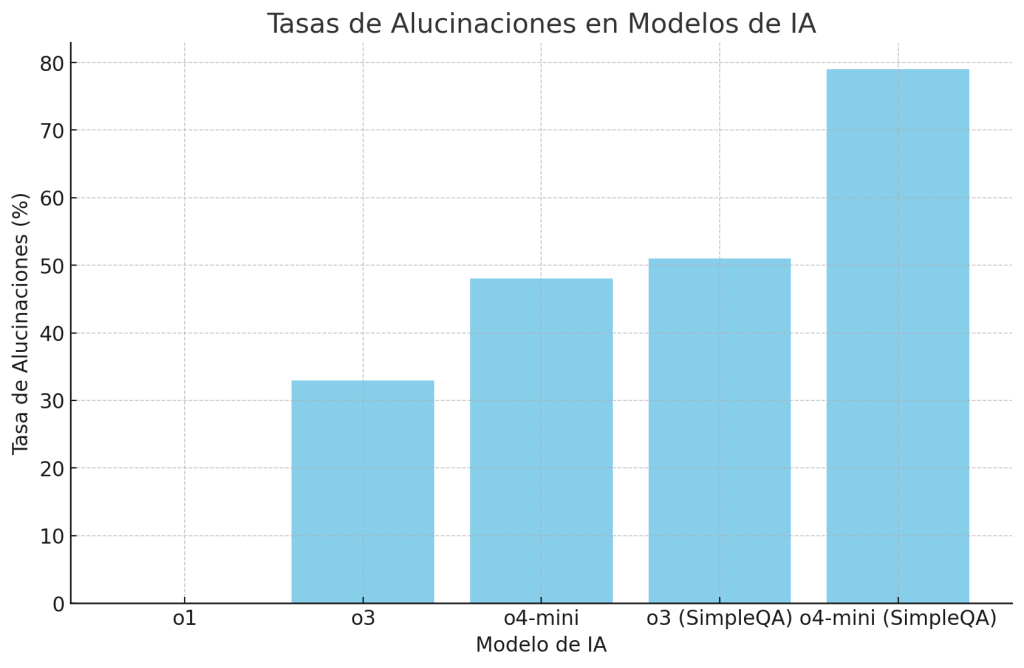
Ayoub, George. “Need the Truth? Knowledge? Visit a Library.” Nebraska Examiner, April 7, 2025. https://nebraskaexaminer.com/2025/04/07/need-the-truth-knowledge-visit-a-library/?utm_source=flipboard&utm_content=topic/librarianship
El 2 de abril, se conmemora el Día Internacional de la Verificación de Hechos. Esta fecha, promovida por la International Fact-Checking Network, subraya la importancia crucial de verificar la información para promover un discurso público honesto, invalidar mitos y reforzar la responsabilidad en el periodismo.
En un mundo saturado de desinformación, las bibliotecas continúan siendo un refugio vital donde las personas pueden distinguir entre hechos y ficción. Mientras navegamos en el “laberinto moderno” para encontrar la verdad, las bibliotecas se mantienen como un baluarte contra la propaganda y la información falsa.
Sin embargo, el artículo alerta sobre recientes órdenes ejecutivas del gobierno federal (109 órdenes para el 1 de abril) que afectan negativamente a las bibliotecas y museos en Estados Unidos, en particular al Instituto de Servicios para Museos y Bibliotecas (IMLS), que apoya financieramente a estas instituciones. Todo el personal del IMLS está en licencia administrativa pagada, lo que podría perjudicar especialmente a bibliotecas y museos rurales y pequeños.
Un ejemplo del impacto positivo del IMLS es un proyecto en Nebraska que, en 2019, proporcionó fondos para crear “estudios de innovación” itinerantes en bibliotecas rurales, ofreciendo a las comunidades herramientas, materiales y programas para fomentar la creatividad y el emprendimiento local. Este instituto apoya todos los tipos de bibliotecas y museos, siendo la única agencia federal dedicada a sostener este ecosistema cultural en Estados Unidos.
La American Library Association (ALA) expresó su preocupación porque las medidas administrativas amenazan servicios esenciales como programas de alfabetización temprana, acceso a internet de alta velocidad, asistencia para empleo, recursos para tareas escolares e investigación, y materiales accesibles para la lectura. Según estudios internos, la mayoría de los votantes y padres considera que las bibliotecas públicas locales desempeñan un papel fundamental en sus comunidades.
El gobierno de Trump defendió los recortes como una forma de fortalecer la integridad y reducir la burocracia federal, alegando que se eliminaban iniciativas consideradas “discriminatorias” o “antiamericanas”, especialmente aquellas relacionadas con diversidad, equidad e inclusión (DEI). El autor cuestiona este mandato dado que el presidente ganó con apenas el 49.81% del voto y señala la contradicción de acusar de “antiamericanismo” a instituciones que justamente promueven diversidad cultural, ideas y arte.
El artículo enfatiza que las bibliotecas y museos son lugares de diversidad, imaginación, comunidad y conocimiento, proporcionando acceso a la verdad, estimulando la creatividad y funcionando como espacios de exploración y asombro para todas las edades, a través de libros, tecnología, clases y numerosos programas.
El autor confiesa ser un apasionado lifelong de las bibliotecas, recordando su primera experiencia en la Carnegie Library de Grand Island y su frecuente visita a bibliotecas públicas en Los Ángeles y Lincoln. Considera incomprensible cómo la eliminación de un pequeño instituto que apoya bibliotecas y museos puede beneficiar al público estadounidense.
Finalmente, con ironía menciona que el viernes anterior fue el “Día Nacional de Contar una Mentira”, un contrapunto perfecto para la semana. Para verificar si alguien dice la verdad, hay varias opciones en línea, pero la recomendación final es confiar en un lugar seguro y fiable: la biblioteca.