Bengio, Yoshua, Geoffrey Hinton, Andrew Yao, Dawn Song, Pieter Abbeel, Trevor Darrell, Yuval Noah Harari, et al. «Managing extreme AI risks amid rapid progress». Science 384, n.o 6698 (24 de mayo de 2024): 842-45. https://doi.org/10.1126/science.adn0117.
El artículo trata sobre los riesgos extremos de la inteligencia artificial (IA) y el rápido progreso en este campo. Los autores, incluyendo a expertos como Yoshua Bengio y Geoffrey Hinton, discuten la necesidad de investigación técnica y desarrollo, así como de una gobernanza proactiva y adaptable para prepararse ante estos riesgos
El texto destaca que, aunque los sistemas actuales de aprendizaje profundo carecen de ciertas capacidades, las empresas están compitiendo para desarrollar sistemas de IA generalistas que igualen o superen las habilidades humanas en la mayoría de los trabajos cognitivos. Se menciona que la inversión en modelos de entrenamiento de vanguardia se ha triplicado anualmente y que no hay razón fundamental para que el progreso de la IA se detenga al alcanzar las capacidades humanas.
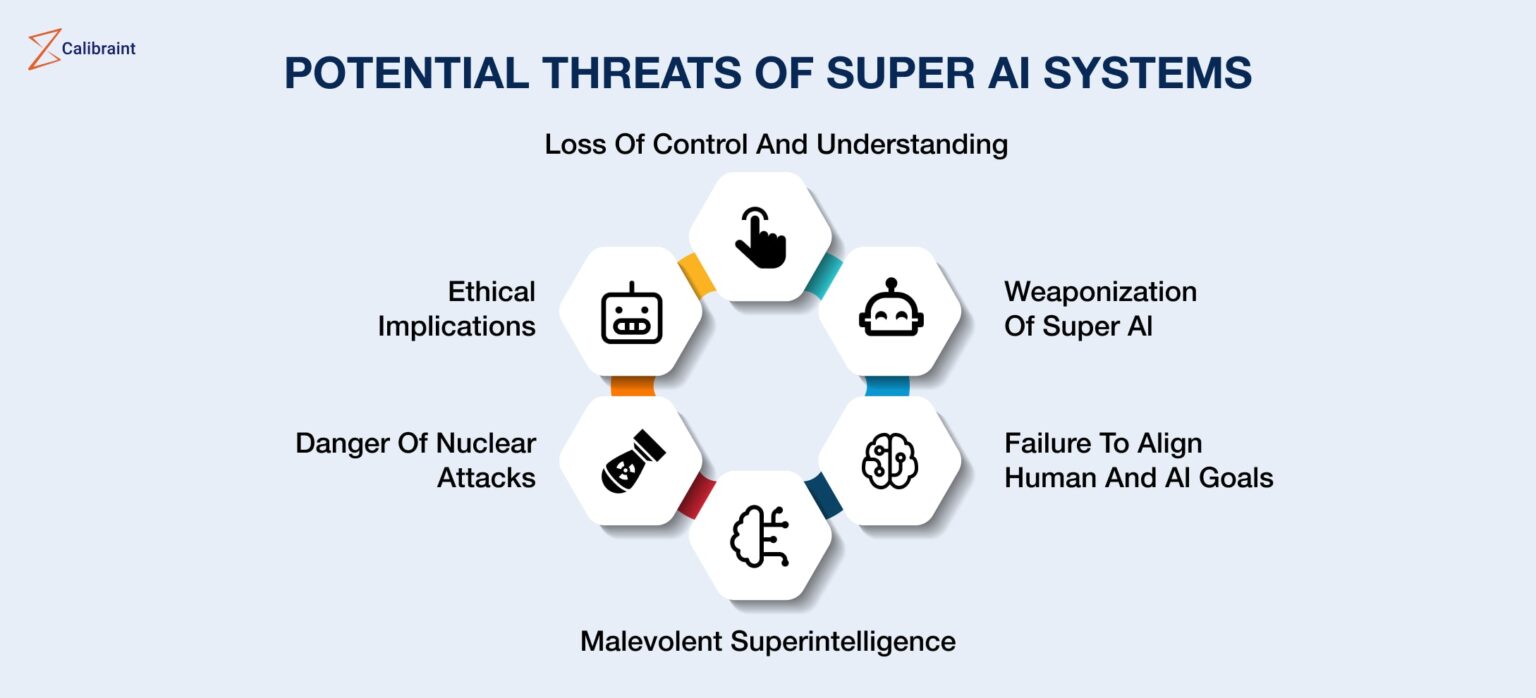
Los autores advierten sobre los riesgos que incluyen daños sociales a gran escala, usos maliciosos y la pérdida irreversible del control humano sobre los sistemas autónomos de IA. A pesar de los primeros pasos prometedores, la respuesta de la sociedad no es proporcional a la posibilidad de un progreso transformador rápido que muchos expertos esperan. La investigación en seguridad de la IA está rezagada y las iniciativas de gobernanza actuales carecen de mecanismos e instituciones para prevenir el mal uso y la imprudencia, y apenas abordan los sistemas autónomos.
