Communication of Retractions, Removals, and Expressions of Concern (CREC): A Recommended Practice of the National Information Standards Organization. NISO, 2024
La confianza es el elemento central de las comunicaciones académicas, distinguiéndolas de otras formas de publicación. Este artículo aborda la importancia de corregir errores en la publicación académica mediante procesos de retractación, eliminación y expresiones de preocupación. Estos procedimientos son cruciales para mantener la confianza en la validez de los resultados publicados.
Hasta ahora no habia una forma consistente de comunicar el estado de retractación de un trabajo académico. Hace dos semanas, NISO (National Information Standards Organization) emitió una nueva Práctica Recomendada sobre la Comunicación de Retractaciones, Eliminaciones y Expresiones de Preocupación (CREC). El objetivo de esta práctica es establecer mejores prácticas para la creación, transferencia y visualización de metadatos, facilitando la comunicación oportuna y eficiente de información a todos los interesados.
El proyecto CREC surgió de la Conferencia NISO Plus 2021, y con el apoyo de la Fundación Alfred P. Sloan, un grupo de trabajo de NISO compuesto por más de dos docenas de editores, intermediarios, bibliotecarios e investigadores desarrolló un conjunto de recomendaciones. La práctica recomendada establece una terminología consistente y protocolos de visualización para la presentación de trabajos retractados. También proporciona orientación sobre cómo distribuir metadatos relacionados con retractaciones y define las responsabilidades de los editores.
Algunas recomendaciones incluyen anteponer «RETRACTED:» en el título del artículo y usar marcas de agua y etiquetas consistentes en las páginas de contenido. Las notificaciones de retractación deben publicarse por separado, pero ser accesibles gratuitamente y vinculadas al contenido original debidamente etiquetado. Además, el documento describe cómo implementar estas recomendaciones y compartir la información con el ecosistema académico, incluyendo agregadores, servicios de descubrimiento y preservación.
