Doe, Jane, y John Smith. «Avances recientes en biotecnología.» Nature vol. 525, no. 7567 (2025): 123-126. https://www.nature.com/articles/d41586-025-00455-y
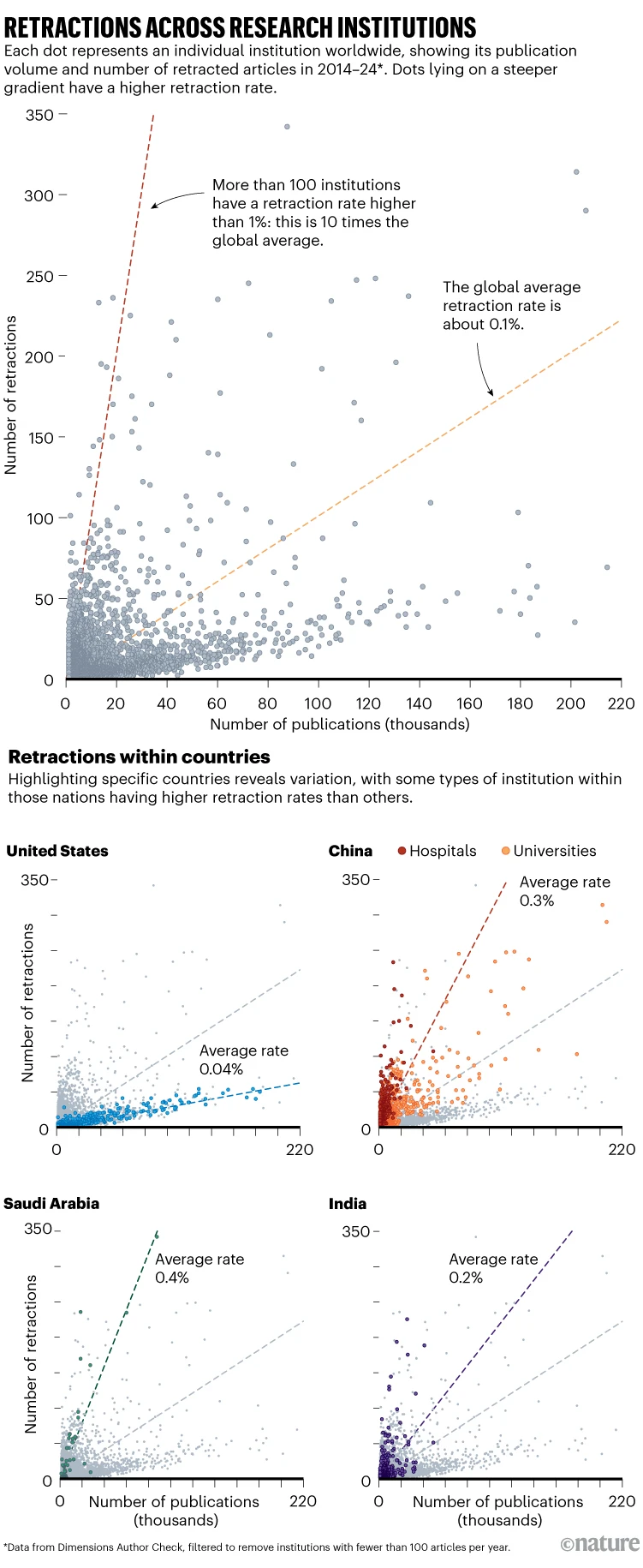
Nature ha realizado un análisis pionero sobre las tasas de retracción de artículos científicos en instituciones de todo el mundo, revelando que ciertos hospitales y universidades en China, India, Pakistán, Etiopía y Arabia Saudita son focos de publicaciones fraudulentas. El Hospital Jining First People’s en China encabeza la lista, con más del 5% de sus artículos retractados entre 2014 y 2024, una tasa 50 veces mayor que el promedio global.
