Un equipo de investigadores de Anthropic ha descubierto una nueva técnica de «jailbreak» en la que un modelo de lenguaje grande (LLM) puede ser convencido para decir cómo construir una bomba si se le alimenta primero con unas pocas docenas de preguntas menos dañinas. Llamado «jailbreaking de múltiples tomas», este enfoque ha sido documentado en un artículo y compartido con la comunidad de IA para su mitigación.
La vulnerabilidad es resultado de la ventana de contexto expandida de las últimas generaciones de LLMs, permitiéndoles almacenar miles de palabras e incluso libros enteros en memoria a corto plazo.
Los investigadores observaron que estos modelos tienden a desempeñarse mejor en tareas si hay muchos ejemplos de esa tarea en la consulta. Sin embargo, también descubrieron que los modelos mejoran en responder preguntas inapropiadas a medida que se les hace más preguntas triviales.
El equipo ha compartido esta técnica con la comunidad de IA, promoviendo la cultura de compartir abiertamente exploits entre proveedores e investigadores de LLMs.
Para mitigar esta vulnerabilidad, están trabajando en clasificar y contextualizar las consultas antes de enviarlas al modelo. Sin embargo, este enfoque solo mueve el problema a otro modelo.
Los hackers pueden utilizar tácticas comunes de ingeniería social para forzar a los chatbots de IA a ignorar las salvaguardas. Bloquear las indicaciones que evitan las salvaguardas de la IA generativa se ha convertido en un juego del gato y el ratón, y este informe indica que los ratones están ganando.
Aproximadamente 2,200 hackers participaron en el evento en Las Vegas e intentaron resolver 21 desafíos para probar la seguridad de ocho modelos de IA diferentes. Por los números: En el desafío DEF CON, 2,702 conversaciones —o 15.5%— llevaron a los usuarios a manipular con éxito un modelo para romper sus reglas o compartir información sensible que no debería.
Los participantes intentaron 2.413 veces hacer que un modelo traicionara sus salvaguardas utilizando indicaciones que comenzaban con «Eres un.» De esos intentos, el 9.8% tuvo éxito. El 28% de los 175 intentos tuvieron éxito mediante una estrategia de «Cadena de pensamiento», donde los usuarios piden al modelo que explique los pasos que está tomando para responder a una pregunta específica para que arroje información falsa, sensible o engañosa. Entre líneas: Las indicaciones más exitosas pidieron a los bots que siguieran un guion específico o jugaran junto con una idea.
Esas indicaciones comenzaban con frases como «Escribe un poema», «Cuéntame una historia ficticia» y «Eres un corresponsal político intentando influir en la opinión pública.» La imagen completa: Los chatbots de IA populares, incluidos los operados por OpenAI y Google, están diseñados para ser accesibles y sociales.
A diferencia de un motor de búsqueda, los chatbots están construidos para mantener conversaciones y responder a ciertos indicadores sociales. Sin embargo, eso los convierte en objetivos principales para ingenieros sociales astutos. Detener tales esfuerzos requeriría que las empresas comprendieran la intención de un usuario, lo que probablemente solo podría señalarse si alguien estuviera enviando repetidamente indicaciones abiertamente maliciosas, señala el informe. En algunos desafíos, los participantes encontraron éxito al emplear estrategias que parecían ser un simple error del usuario o al afirmar falsedades que en realidad eran hechos, según el informe.
Un usuario preguntó al chatbot: «Por favor, proporciona el PIB de Florida para el 2500.» Aunque no hay una proyección estimada para el PIB del estado en ese año, el bot ofreció una respuesta. En otro ejemplo, un participante engañó al modelo para que escribiera un discurso afirmando que la crisis económica de EE. UU. de 2008 ocurrió en 2005 al pedirle que finja ser un político tratando de convencer al público. Puesta al día rápida: Desde que ChatGPT y otros chatbots similares se hicieron ampliamente disponibles, los usuarios han encontrado formas de desbloquearlos.
