McKie, Robin. «‘The Situation Has Become Appalling’: Fake Scientific Papers Push Research Credibility to Crisis Point». The Observer, 3 de febrero de 2024, sec. Science. https://www.theguardian.com/science/2024/feb/03/the-situation-has-become-appalling-fake-scientific-papers-push-research-credibility-to-crisis-point.
Los científicos están haciendo sonar la alarma sobre la publicación masiva de miles de documentos de investigación falsos en revistas, lo que constituye un creciente escándalo internacional. Esta situación está comprometiendo la investigación médica, obstaculizando el desarrollo de medicamentos y poniendo en peligro la prometedora investigación académica. Una ola global de ciencia fraudulenta está afectando gravemente a laboratorios y universidades.
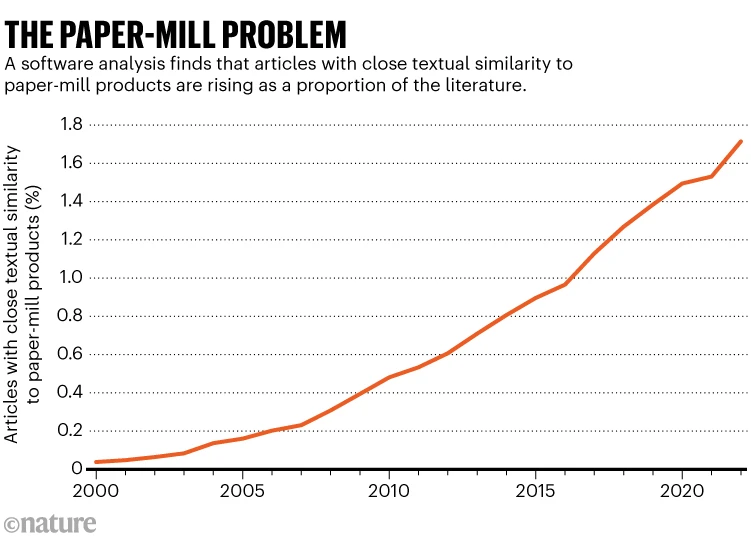
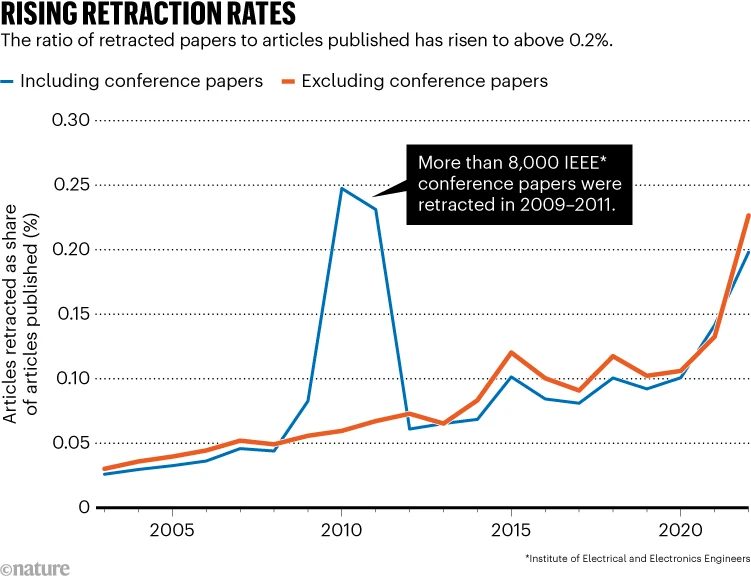
El año pasado, el número anual de documentos retractados por revistas de investigación superó los 10.000 por primera vez. La mayoría de los analistas creen que la cifra es solo la punta de un iceberg de fraude científico.
«La situación se ha vuelto alarmante», dijo la profesora Dorothy Bishop de la Universidad de Oxford. «El nivel de publicación de documentos fraudulentos está creando problemas serios para la ciencia. En muchos campos, está volviéndose difícil construir un enfoque acumulativo hacia un tema, porque nos falta una base sólida de hallazgos confiables. Y va empeorando más y más».
