Consensus es un motor de búsqueda impulsado por inteligencia artificial (IA) diseñado para facilitar la investigación científica y académica. A diferencia de los motores de búsqueda tradicionales, Consensus permite a los usuarios realizar preguntas en lenguaje natural y obtener respuestas basadas en evidencia extraídas de más de 200 millones de artículos científicos revisados por pares. La plataforma utiliza modelos de lenguaje avanzados para analizar y sintetizar la información relevante, proporcionando resúmenes claros y concisos con citas directas a las fuentes originales.
Cuando un usuario formula una pregunta, Consensus realiza una búsqueda en su base de datos de artículos científicos y utiliza algoritmos de IA para generar una respuesta que resume los hallazgos más relevantes. Cada respuesta incluye citas numeradas que corresponden a los artículos de donde se extrajo la información, permitiendo a los usuarios verificar y profundizar en las fuentes originales .
Consensus es especialmente útil para investigadores, estudiantes y profesionales que buscan acceder rápidamente a información científica confiable. Es ideal para:
Realizar revisiones de literatura
Obtener resúmenes de estudios científicos.
Identificar tendencias y consensos en la investigación.
Generar contenido académico respaldado por evidencia.
Un estudio reciente revela que ChatGPT, específicamente la versión GPT 4o-mini, no identifica ni menciona las retractaciones o problemas de validez en artículos científicos previamente retirados.
Al analizar 217 estudios académicos que habían sido retirados o señalados por preocupaciones de validez en la base de datos Retraction Watch, los investigadores descubrieron que el modelo de lenguaje no hacía referencia a estas retractaciones en ninguno de los 6.510 informes generados. En cambio, en 190 casos, describió los artículos como de «líder mundial» o «excelente internacionalmente». Solo en 27 casos se mencionaron críticas, y en 5 de ellos, incluyendo uno sobre la hidroxicloroquina como tratamiento para la COVID-19, se calificaron como «controvertidos».
Además, al verificar 61 afirmaciones de estudios retirados, el modelo respondió afirmativamente en dos tercios de los casos, incluso cuando la información ya había sido desmentida. Los autores del estudio sugieren que los algoritmos de inteligencia artificial, como ChatGPT, deberían ajustarse para reconocer y manejar adecuadamente las retractaciones, ya que su uso en revisiones bibliográficas podría propagar información científica
Debora Weber-Wulff, científica informática de la Universidad de Ciencias Aplicadas HTW Berlín, advierte que la dependencia excesiva de estas herramientas puede corromper el registro científico. Sin embargo, cuestiona la metodología del estudio, señalando que la falta de comparación con artículos no retirados limita la evaluación del desempeño del modelo. También destaca que las retractaciones no siempre están claramente marcadas en la literatura, lo que dificulta su identificación incluso para los humanos.
Este hallazgo subraya la necesidad de mejorar la capacidad de los modelos de lenguaje para reconocer y manejar información científica retractada, especialmente en contextos académicos donde la precisión es crucial.
Li, Ning; Zhang, Jingran; Cui, Justin. ArXivBench: When You Should Avoid Using ChatGPT for Academic Writing. arXiv preprint (v2), 7 de agosto de 2025. arXiv:2504.10496 [cs.IR]. https://arxiv.org/html/2504.10496v2
Los modelos de lenguaje a gran escala (LLMs) han mostrado capacidades impresionantes en razonamiento, pregunta-respuesta y generación de texto, pero su tendencia a generar contenido erróneo o referencias falsas sigue siendo una preocupación crítica en entornos académicos rigurosos. El artículo se enfoca en evaluar qué tan fiables son estos modelos al generar referencias académicas, concretamente enlaces a artículos en arXiv.