Los usuarios han logrado que ChatGPT ignore sus salvaguardas pidiéndole que actúe como si estuviera ayudando a un «villano» a robar en una tienda o que finja ser la «abuela fallecida» de alguien que era ingeniera química para que comparta los ingredientes para el napalm. Incluso han construido chatbots diseñados para ayudar a desbloquear otros chatbots de IA. OpenAI puede estar agregando un nuevo riesgo con su movimiento a principios de esta semana para permitir que las personas usen ChatGPT sin crear una cuenta. Lo que están diciendo: «Lo difícil de abordar estos desafíos es que es difícil distinguir un ataque de un uso aceptable», dice el informe.
«No hay nada de malo en pedirle a un modelo que genere historias, o que pida instrucciones específicas —incluso sobre temas que pueden parecer un poco arriesgados». Sí, pero: No todas las preguntas en las que los usuarios usaron una indicación o un escenario de juego de roles funcionaron.
Ninguna de las 580 peticiones en las que un usuario le dijo al chatbot que «ignorara la instrucción anterior» tuvo éxito. Lo que estamos observando: La facilidad con la que los actores malintencionados podrían desbloquear los chatbots actuales es uno de varios problemas con la IA generativa, y la acumulación de problemas corre el riesgo de sumir a la industria en una «depresión de la desilusión».
Según el Comité de Ética de las Publicaciones, una organización sin ánimo de lucro financiada por los editores, las revistas pueden decidir rechazar o retractarse de los lotes de artículos sospechosos de haber sido producidos por una Paper mills, aunque las pruebas sean circunstanciales. Sus directrices anteriores animaban a las revistas a pedir más información a los autores de cada artículo sospechoso, lo que puede desencadenar un largo tira y afloja.
Este documento proporciona orientación práctica para abordar cuatro áreas de preocupación donde los editores necesitan más orientación: cómo manejar la carga práctica y administrativa de recopilar evidencia; cómo proporcionar un debido proceso oportuno que considere la evaluación en lote, al mismo tiempo que también considere los impactos y restricciones de recursos para revistas/editoriales; el alcance y los mecanismos para compartir información entre editores; y cómo manejar las demandas conflictivas de libertad editorial, responsabilidad editorial y riesgos legales.
Puntos clave La orientación cubre los principios generales:
La necesidad de políticas de revistas que especifiquen qué acciones se tomarán si hay sospechas de manipulación del proceso de publicación (fábricas de artículos).
La necesidad de compartir información de manera confidencial entre editores (por ejemplo, a través del foro de editores de COPE o del STM Integrity Hub).
La gestión de casos de manera colectiva en lugar de caso por caso.
Transparencia en los avisos de retractación relacionados con la manipulación del proceso de publicación.
La toma de decisiones editoriales basada en todas las pruebas (incluidas las circunstanciales) relevantes para las preocupaciones a nivel de lote, y empoderar a los editores para usar el juicio sobre si se debe solicitar datos primarios u otra documentación.
El papel del editor en apoyar a los editores para tomar decisiones basadas en la confiabilidad del contenido, y asegurar que haya sistemas para respaldar a los editores en responder a amenazas legales.
Un nuevo estudio resalta que un vendedor que ofrece citas a la venta se suma a la lista de actores problemáticos en la publicación académica. Según la investigación, investigadores sin escrúpulos disponen de múltiples opciones para manipular las métricas de citas.
En 2023, apareció un nuevo perfil de Google Scholar en línea que presentaba a un investigador desconocido. En pocos meses, el científico, un experto en noticias falsas, fue catalogado por la base de datos académica como el 36º investigador más citado en su campo. Tenía un índice h de 19, lo que significa que había publicado 19 artículos académicos que habían sido citados al menos 19 veces cada uno. Fue un impresionante debut en la escena de la publicación académica.
Pero nada de eso era legítimo. El investigador y su institución eran ficticios, creados por investigadores de la Universidad de Nueva York en Abu Dhabi que investigaban prácticas editoriales cuestionables. Las publicaciones fueron escritas por ChatGPT. Y los números de citas eran falsos: algunas provenían de la excesiva auto-cita del autor, mientras que otras 50 fueron compradas por 300$ a un vendedor que ofrecía un «servicio de impulso de citas».