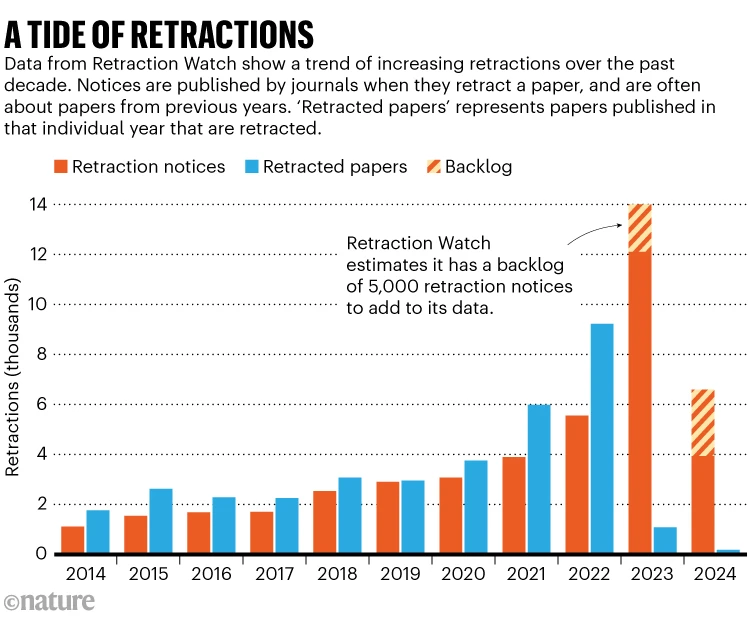
El volumen de retractaciones ha aumentado en la última década, con más de 10,000 artículos retirados en 2023, en gran parte debido al fraude detectado en revistas de la editorial Hindawi. Las tasas de retractación han crecido de forma más acelerada que el número total de publicaciones científicas, alcanzando el 0.2% de los artículos publicados en 2022. Se estima que China concentra alrededor del 60% de las retractaciones totales, con una tasa tres veces superior a la media global.
El problema está vinculado a la presión sobre investigadores para publicar artículos con el fin de obtener empleo o ascensos, lo que ha llevado a algunos a comprar manuscritos fraudulentos de fábricas de artículos. Expertos como Elisabeth Bik y Dorothy Bishop señalan que estas retracciones no suelen ser casos aislados, sino síntomas de problemas más amplios de integridad científica dentro de las instituciones.
Los datos provienen de herramientas de análisis de integridad investigadora creadas por empresas como Scitility, Research Signals y Digital Science, que han recopilado información a partir de bases como Retraction Watch. Si bien las retracciones representan menos del 0.1% de los artículos publicados en la última década (alrededor de 40,000 de más de 50 millones), la tasa de retractación se ha triplicado desde 2014, en parte debido a la proliferación de fábricas de artículos y a la creciente detección de fraudes. . Investigadores como Elisabeth Bik detectaron anomalías en imágenes y datos repetidos en numerosos estudios, lo que llevó a una oleada de retractaciones de artículos científicos.
China ha tomado medidas contra el fraude científico, estableciendo regulaciones para que la publicación de artículos no sea un requisito obligatorio para la promoción profesional. Sin embargo, las tasas de retracción en el país siguen aumentando. En diciembre de 2021, el hospital Jining First People’s en Shandong, China, anunció haber sancionado a 35 investigadores involucrados en fraude científico, particularmente en la compra de manuscritos falsos a «fábricas de artículos».
Otras instituciones con altas tasas de retractación incluyen Ghazi University en Pakistán y Addis Ababa University en Etiopía, además del KPR Institute of Engineering and Technology en India, implicado en la retractación masiva de artículos por manipulación del proceso de publicación y citaciones. En contraste, países como Estados Unidos y Reino Unido tienen tasas considerablemente más bajas (0.04%). Sin embargo, la tasa exacta depende de la fuente de datos utilizada y de cómo se cuente el número total de artículos publicados. Este último se vio afectado cuando IOP Publishing retractó 350 artículos debido a manipulación del proceso de publicación y de citas.
Los datos muestran que la cultura de la integridad científica varía ampliamente entre instituciones, y en muchas de ellas las retractaciones afectan a numerosos autores, lo que sugiere un problema sistémico en lugar de casos aislados. Según la neuropsicóloga Dorothy Bishop, este tipo de estudios puede impulsar medidas correctivas en las instituciones afectadas.