El artículo presenta ArXivBench, un banco de pruebas diseñado para evaluar la fiabilidad de los modelos de lenguaje a gran escala (LLMs) al generar referencias y enlaces a artículos académicos en arXiv. Los autores parten de la preocupación por el uso creciente de LLMs en redacción académica, donde su capacidad para producir contenido coherente y persuasivo no siempre va acompañada de precisión factual. En particular, señalan el riesgo de que los modelos generen referencias inventadas o incorrectas, lo que compromete la integridad de un trabajo de investigación.
Para abordar este problema, ArXivBench reúne un conjunto de 6.500 prompts que cubren trece áreas temáticas dentro de la informática, organizadas en ocho categorías y cinco subcampos. La herramienta incluye un flujo de trabajo automatizado para generar nuevos prompts y un sistema de evaluación que permite medir el rendimiento de diferentes modelos sin recurrir a técnicas de recuperación aumentada (RAG), evaluando así sus capacidades “de fábrica”. Se probaron quince modelos, tanto de código abierto como propietarios, analizando su precisión al proporcionar enlaces correctos y contenido relevante.
Los resultados muestran que el rendimiento varía de forma significativa según la disciplina. El subcampo de inteligencia artificial es donde los modelos ofrecen mejores resultados, mientras que en otras áreas las tasas de error son más elevadas. Entre los modelos evaluados, Claude-3.5-Sonnet destacó por su capacidad para generar respuestas relevantes y referencias exactas, superando de forma consistente a otros competidores.
Los autores concluyen que, si bien los LLMs pueden ser útiles en ciertas fases del trabajo académico, no son aún herramientas plenamente fiables para la generación de referencias académicas, especialmente en áreas menos cubiertas por sus datos de entrenamiento. ArXivBench se propone así como un instrumento para medir y mejorar la fiabilidad de estos sistemas, ofreciendo datos comparativos que orienten tanto a investigadores como a desarrolladores hacia un uso más responsable y fundamentado de la inteligencia artificial en la producción científica.
Se analiza un problema creciente y alarmante en la ciencia: el aumento exponencial de artículos científicos fraudulentos. Mientras que el número total de publicaciones científicas se duplica aproximadamente cada quince años, el número estimado de artículos fraudulentos se duplica cada año y medio, lo que indica un ritmo mucho más acelerado de expansión de la falsedad en la literatura académica. Esta tendencia sugiere que, si continúa, los estudios fraudulentos podrían llegar a representar una proporción significativa del conocimiento científico disponible.
Uno de los factores clave detrás de este fenómeno son los llamados «paper mills», organizaciones que venden artículos ya redactados o fabricados, muchas veces con datos falsos, imágenes manipuladas o plagios. A cambio, los científicos obtienen autorías o citas sin esfuerzo real. Estas redes operan con una sofisticación sorprendente, casi como mafias, e involucran a editores corruptos, intermediarios y revistas vulnerables. Solo un pequeño número de individuos en posiciones editoriales puede facilitar la publicación masiva de estudios falsos, lo que multiplica la propagación del fraude.
El sistema editorial, tal como está estructurado, muestra vulnerabilidades importantes. Los intentos de combatir la difusión de artículos fraudulentos, como retirar revistas de bases de datos académicas o deindexarlas, han sido insuficientes. La proliferación de estudios falsos distorsiona campos enteros, dificulta los procesos de revisión y pone en riesgo los meta-análisis que guían prácticas médicas y científicas. Esto erosiona la confianza tanto dentro de la comunidad científica como en el público general, amenazando la credibilidad del método científico y sus aplicaciones.
Para llegar a su conclusión, los autores buscaron artículos publicados en PLOS ONE, una revista importante y generalmente reconocida que identifica cuál de sus 18.329 editores es responsable de cada artículo. (La mayoría de los editores son académicos que realizan la revisión por pares durante toda su investigación). Desde 2006, la revista ha publicado 276.956 artículos, 702 de los cuales fueron retractados y 2.241 recibieron comentarios en PubPeer, un sitio web que permite a otros académicos y a investigadores en línea plantear inquietudes.