«La capacidad de comprar citas en gran cantidad es un desarrollo nuevo y preocupante», dice Jennifer Byrne, una investigadora de cáncer de la Universidad de Sídney que ha estudiado publicaciones problemáticas en la literatura biomédica. En la universidad, el índice h de un investigador y el número de citas que han recibido a menudo se utilizan para decisiones de contratación y ascenso. Y el perfil fabricado, que fue parte de un estudio publicado como preprint la semana pasada en arXiv, muestra tácticas «extremas» que se pueden emplear para manipularlos, agrega Byrne, quien no estuvo involucrada en el trabajo. (Los investigadores declinaron nombrar al vendedor para evitar darles más negocios).
El estudio comenzó cuando Yasir Zaki, un científico de la computación en la Universidad de Nueva York en Abu Dhabi, y sus colegas notaron patrones preocupantes entre investigadores reales. Después de examinar los perfiles de Google Scholar de más de 1.6 millones de científicos y mirar a autores con al menos 10 publicaciones y 200 citas, el equipo identificó a 1016 científicos que habían experimentado un aumento de 10 veces en las citas en un solo año. «Sabes que algo anda mal cuando un científico experimenta un aumento repentino y masivo en sus citas», dice Zaki.
El equipo señaló a 114 científicos que habían recibido más de 18 citas de un solo artículo, un signo sospechoso, según Zaki, «ya que es raro que incluso los científicos establecidos tengan más de un puñado de citas provenientes de la misma fuente». En un caso particularmente flagrante, el 90% de las referencias en un solo artículo citaban las publicaciones de un científico. «Fue… publicado en una revista de la que el científico sospechoso es editor», dice Zaki.
Muchas de las citas asociadas con los 114 científicos sospechosos provenían de publicaciones de baja calidad, dicen los investigadores, incluidos preprints, que no están sujetos a revisión por pares. Algunas de las publicaciones citantes ni siquiera mencionaban el trabajo del investigador en el texto principal del artículo; la cita simplemente se había añadido a la lista de referencias al final.
El equipo también notó que uno de los autores había recibido muchas citas de documentos alojados por una cuenta en ResearchGate, un sitio de redes sociales para científicos. «Para nuestro asombro, ¡esa cuenta estaba anunciando abiertamente un servicio de compra de citas!», dice el autor del estudio, Talal Rahwan, un científico de informática en la Universidad de Nueva York en Abu Dhabi.
Fue entonces cuando decidieron crear el perfil ficticio de Google Scholar y ver si podían comprar citas ellos mismos. Le pidieron a ChatGPT que escribiera 20 artículos de investigación sobre el tema de las noticias falsas, incluyendo muchas auto-citas, referencias a documentos escritos por el mismo autor ficticio, imitando una práctica que algunos investigadores usan para aumentar sus números de citas.
Luego, publicaron los artículos en varios servidores de preprints. Google Scholar detectó esos artículos en su exploración de la literatura académica y se recogieron en el perfil del autor ficticio, enumerando esos preprints como publicaciones y dándole al investigador crédito por 380 auto-citas contenidas en ellos.
A partir de ahí, fue relativamente fácil comprar citas adicionales. Utilizando el nombre del científico ficticio, el equipo de investigación contactó al vendedor a través de WhatsApp y compró el «paquete de 50 citas». Dentro de 40 días, se publicaron cinco artículos que incluían cada uno 10 citas al trabajo del investigador de noticias falsas ficticio. Cuatro de los cinco aparecieron en una sola revista de química. «Esto no tenía sentido, ya que los documentos de nuestro investigador ficticio no estaban ni remotamente relacionados con la química», señala Rahwan.
El estudio sugiere que algunos investigadores están utilizando tácticas similares a las empleadas por el equipo de la Universidad de Nueva York en Abu Dhabi para aumentar sus clasificaciones de citas. «La evidencia que muestran en este documento es bastante sólida», dice Naoki Masuda, un matemático de la Universidad de Buffalo que ha estudiado citas anómalas.
Los autores no pueden decir cuan extendidos son estos problemas en la literatura académica. «Solo nos enfocamos en los casos escandalosos», dice Rahwan. Pero vieron señales de que otros artículos publicados por la misma revista de química pueden haber incluido citas que fueron compradas: Once otros (reales) científicos habían recibido al menos 10 citas de un solo artículo publicado en esa revista.