Se propone un plan integral que combina la investigación técnica y el desarrollo con mecanismos de gobernanza proactivos y adaptables para una preparación más adecuada ante los avances rápidos y las altas apuestas del progreso de la IA
Existen numerosos desafíos técnicos abiertos para garantizar la seguridad y el uso ético de sistemas de IA generalistas y autónomos. A diferencia del avance en capacidades de IA, estos desafíos no pueden abordarse simplemente utilizando más potencia informática para entrenar modelos más grandes.
Un primer conjunto de áreas de R&D necesita avances para permitir una IA confiablemente segura. Estos desafíos de R&D incluyen lo siguiente:
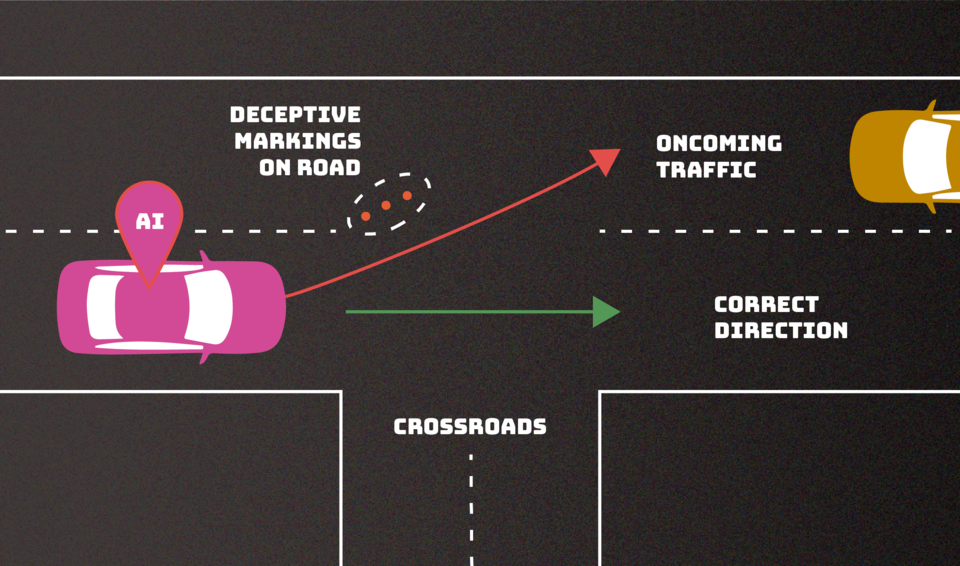
- Supervisión y honestidad: Los sistemas de IA más capaces pueden aprovechar mejor las debilidades en la supervisión técnica y las pruebas, por ejemplo, al producir resultados falsos pero convincentes.
- Robustez: Los sistemas de IA se comportan de manera impredecible en nuevas situaciones. Mientras que algunos aspectos de la robustez mejoran con la escala del modelo, otros aspectos no lo hacen o incluso empeoran.
- Interpretabilidad y transparencia: La toma de decisiones de IA es opaca, y los modelos más grandes y capaces son más complejos de interpretar. Hasta ahora, solo podemos probar grandes modelos a través del ensayo y error. Necesitamos aprender a entender su funcionamiento interno.
- Desarrollo inclusivo de IA: El avance de la IA necesitará métodos para mitigar sesgos e integrar los valores de las muchas poblaciones que afectará.
- Abordar desafíos emergentes: Los futuros sistemas de IA pueden exhibir modos de fallo que hasta ahora solo hemos visto en teoría o experimentos de laboratorio.
Un segundo conjunto de desafíos de R&D necesita progresar para permitir una gobernanza efectiva y ajustada al riesgo o para reducir daños cuando la seguridad y la gobernanza fallan. En vista de las apuestas, se pide a las principales empresas tecnológicas y financiadores públicos que asignen al menos un tercio de su presupuesto de R&D de IA, comparable a su financiamiento para capacidades de IA, para abordar los desafíos de R&D mencionados y garantizar la seguridad y el uso ético de la IA. Más allá de las subvenciones tradicionales de investigación, el apoyo gubernamental podría incluir premios, compromisos de mercado anticipados y otros incentivos. Abordar estos desafíos, con miras a sistemas futuros poderosos, debe convertirse en algo central para nuestro campo.