El CREC define elementos de metadatos específicos para publicaciones retractadas y notificaciones de retractación, clasificándolos como «Esenciales», «Esenciales si están disponibles» o «Recomendados». Estos metadatos son cruciales para limitar la difusión de investigaciones retractadas en sistemas digitales.
Finalmente, la práctica recomendada de CREC está disponible gratuitamente y NISO organizará un seminario web sobre el tema el 23 de julio de 2024.
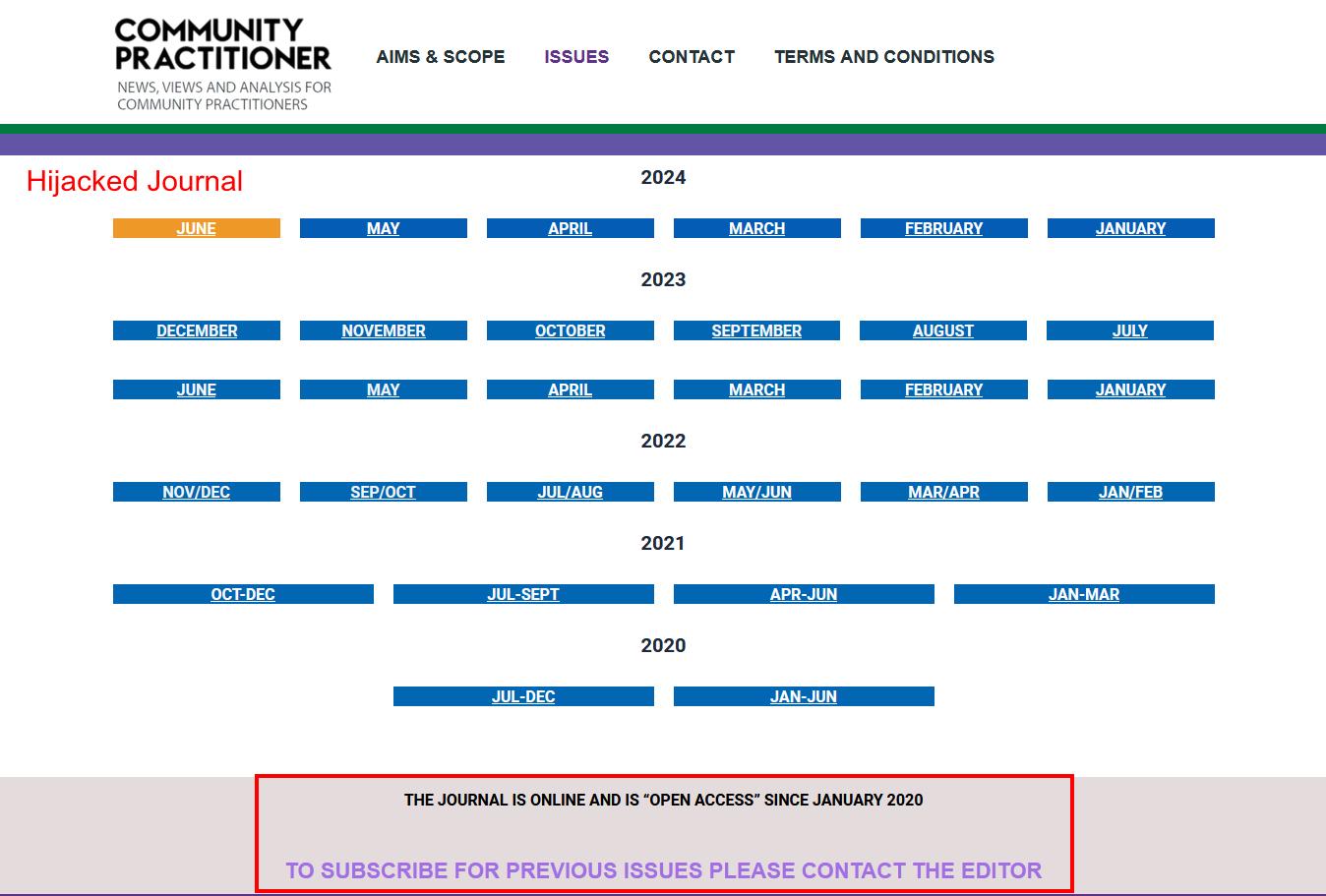
El 7 de julio de 2023, Mohammed Al-Amr informó a través de 𝕏 que la página de inicio de la revista en Scopus había sido comprometida y redirigía a los usuarios a un sitio web fraudulento que se hacía pasar por la publicación legítima.
A pesar de esta revelación, el equipo editorial de la revista no respondió ni advirtió a los autores sobre el clon engañoso. En diciembre de 2023, Scopus tomó medidas, eliminando los enlaces a la página de inicio de la publicación para combatir el secuestro.
Mientras que el verdadero Community Practitioner es una revista basada en suscripción y enfocada en medicina y enfermería, el sitio web falso afirmaba ser una publicación de acceso abierto desde enero de 2020 y ofrecía suscripciones a números anteriores contactando con «el editor». También anunciaba la posibilidad de publicar artículos en todos los campos de investigación, lo cual se desvía claramente del enfoque de la publicación legítima.
El análisis de la base de datos de Scopus reveló 880 artículos falsos de la revista secuestrada, indexados entre 2020 y 2024, provenientes de países como India, Indonesia, Irak, Malasia y Arabia Saudita. Muchos de estos artículos estaban plagiados, con DOIs copiados de otras revistas.
Los signos evidentes de estos artículos falsos incluyen volúmenes, números y páginas inconsistentes en comparación con la publicación legítima. Algunos también tienen DOIs de Zenodo, un servicio que la Community Practitioner auténtica no utiliza.
Las consecuencias de esta infiltración son de gran alcance. Los autores de estos artículos fraudulentos pueden haber obtenido beneficios injustos al ser indexados en Scopus, asegurando ascensos académicos, empleos y credenciales bajo pretensiones falsas. La reputación de la revista legítima ha sido dañada, y su métrica CiteScore se ha visto comprometida por la afluencia de artículos falsos con pocas o ninguna cita desde 2020.