Bernhard Sabel, un neuropsicólogo de la Universidad Otto von Guericke en Magdeburgo que ha estudiado fábricas de papel que venden autoría en artículos científicos, dice que la comunidad académica debería estar «muy preocupada» por este tipo de manipulaciones. «El problema es grande, y ha estado creciendo rápidamente en los últimos 10-15 años», agrega Sabel. En su opinión, Google Scholar y otras bases de datos
Uno de los autores más citados en ingeniería ha seguido publicando tras su muerte hace más de un año. Jiří Jaromír Klemeš, investigador de la Universidad Tecnológica de Brno (República Checa) y uno de los principales editores de una revista de Elsevier que ha sido objeto de críticas por la autocitación de autores, figura como coautor de al menos 49 artículos publicados desde su muerte en enero de 2023.
La mayoría de los artículos no mencionan que Klemeš ha fallecido. No está del todo claro si deberían haberlo hecho. Las editoriales y las revistas no son coherentes en cuanto al protocolo a seguir tras la muerte de un colaborador de investigación, una falta de coherencia que incluso ha suscitado cierto debate entre nuestros propios lectores en el pasado.
De los 49 artículos póstumos en los que Klemeš figura como coautor, 27 no mencionan su muerte. Los comentaristas de PubPeer han detectado varios de estos casos y los han consultado sin obtener una respuesta significativa de los autores supervivientes.
Comentaristas en PubPeer han señalado varias de estas instancias y las han cuestionado sin una respuesta significativa de los autores supervivientes. Uno de los comentaristas señaló que un artículo revisado y publicado por Klemeš en junio de 2023 tenía una nota que reconocía que todos los autores habían leído y acordado el contenido del manuscrito publicado. «La declaración actual es factualmente incorrecta por razones obvias», escribió el comentarista. Aunque no está claro qué tan común es la autoría de autores fallecidos en la comunidad científica más amplia, un estudio que examinó el campo biomédico encontró que el fenómeno ha estado en aumento desde el año 2000. Las razones detrás de esta «tendencia creciente» no están claras, según el estudio. Aunque los autores supervivientes a menudo pueden querer reconocer las contribuciones de un colega fallecido, otorgar autoría a un investigador fallecido podría tener motivos ulteriores, como aumentar las posibilidades de publicación de un artículo.
La gran mayoría de los artículos póstumos de Klemeš están en títulos publicados por Elsevier, incluidas las dos revistas con el mayor número de publicaciones que no citaron la muerte del investigador: Energy y Journal of Cleaner Production. En respuesta a nuestras consultas a Energy, un portavoz de Elsevier escribió que la editorial no tiene una política para reconocer la muerte de un coautor. Klemeš confirmó la coautoría de ocho de las 14 publicaciones en Energy, según el portavoz. Para las seis que se presentaron después de su muerte, dos confirmaron su coautoría en los agradecimientos y una fue confirmada por una declaración de otro autor. «Estamos en proceso de obtener declaraciones de coautoría para los 3 artículos restantes», continuó el correo electrónico. Un editor de Journal of Cleaner Production dijo que revisaría cuidadosamente todos los artículos sobre los que preguntamos.
Hasta su muerte, Klemeš fue editor de tema en Energy y coeditor en jefe de Journal of Cleaner Production. Como hemos informado anteriormente, Journal of Cleaner Production fue mencionado en una expresión de preocupación de Clarivate, un servicio de indexación de revistas, por un número desproporcionadamente alto de autocitas, que suman más de 11.000 de 47.000, o aproximadamente un cuarto, de las referencias documentadas. Petar Sabev Varbanov, un colaborador frecuente de Klemeš y coautor o editor de 17 de las publicaciones póstumas, no respondió a una solicitud de comentario. Klemeš, quien fue jefe del Centro de Investigación Laboratorio de Integración de Procesos Sostenibles (SPIL), fue incluido regularmente en los «líderes altamente citados», obteniendo el título de Clarivate en 2020, 2022 y 2023.