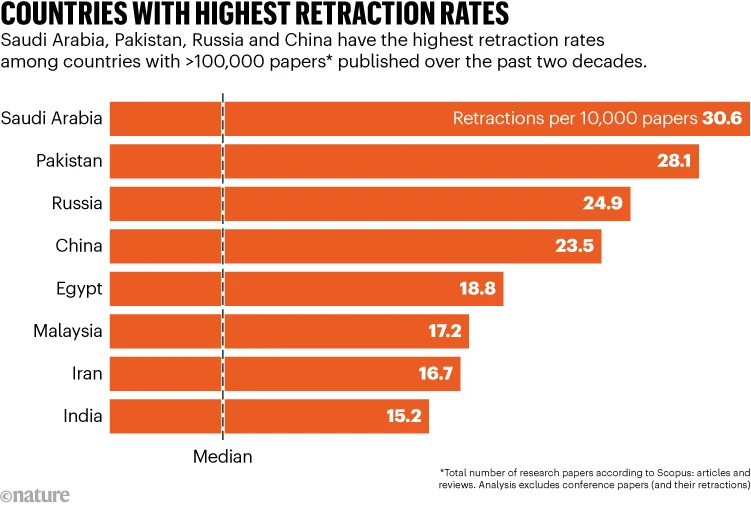
El sorprendente aumento en la publicación de documentos de ciencia falsa tiene sus raíces en China, donde a jóvenes médicos y científicos que buscaban ascensos se les exigía haber publicado documentos científicos. Organizaciones clandestinas, conocidas como «fábricas de documentos» (Paper mills), comenzaron a suministrar trabajos fabricados para su publicación en revistas allí.
La práctica se ha extendido desde entonces a India, Irán, Rusia, estados de la antigua Unión Soviética y Europa del Este, con «fábricas de documentos» suministrando estudios fabricados a más y más revistas a medida que aumenta el número de jóvenes científicos que intentan impulsar sus carreras al reclamar una falsa experiencia de investigación. En algunos casos, los editores de revistas han sido sobornados para aceptar artículos, mientras que las «fábricas de documentos» han logrado establecer a sus propios agentes como editores invitados que luego permiten que se publiquen montones de trabajos falsificados.
«Los editores no están cumpliendo adecuadamente con sus roles y los revisores por pares no están haciendo su trabajo. Y algunos están siendo pagados grandes sumas de dinero», dijo la profesora Alison Avenell de la Universidad de Aberdeen. «Es profundamente preocupante».
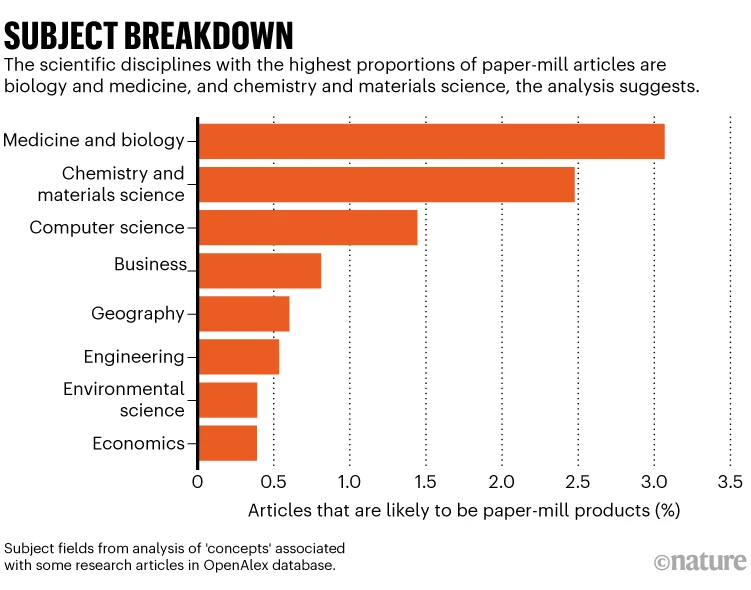
Los productos de las «fábricas de documentos» a menudo parecen artículos regulares pero se basan en plantillas en las que se insertan nombres de genes o enfermedades al azar entre tablas y figuras ficticias. Preocupantemente, estos artículos pueden ser incorporados a grandes bases de datos utilizadas por aquellos que trabajan en el descubrimiento de medicamentos.