Eliminar simplemente el URL de la página de inicio de la revista secuestrada de Scopus no ha sido suficiente, ya que el contenido fraudulento sigue en la base de datos, socavando su integridad. Se necesita una estrategia más completa para eliminar no solo los enlaces visibles a las revistas fraudulentos, sino también para prevenir que su contenido infiltre las bases de datos de indexación.
Mientras la ley lucha por ponerse al día con la tecnología, el futuro de los libros está en juego. ¿Están los escritores condenados por «el mayor robo en la historia creativa» o podría la IA ofrecer nuevas formas de ganarse la vida?
Cuando la autora R.O. Kwon se enteró de que su primera novela, The Incendiaries, formaba parte del conjunto de datos Books3 utilizados para entrenar modelos de IA generativa, se sintió violada. Ella y otros autores expresaron su indignación en las redes sociales contra las empresas tecnológicas que habían «monitoreado» internet para obtener datos sin el consentimiento ni compensación para los creadores. Los libros, que llevaron años de trabajo, fueron utilizados para enseñar a los modelos de IA a crear «nuevo» contenido.
Douglas Preston, un autor de best-sellers, describe esto como «el mayor robo en la historia creativa» y es uno de los demandantes en una denuncia colectiva presentada contra Microsoft y OpenAI. Los escritores alegan que estas empresas violaron la ley de derechos de autor al utilizar sus libros para entrenar modelos de IA. Las empresas tecnológicas argumentan que entrenar sus modelos con contenido protegido por derechos de autor es similar a que una persona lea libros para mejorar su escritura. La decisión podría depender de la definición de «uso justo» en la ley.
La industria editorial ya está cambiando debido a la IA generativa. Aunque algunas voces en la industria creen que la IA podría ofrecer nuevas oportunidades para los escritores, también existe el temor de que pueda desplazar el trabajo humano. Mary Rasenberger, CEO de Authors Guild, señala que la IA que puede reproducir contenido similar al que ingirió representa una amenaza existencial para la profesión de escritor y la industria editorial.
La encuesta más reciente de Authors Guild encontró que el ingreso medio de los autores en 2022 fue de solo 20.000$, lo que subraya la precariedad de la profesión. La plataforma Kindle Direct Publishing de Amazon ha permitido un auge en la autoedición, pero también ha facilitado la proliferación de libros falsos y de baja calidad. En respuesta a esto, Amazon ha impuesto un límite diario de tres libros para los autores en su plataforma.
La creación de contenido con IA es barata porque las empresas no están pagando por las fuentes de datos de alta calidad, como los libros. El punto de las demandas contra OpenAI y Microsoft es asegurar una compensación para el uso de los libros que ya fueron ingeridos y para futuras contribuciones. Algunos proponen un sistema de licencias inspirado en la industria de la música, pero su ejecución aún no está clara.
Empresas como Inkitt y Galatea están utilizando IA generativa para identificar contenido atractivo y publicarlo en capítulos que los lectores compran individualmente. Aunque estas innovaciones están cambiando la forma en que se crean y distribuyen los libros, también plantean serias preguntas sobre la sostenibilidad para los escritores y la integridad del proceso creativo.
En 2013, Ali Albazaz fundó Inkitt como una plataforma para compartir escritos entre amigos. Para 2019, la compañía lanzó Galatea, una aplicación que presenta la ficción más popular de Inkitt, habiendo acumulado más de 100,000 autores y un millón de usuarios. Albazaz y su equipo utilizaron una IA tradicional (no generativa) para analizar el comportamiento de los usuarios y identificar el contenido más atractivo, publicando luego esas novelas en Galatea en capítulos que los lectores compran individualmente. Jane Friedman, ex CEO de HarperCollins, se unió a la junta de la compañía en 2021.