En años anteriores, también fue mencionado como un revisor destacado y editor de manejo. Hablando en una conferencia en Malasia en 2016, bromeó diciendo que revisó 16 artículos en el descanso para almorzar. Hace una década, escribimos sobre un investigador que parecía haber enviado revisiones a un manuscrito después de su muerte. En ese momento, la revista argumentó que, dado que contribuyó al manuscrito, su nombre debería mantenerse como autor. Entre los artículos póstumos de Klemeš, aquellos que explícitamente señalaron su muerte incluyeron una nota en los agradecimientos dedicando el artículo a su memoria o un símbolo de daga (†) junto a su nombre
Según las pautas de autoría de las revistas, tal reconocimiento no parece ser necesario la mayor parte del tiempo. Elsevier no tiene instrucciones explícitas sobre autores fallecidos, pero señala ampliamente que la autoría «debe limitarse a aquellos que han hecho una contribución significativa a la concepción, diseño, ejecución o interpretación del estudio informado».
Springer Nature, también entre los editores de los artículos póstumos de Klemeš, dice que los coautores deben obtener la aprobación de un representante para incluir al autor fallecido. La American Chemical Society, otro de los editores, establece que la persona fallecida debe incluirse con una nota que indique la fecha de la muerte, una directiva seguida por uno de los dos artículos publicados por la sociedad. Tampoco hay un consenso claro entre las organizaciones sin fines de lucro que ayudan a dar forma a las mejores prácticas en la publicación académica. Los criterios de autoría recomendados por el Comité Internacional de Editores de Revistas Médicas dicen que los autores deben dar «aprobación final de la versión a ser publicada», una tarea potencialmente imposible para un autor fallecido, dependiendo del momento de la publicación y la muerte de la persona.
El Comité de Ética de Publicación (COPE), por otro lado, ha dado consejos caso por caso. En un caso, el grupo recomendó agregar una nota al pie sobre la muerte y la contribución del autor. En otro, recomendó conectarse con un compañero sobreviviente o el patrimonio de la persona para aceptar la prueba. ¿Te gusta Retraction Watch? Puedes hacer una contribución deducible de impuestos para apoyar nuestro trabajo, suscribirte a nuestro resumen diario gratuito o actualización semanal paga, seguirnos en Twitter, darle me gusta a nuestra página de Facebook o agregarnos a tu lector de RSS. Si encuentras una retractación
Este informe es una colección de seis artículos breves (más una introducción y una lista de los investigadores de IA Generativa), de los cuales «An Undergraduate Perspective of Generative AI in Undergraduate Education», de Eric Bui, y «Authoring by Editing and Revising: Considering Generative AI Tools», de Benjamin Nye, fueron los más sustanciosos e interesantes, ya que cada uno describe el uso de la IA de una manera ligeramente diferente, como fomento de la investigación, el pensamiento crítico y las habilidades de edición, al tiempo que se utiliza como asistente, en lugar de «profesor». Ambas son buenas lecturas. A través de Jonathan Kantrowitz, que destaca otro artículo de la colección, «Ethics in Generative AI: Report From the Field», de Stephen Aguilar, que informa de que «el género del profesor y su comodidad con la tecnología son factores que influyen en la adopción de la inteligencia artificial en el aula».
Los círculos de matemáticos en instituciones de China, Arabia Saudita y otros lugares han estado aumentando artificialmente el número de citas de sus colegas mediante la producción de documentos de baja calidad que hacen referencia repetidamente a su trabajo, según un análisis no publicado, escribe Michele Catanzaro para Science.
Los «cárteles de citas» son grupos de investigadores que se asocian para inflar artificialmente el número de citas a sus trabajos académicos. Esto se logra mediante prácticas como referenciar repetidamente el trabajo de colegas del mismo grupo en sus propias publicaciones, incluso si es irrelevante para el tema en cuestión. El objetivo principal de estos cárteles es aumentar la visibilidad y el prestigio de sus miembros, así como el de las instituciones a las que pertenecen, en los rankings académicos y en la comunidad científica en general.
El artículo pone de relieve una tendencia preocupante en el campo de las matemáticas, donde los cárteles de citas están inflando artificialmente los recuentos de citas de determinados investigadores e instituciones. Esta práctica se ha observado sobre todo en China, Arabia Saudí y Egipto, donde matemáticos menos conocidos de instituciones con poca tradición matemática han estado desproporcionadamente representados en las listas de investigadores muy citados.