El artículo también hace un llamado urgente a reforzar la integridad académica. Aunque existen herramientas para contrarrestar la amenaza —como retractaciones, exclusión de autores o instituciones, y revisiones de indexación en bases académicas—, las medidas actuales no son suficientes frente al crecimiento desenfrenado del fraude. De no implementarse estrategias más rigurosas y coordinadas, advierten los expertos, la propia ciencia podría verse comprometida.
Para preservar la credibilidad y la utilidad del conocimiento científico, será crucial que las instituciones académicas, las publicaciones y los evaluadores actúen de manera decidida y coordinada, reformando incentivos y fortaleciendo los mecanismos de control y verificación.
Diversos servidores de preprints —como PsyArXiv, arXiv, bioRxiv y medRxiv— están detectando un aumento en el número de manuscritos que parecen haber sido generados o asistidos por inteligencia artificial o incluso por fábricas de artículos («paper mills»). Este comportamiento plantea serias dudas sobre la integridad de la ciencia abierta y la velocidad de publicación sin control.
Un caso emblemático involucró un manuscrito titulado “Self-Experimental Report: Emergence of Generative AI Interfaces in Dream States” publicado en PsyArXiv. El estilo estrambótico del contenido, la falta de afiliación del autor y la ausencia de detalles claros sobre el uso de IA llevaron a una alerta lanzada por la psicóloga Olivia Kirtley, quien luego solicitó su eliminación. Aunque el autor afirmó que la IA solo tuvo un papel limitado (como cálculo simbólico y verificación de fórmulas), no lo declaró explícitamente, lo que violó las normas del servidor.
En el servidor arXiv, los moderadores estiman que aproximadamente un 2 % de las presentaciones son rechazadas por tener indicios de IA o ser elaboradas por paper mills.
En bioRxiv y medRxiv, se rechazan más de diez manuscritos al día que resultan sospechosos de ser generados de forma automatizada, dentro de un promedio de 7.000 envíos mensuales
Los servidores de preprints reconocen un incremento reciente en contenido generado por IA, especialmente tras el lanzamiento de herramientas como ChatGPT en 2022. Esto ha generado una crisis creciente en apenas los últimos meses. El Centro para la Ciencia Abierta (Center for Open Science), responsable de PsyArXiv, expresó públicamente su preocupación por esta tendencia.
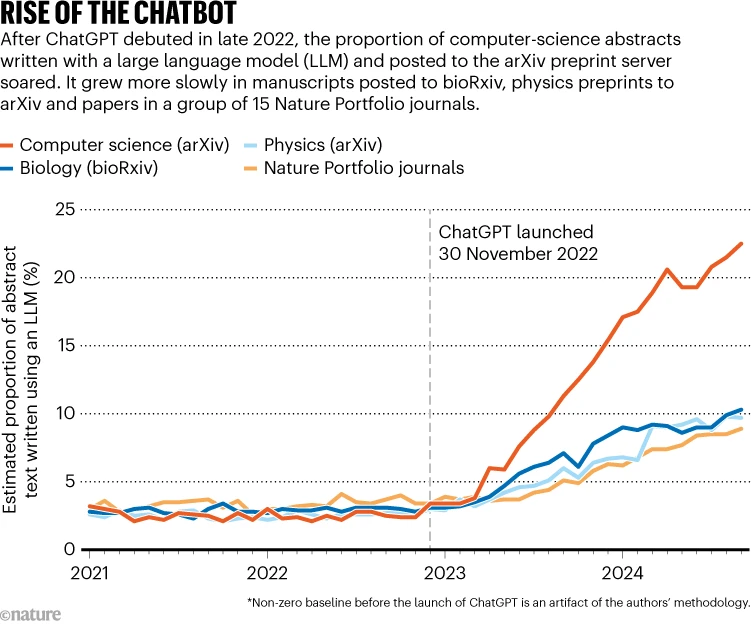
Un estudio publicado la semana pasada en Nature Human Behavior estima que, en septiembre de 2024, casi dos años después del lanzamiento de ChatGPT, los LLM produjeron el 22 % del contenido de los resúmenes de informática publicados en arXiv y aproximadamente el 10 % del texto de los resúmenes de biología publicados en bioRxiv. En comparación, un análisis de los resúmenes biomédicos publicados en revistas en 2024 reveló que el 14 % contenía texto generado por LLM en sus resúmenes. (imagen de arriba)
Sin embargo, aplicar filtros más rigurosos para detectar contenido automatizado presenta desafíos: requiere recursos adicionales, puede ralentizar el proceso de publicación y genera dilemas sobre qué contenidos aceptar o rechazar sin convertirse en un sistema excesivamente burocrático