Empresas de capital de riesgo, como Kleiner Perkins, NEA y Khosla Ventures, han invertido más de cien millones de dólares en la compañía que Albazaz describe como «el Disney del siglo XXI». Cada tres a cuatro semanas, la compañía tiene un nuevo éxito, definido por Albazaz como una novela que genera un millón de dólares en ventas. Galatea se centra actualmente en novelas de romance y fantasía, con planes de expandirse a otros géneros apoyados por Inkitt.
Con IA generativa, Galatea puede ofrecer versiones en audio de las historias existentes y permitir a los lectores personalizar las historias a su gusto. Esto incluye cambiar nombres de personajes o añadir tramas, similar a la fanfiction. Los autores originales reciben regalías por estas adaptaciones.
La plataforma ofrece a los autores la posibilidad de ganar dinero mediante suscripciones de los lectores en Inkitt, y regalías si sus libros llegan a Galatea. Los autores más exitosos han ganado cantidades significativas, como 36.000 dólares en tres meses y hasta 115.000 dólares en un mes.
Por otro lado, Sudowrite, fundada por James Yu y Amit Gupta en 2020, también utiliza IA generativa para ayudar a los escritores a crear y revisar sus obras. Sudowrite ha atraído a unos 15.000 usuarios de pago, principalmente novelistas. La empresa utiliza diversos modelos de IA, incluyendo GPT-3, y está desarrollando uno que se ajuste específicamente a la voz de cada escritor.
Las obras generadas por IA existen en una zona legal gris: no son susceptibles de derechos de autor, pero las obras asistidas por IA pueden serlo. Amazon requiere que los autores indiquen si sus libros son generados por IA, pero no si son asistidos por IA. La regulación de este ámbito está aún en desarrollo.
Las grandes editoriales están explorando el uso de la IA para mejorar la productividad y crear audiolibros traducidos, pero todavía no se interesan por utilizarla para escribir libros completos. Sin embargo, existe preocupación entre los escritores de que la proliferación de contenido generado por IA y la falta de compensación adecuada por el uso de su trabajo para entrenar modelos de IA puedan dificultarles aún más la vida.
La Asociación de Agentes Literarios de América sugiere que los autores incluyan cláusulas en sus contratos para proteger su trabajo del uso sin consentimiento en el entrenamiento de IA. Sin embargo, estas cláusulas no siempre son aceptadas por las editoriales.
El impacto de la IA generativa en el tipo de libros que se publican también es un tema de debate. La presión económica podría dificultar la inversión en obras más complejas y profundas, afectando no solo a los autores, sino también a los lectores y la cultura en general. La interpretación legal de «uso justo» y si estos modelos «transforman» el trabajo en el que se entrenan será crucial para el futuro de la IA en la literatura.
Chiarelli, A., Cox, E., Johnson, R., Waltman, L., Kaltenbrunner, W., Brasil, A., Reyes Elizondo, A., & Pinfield, S. (2024). «Towards Responsible Publishing»: Findings from a global stakeholder consultation. Zenodo. https://doi.org/10.5281/zenodo.11243942
Este informe detalla los resultados de una consulta global con la comunidad investigadora sobre la propuesta de “Towards Responsible Publishing” (TRP) («Hacia una Publicación Responsable»). La consulta, realizada por Research Consulting y el Centro de Estudios de Ciencia y Tecnología de la Universidad de Leiden (CWTS), involucró a más de 11,600 participantes de todo el mundo entre noviembre de 2023 y mayo de 2024. Los resultados muestran un amplio apoyo a los principios del TRP, como la publicación de preprints, la revisión por pares abierta y las licencias abiertas. Además, se destaca la necesidad de colaboración global para cambiar los mecanismos de reconocimiento y recompensa en la investigación y redirigir el gasto hacia prácticas más responsables.
