Tran, Nham. «The ‘Publish or Perish’ Mentality Is Fuelling Research Paper Retractions – and Undermining Science.» The Conversation, September 24, 2024. https://theconversation.com/the-publish-or-perish-mentality-is-fuelling-research-paper-retractions-and-undermining-science-238983
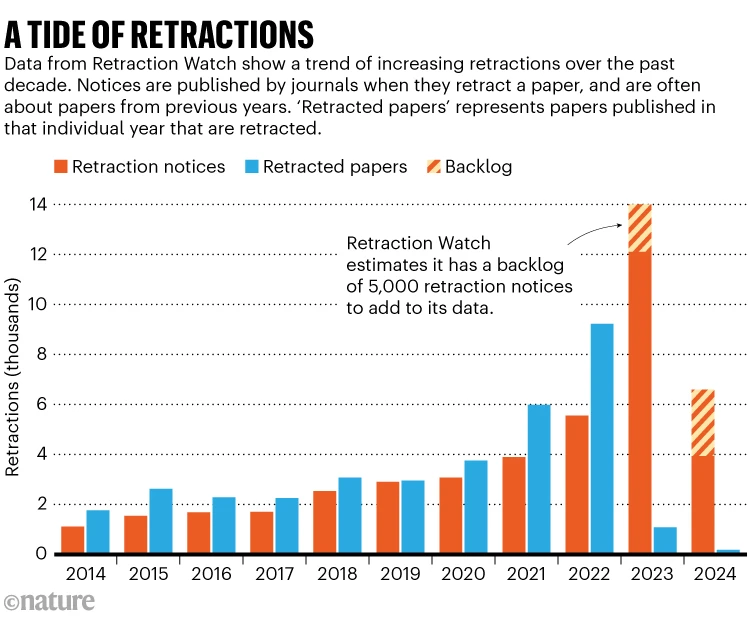
Los científicos, al realizar descubrimientos importantes, suelen publicar sus hallazgos en revistas científicas para que otros puedan leerlos y beneficiarse de ese conocimiento. Esta difusión de información es fundamental para el progreso de la ciencia, ya que permite que otros investigadores construyan sobre trabajos previos y, potencialmente, realicen nuevos descubrimientos significativos. Sin embargo, los artículos publicados pueden ser retractados si se detectan problemas de precisión o integridad en los datos. En años recientes, el número de retractaciones ha aumentado considerablemente. En 2023, se retractaron más de 10.000 artículos de manera global, estableciendo un nuevo récord.
El aumento en las retractaciones está impulsado por la mentalidad de «publicar o perecer», una situación que ha prevalecido en la academia durante décadas. La publicación de artículos de investigación es un factor clave para el avance en la carrera académica y para la mejora de los rankings universitarios. Las universidades y los institutos de investigación suelen utilizar el número de publicaciones como indicador principal de productividad y reputación. Esto ha llevado a una presión constante sobre los académicos para publicar regularmente, lo que, a su vez, ha contribuido a un aumento en la presentación de datos fraudulentos. Si esta tendencia continúa, el paisaje de la investigación podría cambiar hacia estándares menos rigurosos, dificultando el progreso en áreas críticas como la medicina, la tecnología y la ciencia climática.
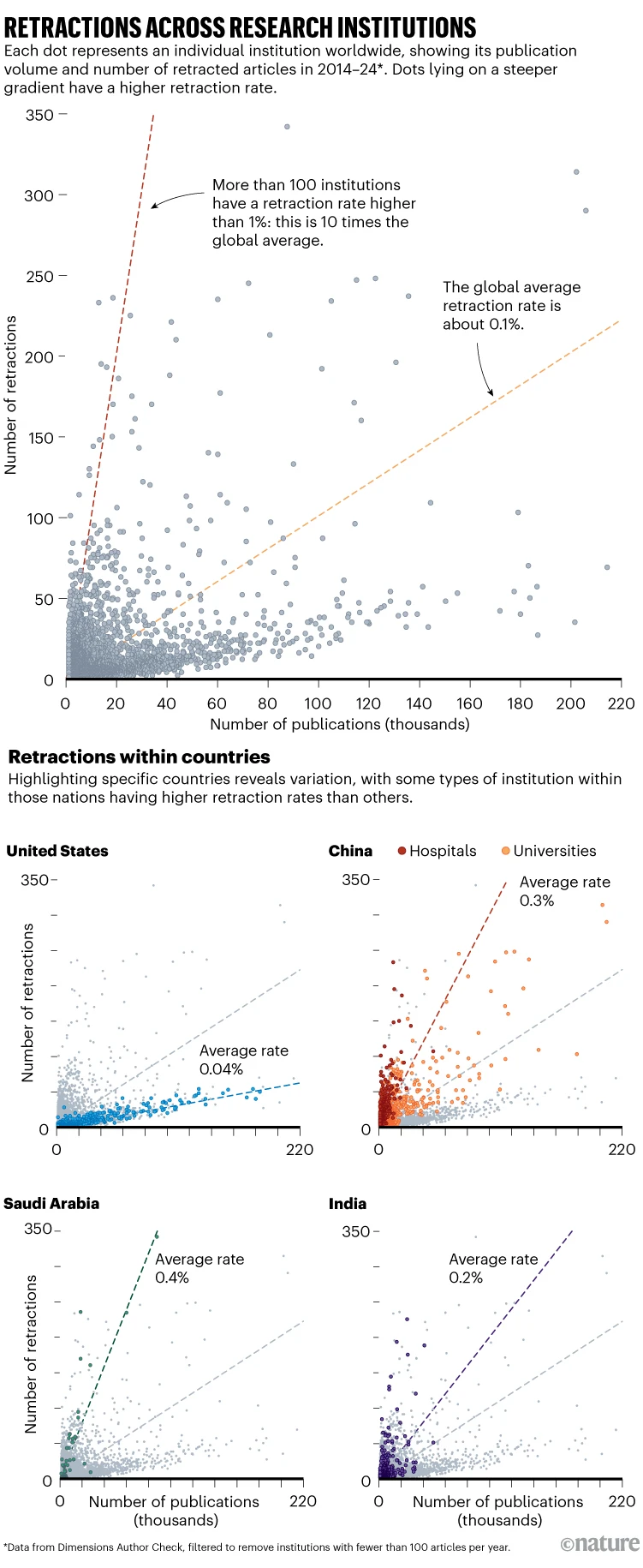
Retraction Watch, una de las bases de datos más grandes que monitorea las retractaciones científicas, ha revelado un incremento en la cantidad de artículos retractados. En la última década, se han retractado más de 39.000 publicaciones, y el número anual de retractaciones está creciendo alrededor de un 23% cada año. Aproximadamente la mitad de estas retractaciones se deben a problemas relacionados con la autenticidad de los datos. Un ejemplo es el caso de Richard Eckert, un bioquímico senior de la Universidad de Maryland, Baltimore, quien falsificó datos en 13 artículos publicados. De estos, cuatro han sido corregidos, uno ha sido retractado y los demás están en proceso de acción.