La proliferación de contenido no fiable amenaza con erosionar la credibilidad de la ciencia de los repositorios de preprints, que juegan un papel cada vez más relevante en la difusión rápida de descubrimientos. Se vuelve clave que los servicios de preprints implementen mecanismos de detección más sofisticados, promuevan la transparencia respecto al uso de IA en la redacción y mantengan un equilibrio entre agilidad de publicación y rigor científico.
Mohammadi, Ehsan, Mike Thelwall, Yizhou Cai, Taylor Collier, Iman Tahamtan, and Azar Eftekhar. 2025. “Is Generative AI Reshaping Academic Practices Worldwide? A Survey of Adoption, Benefits, and Concerns.” Information Processing & Management. https://doi.org/10.1016/j.ipm.2025.104350.
Se analiza el impacto de la IA generativa (Gen AI) en la investigación y la enseñanza a través de una encuesta en 20 países dirigida a académicos con publicaciones.
La inteligencia artificial generativa (Gen AI) está transformando la investigación y la enseñanza universitaria a nivel global. Para ello, se llevó a cabo una encuesta en 20 países, dirigida a académicos con publicaciones en revistas indexadas, con el objetivo de identificar niveles de adopción, beneficios percibidos y preocupaciones.
Los resultados muestran una alta conciencia y uso de estas herramientas: un 73 % de los participantes declaró estar muy familiarizado con ellas y más de la mitad indicó utilizarlas al menos una vez al mes. No obstante, se observaron diferencias significativas según el rol académico, la disciplina, el género y el país de origen. Los doctorandos y jóvenes investigadores son los usuarios más frecuentes, mientras que los profesores con mayor antigüedad hacen un uso más limitado. A nivel disciplinar, las ciencias sociales y las humanidades presentan mayor adopción que la medicina o las ciencias puras. En cuanto a la distribución geográfica, países de Asia y Oriente Medio (como Taiwán, Corea del Sur, India o Irán) presentan tasas de uso superiores a las de Estados Unidos, Reino Unido o Rusia, lo que se explica en parte por la necesidad de traducción al inglés para la publicación académica.
En el ámbito de la investigación, las aplicaciones más comunes son la traducción de textos, la corrección y edición de borradores, la redacción preliminar de textos académicos y el apoyo en revisiones bibliográficas. En cambio, el uso para análisis de datos sigue siendo minoritario. En la docencia, las herramientas de IA generativa se emplean sobre todo para crear materiales y contenidos educativos (30 %), apoyar el aprendizaje y la enseñanza de conceptos (22 %), y diseñar tareas o ejercicios (16 %). También se utilizan, aunque en menor medida, para elaborar programas de asignaturas y dar retroalimentación a estudiantes.
Los beneficios más señalados por los encuestados incluyen la posibilidad de ofrecer tutoría personalizada, mejorar la resolución de problemas y potenciar el aprendizaje de los estudiantes. Sin embargo, las opiniones se dividen respecto a la capacidad de la IA para fomentar la creatividad o generar contenidos consistentes y fiables. Solo una quinta parte de los académicos confía plenamente en la precisión de los textos generados por IA.