Brundy, C., & Thornton, J. B. (2024). The paper mill crisis is a five-alarm fire for science: What can librarians do about it? Insights, 37(1). https://doi.org/10.1629/uksg.659
La crisis de las fábricas de artículos, que está contaminando la literatura académica con artículos falsos, ha llevado a un número récord de retracciones de artículos y continúa erosionando la confianza en la ciencia. Aunque los editores y otros interesados en la publicación académica se han movilizado para abordar esta grave amenaza a la integridad de la investigación y la publicación, la acción de la comunidad bibliotecaria ha sido insuficiente. Este artículo explora el impacto continuo de la crisis de las fábricas de artículos y sus causas. También revisa las medidas que se están tomando en todo el sector para abordarla. Esto incluye acciones emprendidas por editores, investigadores de integridad y organizaciones como Retraction Watch, NISO y STM. Basándose en la gravedad de la crisis y la respuesta actual, este artículo recomienda acciones que las bibliotecas pueden tomar para ayudar a abordar la crisis y limpiar el desorden que las fábricas de artículos han creado en la literatura académica. En un momento de creciente desconfianza y amenazas crecientes para la sociedad, es crucial que todos los interesados en la publicación académica, incluidos los bibliotecarios, ayuden a mantener la integridad de la publicación y restaurar la confianza en la ciencia.
Van Noorden, Richard. «Medicine Is Plagued by Untrustworthy Clinical Trials. How Many Studies Are Faked or Flawed?» Nature 619, n.o 7970 (18 de julio de 2023): 454-58. https://doi.org/10.1038/d41586-023-02299-w.
Las investigaciones sugieren que, en algunos campos, al menos una cuarta parte de los ensayos clínicos podrían ser problemáticos o incluso totalmente inventados, advierten algunos investigadores. Instan a un mayor escrutinio.
¿Cuántos estudios de ensayos clínicos publicados en revistas médicas son falsos o contienen errores fatales? En octubre de 2020, John Carlisle publicó una sorprendente estimación. El anestesista John Carlisle, conocido por detectar datos dudosos en ensayos médicos, revisó más de 500 estudios durante tres años y encontró que el 26% tenía problemas tan graves que no se podían confiar, lo que él llamó «ensayos zombis». Estos ensayos, que se asemejan a la investigación real pero son huecos, pueden pasar desapercibidos sin acceso a los datos individuales de los participantes.
Por ello, se sugiere que los editores de revistas revisen los datos de los participantes antes de publicar ensayos controlados aleatorios. La preocupación por la integridad de la investigación también se extiende a otras áreas médicas, como la salud de la mujer, la anestesiología y la COVID-19, donde se han encontrado numerosos ensayos sospechosos.
Los problemas con los ensayos falsificados o poco confiables plantean serias amenazas, ya que pueden influir en las decisiones médicas y distorsionar el conocimiento científico. Aunque se están realizando más estudios para evaluar la magnitud del problema, la detección y corrección de ensayos problemáticos sigue siendo un desafío importante para la comunidad científica.
Wiley cerró 19 revistas científicas a raíz de problemas con «fábricas de artículos» con inteligencia artificial. Estas revistas pertenecían a su subsidiaria Hindawi, centro de un escándalo de publicación académica.
En diciembre de 2023 Wiley anunció que dejaría de utilizar la marca Hindawi, adquirida en 2021, tras su decisión en mayo de 2023 de cerrar cuatro de sus revistas «para mitigar la manipulación sistemática del proceso de publicación» Se descubrió que las revistas de Hindawi estaban publicando artículos provenientes de «fábricas de artículos» (Papel Mills), organizaciones que intentan manipular el proceso de publicación académica con fines financieros. En respuesta a esto, Wiley ha retiró más de 11.300 artículos de su cartera de Hindawi. La preocupación por la integridad de la investigación académica no se limita a las publicaciones de Wiley, ya que estudios sugieren que hasta una cuarta parte de los ensayos clínicos pueden ser problemáticos o completamente fabricados.
Según un preprint publicado en febrero, el volumen de artículos enviados a ArXiv aumentó considerablemente en las tres categorías principales entre 2019 y 2023, un período que coincide aproximadamente con la puesta a disposición del público de herramientas como ChatGPT. Los artículos de ciencias de la computación aumentaron un 200 por ciento durante estos cuatro años, seguidos por los artículos de física (45 por ciento) y matemáticas (22 por ciento).
