilo de escritura generado por IA