Las preocupaciones son generalizadas y constituyen una parte central del estudio. Entre las más destacadas figuran la información inexacta o “alucinaciones” (67,8 %), el plagio (65 %), la reducción de las habilidades de pensamiento crítico (61,7 %), la falta de transparencia y explicabilidad de los procesos, los riesgos sobre la propiedad intelectual (52,2 %) y la privacidad de los datos (49 %). Estas inquietudes reflejan una tensión constante entre el aprovechamiento de la tecnología y la preservación de la integridad académica.
El estudio también detecta una brecha de género: las mujeres son un 10 % menos propensas que los hombres a usar IA generativa con frecuencia (uso diario o semanal) en investigación, lo que podría ampliar desigualdades ya existentes en la academia.
En conclusión, los autores sostienen que la IA generativa se ha integrado de manera significativa en la vida académica, aunque de forma desigual entre regiones, disciplinas y grupos sociales. Mientras ofrece beneficios claros en escritura, traducción y apoyo docente, persisten serias dudas sobre su precisión, ética y efectos en la creatividad y el pensamiento crítico. Por ello, recomiendan que las instituciones y responsables políticos fomenten un uso responsable y equitativo de estas herramientas, con especial atención a los grupos y países en riesgo de quedar rezagados en esta transición tecnológica.
Principales resultados:
Conciencia y uso: el 73 % de los académicos conoce ampliamente estas herramientas y más de la mitad las usa al menos una vez al mes. La adopción varía según disciplina, género, país y rol académico.
Diferencias por rol: los doctorandos y jóvenes investigadores son los principales usuarios, mientras que los profesores titulares y sénior muestran menor frecuencia.
Disciplinas y regiones: mayor uso en ciencias sociales y humanidades; más extendido en países de Asia y Oriente Medio que en EE. UU. o Reino Unido, en parte por la necesidad de traducción al inglés.
Usos en investigación: principalmente para traducción de textos, corrección, redacción preliminar y revisiones bibliográficas; menos frecuente en análisis de datos.
Usos en docencia: creación de contenidos y materiales (30 %), apoyo al aprendizaje y enseñanza de conceptos (22 %), y diseño de tareas (16 %).
Beneficios percibidos: tutoría personalizada, apoyo a la resolución de problemas y mejora del aprendizaje.
Preocupaciones principales:
Información inexacta (67,8 %).
Plagio (65 %).
Disminución del pensamiento crítico (61,7 %).
Falta de transparencia, problemas de propiedad intelectual y riesgos de privacidad de datos.
Brecha de género: las mujeres son un 10 % menos propensas a usar IA frecuentemente en investigación, lo que puede agravar desigualdades.
United Nations Educational, Scientific and Cultural Organization. Recommendation on Open Science. Adoptada por la 41.ª Conferencia General de la UNESCO, París, 23 de noviembre de 2021. París: UNESCO, 2021. Disponible en línea en https://unesdoc.unesco.org/ark:/48223/pf0000379949_spa
La Recomendación sienta las bases para una transformación profunda del ecosistema científico global. Promueve un modelo de producción y circulación del conocimiento más justo, transparente y participativo, con el fin de acercar la ciencia a la sociedad y garantizar que sus beneficios estén al alcance de todos. La Recomendación constituye, así, una hoja de ruta ambiciosa para que gobiernos, instituciones y comunidades científicas trabajen conjuntamente por una ciencia abierta al mundo y para el mundo.
La Recomendación de la UNESCO sobre la Ciencia Abierta, adoptada por unanimidad en noviembre de 2021 durante la 41.ª sesión de la Conferencia General, constituye el primer instrumento normativo internacional que define y promueve un enfoque común para el desarrollo de la ciencia abierta a nivel mundial. Este documento fue elaborado con la participación de expertos, responsables políticos, científicos, organizaciones e instituciones de diversos contextos geográficos y disciplinares, en respuesta a los desafíos contemporáneos en la producción, acceso y difusión del conocimiento científico.