Como se describe en un libro blanco de Wiley publicado el pasado diciembre, «Tackling publication manipulation at scale: Hindawi’s journey and lessons for academic publishing», las fábricas de artículos recurren a diversas prácticas contrarias a la ética, como el uso de inteligencia artificial en la fabricación de manuscritos y la manipulación de imágenes, así como la manipulación del proceso de revisión por pares.
La creciente disponibilidad y sofisticación de la inteligencia artificial generativa está facilitando estas prácticas. Wiley ha implementado una nueva tecnología de detección para identificar artículos con posibles usos indebidos de la inteligencia artificial generativa antes de su publicación. «El sector reconoce que las editoriales utilizan la IA para generar contenidos fraudulentos», explica el portavoz de Wiley. «Recientemente hemos introducido una nueva tecnología de cribado que ayuda a identificar artículos con un potencial mal uso de la IA generativa antes del punto de publicación».
Las editoriales académicas, sin embargo, parecen apoyar los beneficios de la ayuda de la IA a la redacción sin sus inconvenientes. Springer Nature, por ejemplo, lanzó el pasado mes de octubre «Curie», un asistente de escritura basado en IA para ayudar a los científicos cuya lengua materna no es el inglés. De ahí las peticiones de mejores herramientas para detectar los resultados generativos de la IA, una petición a la que han respondido los recientes esfuerzos por mejorar la marca de agua de los contenidos de IA, que según algunos investigadores no funcionará.
Aunque Wiley caracterizó el cierre de las 19 revistas como parte de su plan anunciado previamente para integrar las carteras de Hindawi y Wiley, y distinto del problema de las fábricas de artículos, este incidente destaca los desafíos en la integridad de la investigación académica frente a la proliferación de prácticas fraudulentas facilitadas por la inteligencia artificial.
Mientras tanto, el informe de ganancias del tercer trimestre fiscal de 2024 de Wiley, el editor indicó que se anticipa que los ingresos de su división de aprendizaje se sitúen en el extremo superior de las proyecciones, debido a «acuerdos de derechos de contenido del cuarto trimestre para el entrenamiento de modelos de IA».
Steele, Evie. «Chinese Government Cracks Down on Academic Fraud.» Voice of America, March 11, 2024. https://flip.it/qVLrXn.
China está intensificando su lucha contra el fraude en la investigación académica tras revelaciones en enero de que editoriales habían retractado miles de trabajos de académicos chinos en los últimos años. Sin embargo, observadores señalan que abordar este problema será difícil debido a su amplia prevalencia.
Según la revista científica Nature, en 2023 se retractaron aproximadamente 14.000 artículos de revistas en inglés, tres cuartas partes de los cuales tenían coautores chinos. El Ministerio de Educación de China ha exigido a las universidades que presenten una lista completa de artículos académicos retractados en los últimos tres años para auditar el alcance del fraude.
Aunque los resultados de la revisión del Ministerio de Educación aún no se han publicado, académicos y estudiantes chinos afirman que el problema es generalizado. Parte del problema radica en la facilidad con la que se puede pagar a escritores fantasma para que realicen investigaciones y publiquen en revistas de baja calidad. Sun Fugui, exestudiante de posgrado en la Universidad de Ludong, comentó que tanto estudiantes como profesores utilizan estos servicios.
Otro problema es que las revistas científicas chinas de bajo nivel frecuentemente publican investigaciones fraudulentas sin verificar su calidad. Yang Ningyuan, exdirector de un instituto de investigación en la Universidad de Zhengzhou, mencionó que ha recibido numerosas ofertas para publicar artículos a cambio de dinero.
Analistas creen que la naturaleza política de la investigación en China es en parte responsable de los problemas de integridad académica. Yun Sun, del think tank Stimson Center, señaló que la transparencia y libertad en los intercambios académicos están fuertemente controladas por el estado en China, lo que dificulta la verificación de datos fabricados.
Perry Link, profesor en la Universidad de California, Riverside, comentó que el volumen de investigaciones fabricadas refleja la indiferencia de los funcionarios hacia la verdad. La intervención política en la investigación también desanima a los investigadores a producir trabajos de alta calidad.
