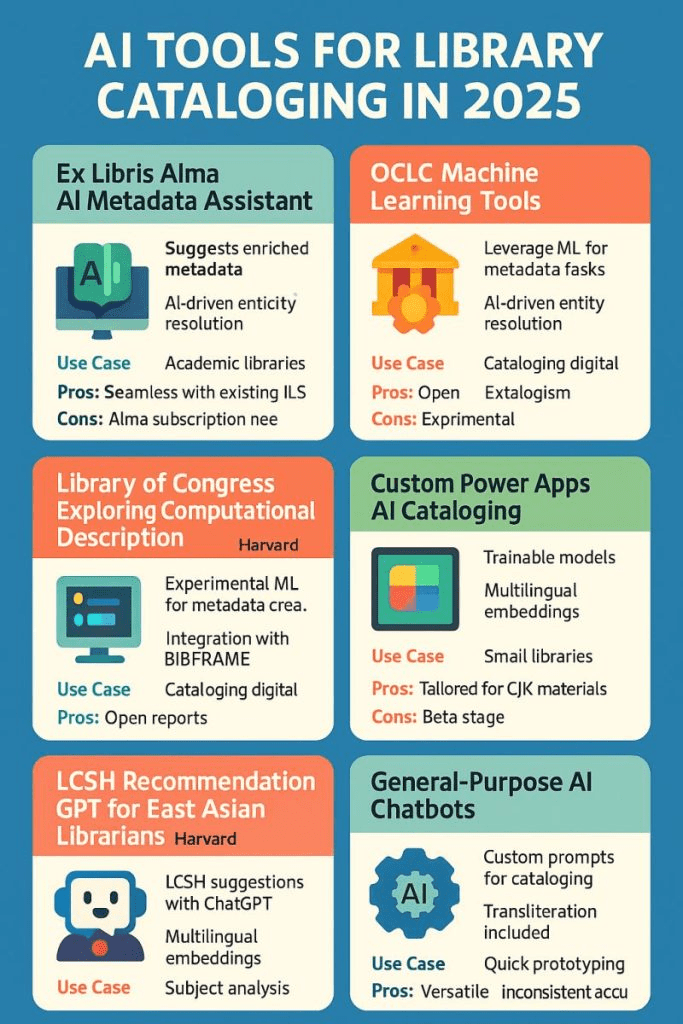
El contenido se divide en seis categorías principales que abarcan desde sistemas integrados comerciales hasta soluciones personalizadas y experimentales, destacando sus características, casos de uso, ventajas y limitaciones.
En el ámbito de las grandes plataformas, se mencionan el Ex Libris Alma AI Metadata Assistant y las herramientas de Machine Learning de OCLC. La primera está enfocada en bibliotecas universitarias para sugerir metadatos enriquecidos, destacando por su integración fluida con sistemas actuales, aunque requiere una suscripción. La segunda utiliza aprendizaje automático para la resolución de entidades en catalogación digital, caracterizándose por ser de código abierto pero aún en etapa experimental.
Por otro lado, instituciones académicas y gubernamentales lideran proyectos como el de la Biblioteca del Congreso y Harvard, que explora la descripción computacional y su integración con BIBFRAME para informes abiertos. Paralelamente, Harvard ha desarrollado una herramienta basada en GPT para bibliotecarios de Asia Oriental, la cual facilita sugerencias de encabezamientos de materia (LCSH) y análisis de temas mediante embeddings multilingües.
Finalmente, la infografía destaca soluciones más flexibles como las Custom Power Apps y los Chatbots de IA de uso general. Las Power Apps están diseñadas para bibliotecas pequeñas y materiales en idiomas asiáticos (CJK), ofreciendo modelos entrenables a pesar de estar en fase beta. Por su parte, los chatbots genéricos se utilizan para el prototipado rápido y la transliteración; aunque son muy versátiles, se advierte que su precisión puede ser inconsistente.
A continuación, se detallan los pros y contras de cada una de las 6 herramientas mencionadas en la infografía, para que puedas comparar sus ventajas y limitaciones:
1. Ex Libris Alma AI Metadata Assistant
- Pros: Su principal ventaja es la integración fluida (seamless) con el sistema ILS (Sistema Integrado de Gestión Bibliotecaria) que ya utilizan muchas bibliotecas académicas.
- Contras: Requiere obligatoriamente tener una suscripción activa a Alma, lo que representa un costo institucional elevado.
2. OCLC Machine Learning Tools
- Pros: Se destaca por ser un ecosistema de catalogación abierta, lo que fomenta la colaboración entre instituciones.
- Contras: Todavía se encuentra en una fase experimental, por lo que sus procesos podrían no ser totalmente estables o definitivos.
3. Library of Congress: Computational Description
- Pros: Ofrece informes abiertos (open reports), lo que permite transparencia en cómo se generan los metadatos bajo el estándar BIBFRAME.
- Contras: Al ser un proyecto de exploración institucional, su implementación práctica fuera de la Biblioteca del Congreso puede ser compleja o limitada.
4. Custom Power Apps AI Cataloging
- Pros: Es una solución altamente personalizada para materiales CJK (chino, japonés y coreano), permitiendo entrenar modelos específicos.
- Contras: Se encuentra en fase beta, lo que implica que aún está en desarrollo y puede presentar errores de funcionamiento.
5. LCSH Recommendation GPT (Harvard)
- Pros: Muy eficiente para el análisis de materias multilingües, ayudando a traductores y catalogadores con términos complejos de encabezamiento de materia (LCSH).
- Contras: (Aunque no se detalla explícitamente en el cuadro rojo, se infiere que depende de la precisión del modelo GPT de turno y del contexto específico de Harvard).
6. General-Purpose AI Chatbots (ChatGPT, etc.)
- Pros: Son herramientas extremadamente versátiles que sirven para prototipado rápido, traducción y transliteración de diversos idiomas.
- Contras: Tienen una precisión inconsistente. Al ser modelos generales, pueden cometer errores factuales («alucinaciones») en la creación de registros bibliográficos.