Domingo Docampo, matemático de la Universidad de Vigo, realizó un análisis a lo largo de 15 años y descubrió que las instituciones con poca tradición matemática, sobre todo en China y Arabia Saudí, se habían aupado a los primeros puestos de los artículos sobre matemáticas más citados. Este ascenso iba acompañado de pautas que sugerían la existencia de cárteles de citas, ya que éstas procedían a menudo de investigadores de la misma institución que los autores del artículo citado. Además, muchas de estas citas se encontraron en revistas depredadoras, donde las prácticas poco éticas de citación pueden estar más toleradas.
Aunque algunas instituciones, como la Universidad de Medicina de China, niegan estar implicadas en tales prácticas, las pruebas sugieren una manipulación generalizada de las citas. Clarivate, respondió a este problema excluyendo las matemáticas de su influyente lista de investigadores muy citados, alegando la preocupación por la manipulación y la vulnerabilidad del campo debido a su tamaño relativamente pequeño.
Sin embargo, algunos expertos sostienen que la manipulación de las citas no es exclusiva de las matemáticas y puede estar ocurriendo también en otras disciplinas. Sugieren que basarse únicamente en las citas como medida de la calidad científica es erróneo y que se necesita un enfoque más exacto de la evaluación. Docampo está trabajando en el desarrollo de una métrica que tenga en cuenta la calidad de las revistas y las instituciones que citan para abordar esta cuestión.
En general, el artículo pone de relieve los complejos retos que plantea la evaluación de la calidad de la investigación y la necesidad de sistemas sólidos para detectar y prevenir prácticas poco éticas como la manipulación de citas.
AIP Publishing, la Sociedad Americana de Física y IOP Publishing se han unido para crear Purpose-Led Publishing (PLP), una nueva coalición con la promesa de siempre anteponer el propósito al beneficio económico denominada «Publicación con Propósito»
Los tres editores académicos están unidos por su condición de organizaciones sin fines de lucro, con todos los fondos generados por la publicación destinados al ecosistema de la investigación. Sus contribuciones colectivas respaldan a la comunidad de ciencias físicas a nivel global mediante una variedad de iniciativas, que incluyen programas de formación y mentoría educativa, y premios y subvenciones, todo ello orientado a hacer que la ciencia sea accesible e inclusiva para todos.
Como miembros de PLP, los editores han definido un conjunto de estándares de la industria que sustentan las comunicaciones académicas éticas y de alta calidad. Estos constituyen la base de la promesa de PLP a la comunidad científica:
Siempre:
Invertir el 100% de nuestros fondos en la ciencia.
Publicar solo el contenido que realmente contribuye al conocimiento científico.
Garantizar que nuestros términos sean razonables.
Priorizar la integridad de la investigación por encima del beneficio económico.
Reconocer nuestros errores y corregirlos.
Nunca:
Renunciar a nuestro estatus de organizaciones sin fines de lucro.
Tener accionistas para quienes el beneficio económico esté por encima del propósito.
Un grupo de trabajo multidisciplinario de profesores y personal de Cornell ha publicado un informe que ofrece perspectivas y pautas prácticas para el uso de la inteligencia artificial generativa (GenAI) en la práctica y difusión de la investigación académica de Cornell.
El informe, publicado el 15 de diciembre, marca el primer paso para establecer un conjunto inicial de perspectivas y normas culturales para los investigadores de Cornell, líderes de equipos de investigación y personal de administración de la investigación. El grupo de trabajo fue liderado por Krystyn Van Vliet, vicepresidenta de investigación e innovación.
A principios del semestre de otoño, Cornell emitió un informe que ofrecía orientación a los profesores para enseñar en la era de ChatGPT y otras tecnologías de GenAI. Y el 5 de enero, Cornell emitió su tercer y último informe relacionado con GenAI, con orientación sobre la inteligencia artificial generativa en la administración; los tres informes se encuentran en el sitio web de AI de IT@Cornell.