Zhang Mingxin, un estudiante universitario en Beijing, mencionó que el fraude académico y la politización de los datos hacen que la investigación sea muy difícil. La estricta censura gubernamental complica la búsqueda de datos, especialmente en temas sensibles.
Yun Sun concluyó que las universidades chinas quedarán rezagadas respecto a otras universidades globales debido a sus problemas de integridad académica no resueltos. El Ministerio de Educación aún no ha presentado un plan para abordar estas preocupaciones.
Hosseini, Mohammad, y David B Resnik. «Guidance Needed for Using Artificial Intelligence to Screen Journal Submissions for Misconduct». Research Ethics, 11 de mayo de 2024, 17470161241254052. https://doi.org/10.1177/17470161241254052.
Las revistas y editoriales están utilizando cada vez más la inteligencia artificial (IA) para examinar las presentaciones en busca de posibles conductas impropias, incluido el plagio y la manipulación de datos o imágenes.
Si bien el uso de la IA puede mejorar la integridad de los manuscritos publicados, también puede aumentar el riesgo de acusaciones falsas/no fundamentadas. Las ambigüedades relacionadas con las responsabilidades de las revistas y editoriales con respecto a la equidad y transparencia también plantean preocupaciones éticas.
En el presente artículo, se proporciona la siguiente guía:
Todos los casos de conducta impropia sospechosa identificados por herramientas de IA deben ser revisados cuidadosamente por humanos para verificar la precisión y garantizar la responsabilidad;
Las revistas/editoriales que utilizan herramientas de IA para detectar conductas impropias deben utilizar solo herramientas bien probadas y confiables, permanecer vigilantes con respecto a formas de conducta impropia que no pueden ser detectadas por estas herramientas y mantenerse al tanto de los avances en tecnología;
Las revistas/editoriales deben informar a los autores sobre irregularidades identificadas por herramientas de IA y darles la oportunidad de responder antes de enviar acusaciones a sus instituciones de acuerdo con las pautas del Comité de Ética de Publicaciones;
Las revistas/editoriales que utilizan herramientas de IA para detectar conductas impropias deben examinar todas las presentaciones relevantes y no solo presentaciones seleccionadas al azar/intencionalmente; y
Las revistas deben informar a los autores sobre su definición de conducta impropia, su uso de herramientas de IA para detectar conductas impropias y sus políticas y procedimientos para responder a casos sospechosos de conducta impropia.
TikTok ha anunciado que comenzará a etiquetar contenido creado utilizando inteligencia artificial cuando se cargue desde fuera de su propia plataforma, como parte de su esfuerzo para combatir la desinformación.
La compañía afirma que si bien la IA ofrece oportunidades creativas increíbles, puede confundir o engañar a los espectadores si no saben que el contenido fue generado por IA. Por lo tanto, la etiqueta ayudará a proporcionar claridad sobre el origen del contenido. TikTok ya etiqueta contenido generado por IA creado con efectos de IA de TikTok, y ha requerido a los creadores que etiqueten contenido realista generado por IA durante más de un año.
Esta medida de TikTok forma parte de un esfuerzo más amplio en la industria tecnológica para proporcionar más salvaguardias para el uso de la IA. Meta anunció en febrero que estaba trabajando con socios de la industria en estándares técnicos que facilitarán la identificación de imágenes y, eventualmente, videos y audio generados por herramientas de inteligencia artificial. Los usuarios de Facebook e Instagram verían etiquetas en imágenes generadas por IA. Google también anunció el año pasado que las etiquetas de IA llegarían a YouTube y otras plataformas.
Este impulso hacia el «marcado de agua digital» y la etiquetación del contenido generado por IA también fue parte de una orden ejecutiva que el presidente de Estados Unidos, Joe Biden, firmó en octubre.
TikTok espera que esta medida ayude a fortalecer la confianza del usuario y a reducir la propagación de desinformación en su plataforma.