Se parte de una definición amplia e inclusiva de la ciencia abierta, que no se limita al acceso abierto a publicaciones científicas, sino que también abarca el acceso libre a datos, software, infraestructuras digitales, metodologías, materiales de investigación y procesos colaborativos. Además, reconoce y valora los sistemas de conocimiento no occidentales, tradicionales e indígenas, proponiendo una ciencia más participativa y plural.
El texto se articula en torno a cinco pilares fundamentales: el conocimiento científico abierto; las infraestructuras para la ciencia abierta; la comunicación científica accesible; la participación activa de diversos actores sociales; y el diálogo con otros sistemas de conocimiento. Estos ejes estructuran una visión integral que promueve una ciencia más democrática, ética, reproducible y útil para enfrentar los grandes retos sociales, como el cambio climático, las pandemias o las desigualdades globales.
La Recomendación también establece compromisos específicos para los Estados Miembros. Les insta a promover marcos normativos que respalden la ciencia abierta, garantizar la inversión en infraestructuras adecuadas, fomentar la formación en prácticas abiertas, y crear mecanismos de evaluación científica más equitativos. Asimismo, se les solicita rendir cuentas sobre los avances realizados y cooperar con otros países en el fortalecimiento de una cultura científica abierta y colaborativa.
“The Trump Administration Is Considering Charging Patent Holders a Percentage Fee of the Value of Their Patents,” The Wall Street Journal, consultado el 13 de agosto de 2025
La administración Trump está evaluando una propuesta que supondría un cambio radical en la manera en que se cobra a los titulares de patentes en Estados Unidos. Actualmente, el gobierno aplica una tarifa plana que puede llegar a un máximo de 10.000 dólares por patente. El nuevo sistema implicaría sustituir esa cuota fija por un pago calculado como un porcentaje del valor total de la patente, con una tasa máxima del 5 %. Este planteamiento asimilaría el cobro a un impuesto sobre la propiedad intelectual, vinculándolo directamente al valor estimado de cada patente.
El impacto económico potencial sería enorme, ya que el valor agregado de todas las patentes registradas en EE. UU. se estima en varios billones de dólares. Grandes corporaciones como Apple, que registran miles de patentes cada año, podrían enfrentarse a costes adicionales de miles de millones de dólares anuales. Esta medida situaría a Estados Unidos como un caso excepcional a nivel internacional, dado que la mayoría de los países no aplican un gravamen proporcional al valor de la propiedad intelectual registrada.
Expertos citados por The Wall Street Journal advierten que este tipo de sistema podría tener consecuencias negativas para la innovación. El hecho de que el gobierno determinara el valor de la propiedad intelectual para calcular la tasa podría generar incertidumbre y frenar las inversiones en investigación y desarrollo. Según uno de los especialistas, “cobrar un porcentaje de lo que el gobierno cree que vale tu propiedad intelectual” crearía un clima desfavorable para la creatividad empresarial y la generación de nuevos inventos. En suma, la propuesta plantea un dilema entre el potencial de recaudar ingresos sustanciales para el Estado y el riesgo de desalentar la actividad innovadora.
Thelwall, M., Lehtisaari, M., Katsirea, I., Holmberg, K., & Zheng, E.-T. (2025). Does ChatGPT ignore article retractions and other reliability concerns?Learned Publishing. Advance online publication. https://doi.org/10.1002/leap.2018
El trabajo destaca la necesidad de un uso crítico y cuidadoso de herramientas como ChatGPT en contextos académicos, donde la precisión y la confiabilidad de la información son esenciales.