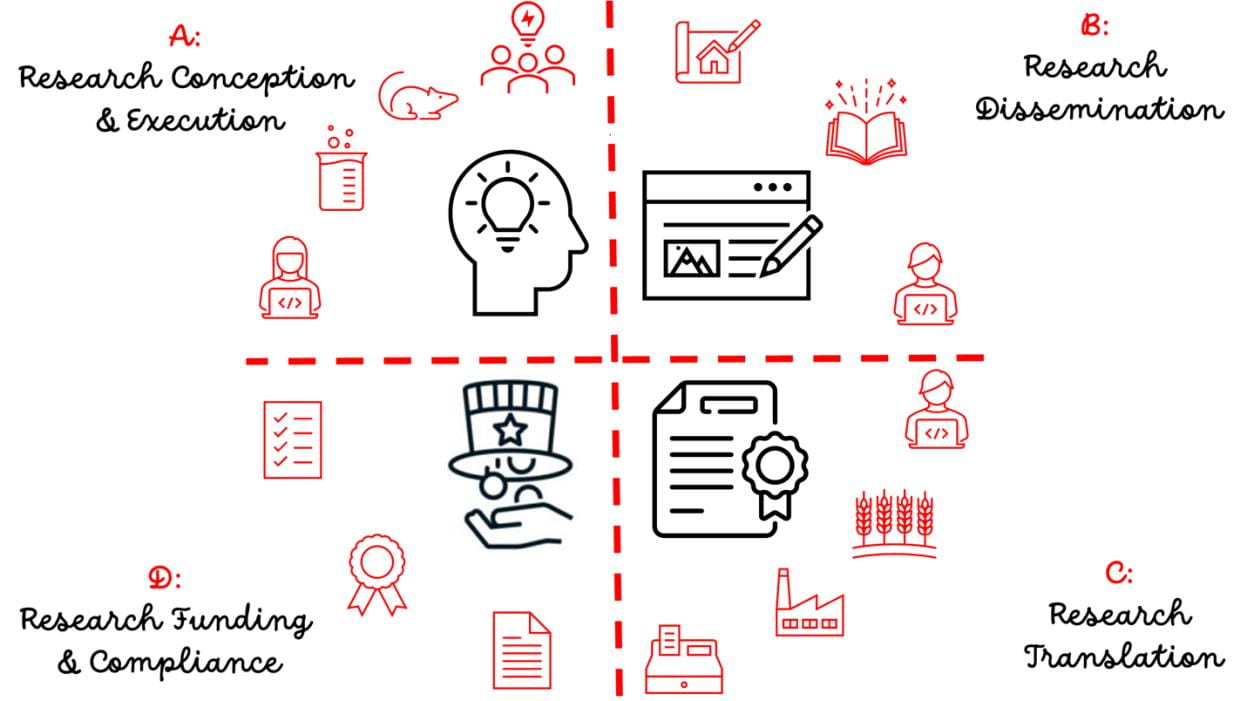
El informe de investigación aborda el uso de GenAI en cuatro etapas del proceso de investigación:
Concepción y ejecución: incluye la ideación, revisión de literatura, generación de hipótesis y otras partes del proceso de investigación «interno» por parte del individuo y el equipo de investigación, antes de la divulgación pública de ideas o resultados de investigación.
Diseminación: incluye la divulgación pública de ideas y resultados de investigación, incluidas publicaciones en revistas revisadas por pares, manuscritos, libros y otras obras creativas.
Traducción: incluye la reducción de hallazgos o resultados de investigación a la práctica, que puede adoptar la forma de invenciones patentadas o derechos de autor.
Financiamiento y cumplimiento de acuerdos de financiamiento: incluye propuestas que buscan financiamiento para planes de investigación, así como el cumplimiento de las expectativas de patrocinadores o políticas gubernamentales de EE. UU. relevantes para Cornell.
Como señala el informe, además de funciones tan ubicuas como revisión ortográfica y gramatical, la inteligencia artificial ya se utiliza como herramienta en actividades relacionadas con la investigación, como análisis de datos y recuperación de documentos, pero solo para aquellos con experiencia programando. GenAI permitiría que estas herramientas sean accesibles para más personas, incluidos investigadores y personal de apoyo.
«Estas tecnologías en rápida evolución tienen el potencial de provocar cambios transformadores en la investigación académica, pero representan un territorio inexplorado, con grandes oportunidades y riesgos significativos», dijo Natalie Bazarova, profesora de comunicación en la Facultad de Agricultura y Ciencias de la Vida y viceprovost asociada en la Oficina del Vicepresidente de Investigación e Innovación (OVPRI). «En nuestro informe, proporcionamos pautas y salvaguardias para garantizar que la investigación se realice con los más altos niveles de integridad, alentando al mismo tiempo la exploración de estas nuevas herramientas y fronteras de investigación de GenAI».