Otros son más extraños e incluyen investigaciones no relacionadas con el campo de una revista, lo que deja en claro que no se ha llevado a cabo una revisión por pares en relación con ese artículo. Un ejemplo es un documento sobre la ideología marxista que apareció en la revista Computational and Mathematical Methods in Medicine. Otros son distintivos debido al lenguaje extraño que utilizan, incluyendo referencias a «peligro del seno» en lugar de cáncer de seno y «afección de Parkinson» en lugar de enfermedad de Parkinson.
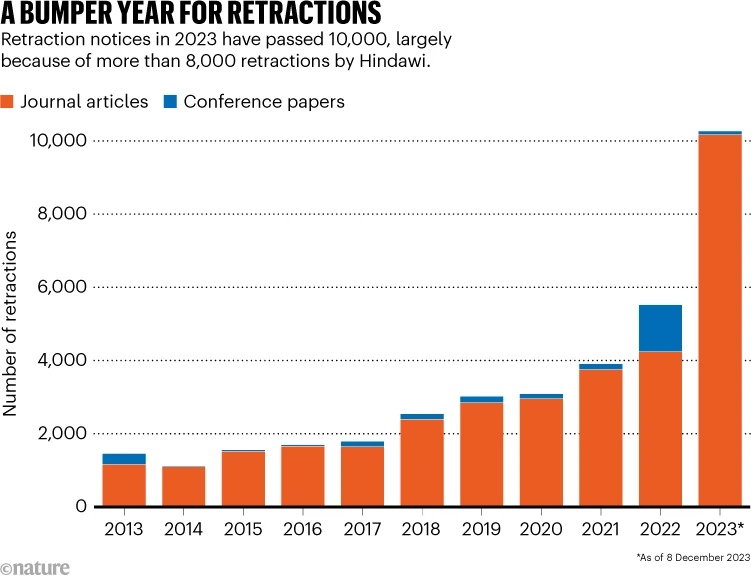
Grupos de vigilancia, como Retraction Watch, han rastreado el problema y han notado retractaciones por parte de revistas que se vieron obligadas a actuar en ocasiones cuando se descubrieron fabricaciones. Un estudio, realizado por Nature, reveló que en 2013 hubo poco más de 1.000 retractaciones. En 2022, la cifra superó los 4.000 antes de saltar a más de 10.000 el año pasado.
De los más de 10.000 documentos retractados el año pasado, más de 8,000 habían sido publicados en revistas propiedad de Hindawi, una subsidiaria de Wiley. Estas cifras han obligado a la empresa a tomar medidas drásticas. Un portavoz de Wiley anunció: «Vamos a eliminar la marca Hindawi y hemos comenzado a integrar completamente los más de 200 diarios de Hindawi en el portafolio de Wiley». Además, la compañía ha identificado a cientos de estafadores en su cartera de revistas y ha removido a aquellos que desempeñaron roles editoriales. Aunque Wiley reconoce que no puede abordar la crisis por sí sola, otras editoriales también se ven afectadas por los «paper mills». Los académicos se muestran cautelosos, ya que en muchos países son remunerados según la cantidad de artículos publicados. El daño causado por la publicación de investigaciones deficientes o falsas se evidencia con el caso del fármaco antiparasitario ivermectina, que inicialmente se creyó que podría tratar el Covid-19 pero posteriormente se descubrió evidencia clara de fraude en los estudios. Este incidente ilustra cómo la ciencia se ve afectada por el material fabricado. Los expertos advierten sobre la creciente amenaza de los «paper mills» y la investigación fraudulenta, señalando que la integridad del conocimiento científico está en peligro y que la corrupción está infiltrándose en el sistema.