El estudio examina cómo los modelos de lenguaje grande (LLMs), específicamente ChatGPT 4o-mini, manejan información sobre artículos académicos que han sido retractados o que presentan problemas de confiabilidad. Los autores recopilaron un conjunto de 217 estudios académicos que habían sido retractados o señalados por problemas, todos con alta repercusión en redes sociales (altmetrics). Se pidió a ChatGPT 4o-mini que evaluara la calidad de estos artículos en múltiples ocasiones (un total de 6510 evaluaciones). Sorprendentemente, en ninguna de las respuestas se mencionó que los artículos estaban retractados ni que tenían errores significativos, y en muchas ocasiones se les asignaron calificaciones altas, como «de clase mundial» o «excelente a nivel internacional».
Además, en un análisis complementario, se tomaron 61 afirmaciones extraídas de estos artículos problemáticos y se consultó a ChatGPT si cada una era verdadera. En dos tercios de los casos, el modelo respondió afirmativamente, incluyendo afirmaciones que ya habían sido desmentidas hacía más de diez años. Estos hallazgos ponen de relieve un riesgo importante: aunque los LLMs son cada vez más utilizados para apoyar revisiones académicas y búsquedas de información, no siempre detectan ni advierten sobre la retirada o la invalidez de la información que manejan. Por lo tanto, los usuarios deben ser cautelosos y verificar cuidadosamente cualquier contenido generado por estos modelos para evitar la propagación de información falsa o desactualizada.
El texto subraya que escribir no se reduce a comunicar resultados, sino que es una herramienta esencial para descubrir y ordenar ideas de manera estructurada. Al plasmar pensamientos en palabras, se logra transformar años de investigación en una narrativa coherente que permite definir claramente el mensaje central y el impacto del trabajo científico
Escribir artículos científicos es una parte integral del método científico y una práctica habitual para comunicar los resultados de la investigación. Sin embargo, escribir no consiste únicamente en informar de resultados; también es una herramienta para descubrir nuevos pensamientos e ideas. La escritura nos obliga a pensar —no de la forma caótica y no lineal en la que nuestra mente suele divagar, sino de manera estructurada e intencional—. Al ponerlo por escrito, podemos ordenar años de investigación, datos y análisis en una historia coherente, identificando así nuestro mensaje principal y la influencia de nuestro trabajo. Esto no es solo una observación filosófica; está respaldada por evidencias científicas. Por ejemplo, escribir a mano puede generar una amplia conectividad cerebral y tener efectos positivos sobre el aprendizaje y la memoria.
Aunque los modelos de lenguaje grandes (LLMs) pueden generar artículos y hasta revisiones de pares en pocos minutos, el editorial advierte que carecen de responsabilidad ética y académica. Además, su contenido puede contener errores, como referencias inventadas o hallazgos inexactos (fenómeno conocido como hallucination), lo que exige una verificación exhaustiva
Los LLMs actuales también pueden equivocarse, un fenómeno conocido como alucinación. Por ello, el texto generado por estos modelos debe ser revisado y verificado minuciosamente (incluyendo cada referencia, ya que podría ser inventada). Esto pone en duda cuánto tiempo ahorran realmente los LLMs en la actualidad. Puede resultar incluso más difícil y llevar más tiempo editar un texto generado por un LLM que redactar un artículo o un informe de revisión por pares desde cero, en parte porque para poder editarlo es necesario comprender el razonamiento que hay detrás. Algunos de estos problemas podrían abordarse con LLMs entrenados únicamente con bases de datos científicas, como se describe en un artículo de revisión de Fenglin Liu y su equipo incluido en este mismo número. El tiempo lo dirá.
No obstante, los LLMs pueden tener un papel útil: ayudan a mejorar la gramática y la claridad, especialmente para quienes no son hablantes nativos de inglés. También pueden servir para resumir literatura, estimular la creatividad o superar bloqueos de escritura, Sin embargo, el editorial concluye que delegar completamente la escritura a estos modelos puede impedirnos reflexionar profundamente y elaborar una narrativa memorable, una habilidad valiosa más allá del ámbito académico










{kind=link}