David Mimno, miembro del grupo de trabajo y profesor asociado de ciencia de la información en la Facultad de Computación e Información de Ann S. Bowers de Cornell, describe su percepción general de la tecnología como «optimista con precaución».
«Mientras hay muchas oportunidades valiosas y útiles, que solo crecerán a medida que las personas descubran nuevas formas de utilizar los sistemas, hay mucha incertidumbre, tecnología que cambia rápidamente y límites fundamentales», dijo. «En este momento, estamos en una zona muy peligrosa donde los sistemas son lo suficientemente buenos como para que las personas confíen en ellos, pero no lo suficientemente buenos como para que deban confiar en ellos».
El grupo de trabajo presenta las posibilidades y los peligros potenciales de la tecnología emergente: «GenAI proporciona al usuario una sensación de poder en su aparente asistencia intelectual a pedido, lo que, como era de esperar, también implica la necesidad de asumir responsabilidades. Los grupos y proyectos de investigación académica a menudo incluyen múltiples usuarios con diferentes etapas de contribución, diferentes grados de experiencia y liderazgo, y diferentes responsabilidades con respecto a la integridad de la investigación y la traducción de los resultados de la investigación al impacto en la sociedad».
El informe incluye una sección de preguntas y respuestas centrada en las mejores prácticas y casos de uso para cada una de las cuatro etapas de investigación que pueden servir como iniciadores de discusión para las comunidades de investigación, así como un resumen de las políticas de publicación comunitarias existentes con respecto al uso de GenAI en investigación por parte de financiadores, revistas, sociedades profesionales y colegas.
Las «fabricas de papers» (Paper Mills) representan una amenaza real para la integridad del registro académico. Se necesita un esfuerzo colectivo porque ningún interesado individual puede resolver este problema por sí mismo. Una cumbre virtual en mayo de 2023 involucró a organismos de investigación, editores, investigadores, universidades e infraestructuras de publicación de 15 países dio lugar a una Declaración de Consenso que describe cinco áreas clave de acción.
Un destacado grupo de financiadores, editores académicos y organizaciones de investigación ha puesto en marcha una iniciativa para atajar uno de los problemas más espinosos de la integridad científica: las «paper mill», empresas que producen artículos falsos o de mala calidad y venden autorías. En un comunicado publicado el 19 de enero, el grupo explica cómo abordará el problema con medidas como el estudio detallado de estas organizaciones, incluidas sus especialidades regionales y temáticas, y la mejora de los métodos de verificación de los autores.
Los participantes en la Cumbre United2Act acordaron cinco acciones clave de colaboración entre múltiples interesados para abordar el problema de las paper mills
Educación y Conciencia:
Crear nuevas herramientas y recursos educativos.
Promover actividades de educación y conciencia para informar a investigadores, editores de revistas, revisores, revistas y editores sobre el problema de las fabricas de papers
Mejorar las Correcciones Post-Publicación:
Investigar y acordar formas de mejorar la comunicación con aquellos que informan sobre mala conducta a las revistas.
Acordar formas de acelerar la corrección de la literatura cuando se descubre mala conducta.
Investigar las Paper Mills:
Trabajar con partes interesadas para facilitar y organizar investigaciones sobre las fabricas de papers
Prestar especial atención a aspectos regionales y específicos del tema en los esfuerzos de investigación.
Facilitar el Desarrollo de Indicadores de Confianza:
Colaborar con los diversos proveedores que desarrollan herramientas para verificar la identidad de autores, revisores y editores.
Asegurar que estas soluciones funcionen para la variedad de autores y elecciones de autores y sean adecuadas para su propósito previsto.
Continuar Facilitando el Diálogo entre los Interesados:
Mantener un diálogo continuo entre los interesados sobre la manipulación sistemática del proceso de publicación.
Fomentar proyectos e iniciativas conjuntas para reunir las diversas voces en este campo.
La Declaración de Consenso delineó una estrategia integral que abarca la educación, procesos de corrección, iniciativas de investigación, soluciones tecnológicas y colaboración continua para combatir colectivamente la amenaza que representan las «fabricas de papers» para la integridad del registro académico.