El plagio es la segunda razón más común para la retractación de artículos, representando el 16% de los casos. Otro motivo significativo es el uso de revisiones por pares falsas, un problema que ha aumentado diez veces en la última década. También ha habido un incremento en las publicaciones asociadas con las llamadas «fábricas de artículos» (Paper Mills), que son empresas que producen artículos falsos por una tarifa. En 2022, hasta un 2% de todas las publicaciones provinieron de estas fábricas. Los errores genuinos en el proceso científico solo representan aproximadamente el 6% de todas las retractaciones en la última década.
La presión para publicar ha llevado a un aumento en los errores y las prácticas fraudulentas. Aunque la digitalización ha facilitado la detección de datos sospechosos, también ha intensificado la cultura de «publicar o perecer» en las universidades. La mayoría del personal académico debe cumplir con cuotas específicas de publicaciones para evaluaciones de desempeño, y las instituciones utilizan el rendimiento en publicaciones para mejorar su posición en los rankings globales, lo que atrae a más estudiantes y genera ingresos por enseñanza.
El sistema de recompensas en la academia a menudo prioriza la cantidad sobre la calidad de las publicaciones. Este enfoque puede llevar a los científicos a recortar esquinas, apresurar experimentos o incluso falsificar datos para cumplir con las métricas impuestas. Para abordar este problema, iniciativas como la Declaración de San Francisco sobre la Evaluación de la Investigación están impulsando un cambio hacia la evaluación de la investigación basada en su calidad e impacto social, en lugar de métricas centradas en revistas, como factores de impacto o recuentos de citas.
Cambiar las políticas de las revistas para priorizar el intercambio de todos los datos experimentales podría mejorar la integridad científica, permitiendo a los investigadores replicar experimentos para verificar los resultados de otros. Además, las universidades, los institutos de investigación y las agencias de financiamiento necesitan mejorar su diligencia debida y responsabilizar a aquellos involucrados en malas conductas. Incluir preguntas simples en las solicitudes de subvenciones o promociones académicas, como «¿Alguna vez ha tenido o estado involucrado en un artículo retractado?», podría mejorar la integridad de la investigación al disuadir comportamientos poco éticos. Las respuestas deshonestas podrían ser fácilmente detectadas gracias a la disponibilidad de herramientas en línea y bases de datos como Retraction Watch.