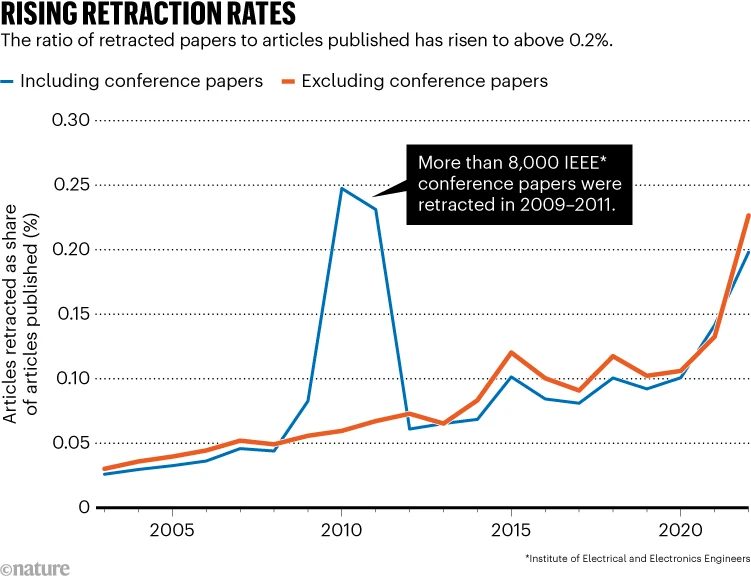
Van Noorden, Richard. 2023. «How Big Is Science’s Fake-Paper Problem?» Nature 623 (7987): 466-67. https://doi.org/10.1038/d41586-023-03464-x.
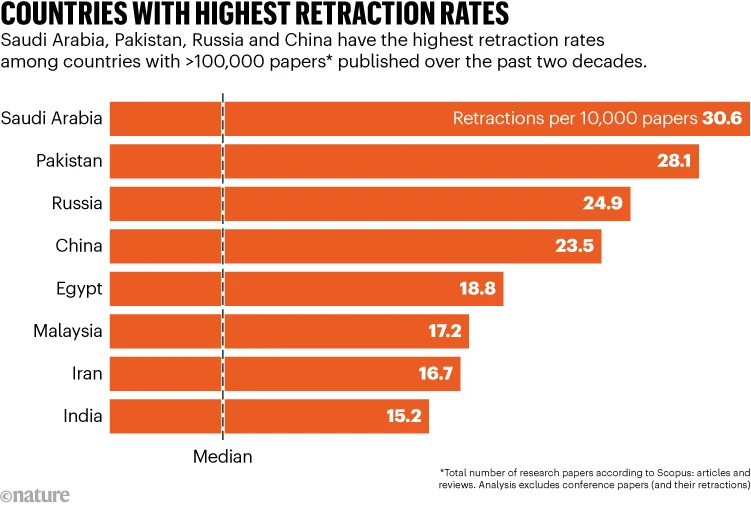
La literatura científica está contaminada con manuscritos falsos generados por fábricas de documentos (Paper Mills), empresas que venden trabajos y autorías falsas a investigadores que necesitan publicaciones para sus currículos. Un análisis no publicado compartido con Nature sugiere que en las últimas dos décadas se han publicado más de 400.000 artículos de investigación que muestran similitudes textuales con estudios conocidos producidos por estas fábricas. Alrededor de 70.000 de estos fueron publicados solo el año pasado. El análisis estima que el 1.5-2% de todos los artículos científicos publicados en 2022 se asemejan estrechamente a trabajos de fábricas de documentos, aumentando al 3% en biología y medicina.
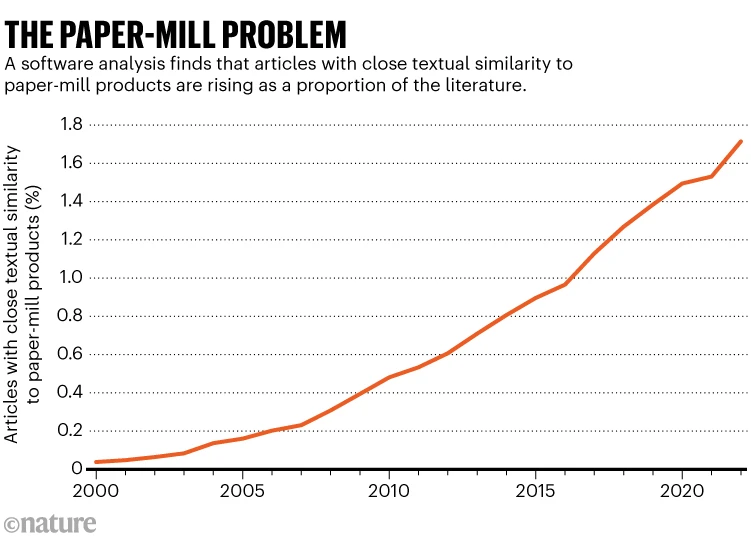
El problema de las fábricas de documentos se ilustra en un gráfico que muestra el porcentaje de artículos con similitud a productos de fábricas de 2000 a 2022, según estimaciones no publicadas de Adam Day.
Sin investigaciones individuales, es imposible saber si todos estos documentos son realmente productos de fábricas de documentos. Adam Day, director de la empresa de servicios de datos académicos Clear Skies en Londres, realizó el análisis utilizando un software de aprendizaje automático llamado Papermill Alarm. En septiembre, una iniciativa de editores llamada STM Integrity Hub, que busca combatir la ciencia fraudulenta, licenció una versión del software de Day para detectar manuscritos potencialmente fabricados.
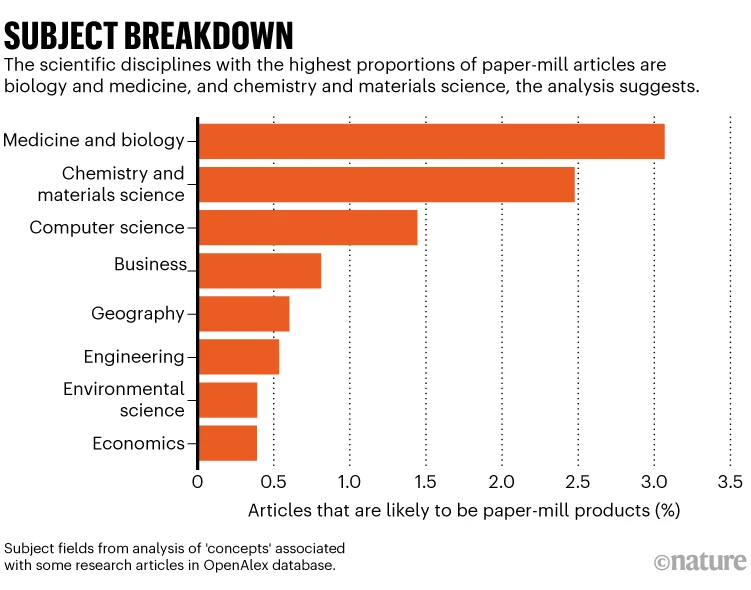
Los estudios de fábricas de documentos se producen en lotes grandes y a gran velocidad, a menudo siguiendo plantillas específicas. Day utilizó su software para analizar títulos y resúmenes de más de 48 millones de artículos publicados desde 2000, identificando manuscritos con texto que se asemejaba mucho a trabajos conocidos de fábricas de documentos.
Bimler elogia el enfoque de similitud estilística de Day como el mejor disponible para estimar la prevalencia de estos estudios, aunque advierte sobre posibles falsos positivos. Day intentó minimizarlos validando los resultados con conjuntos de prueba de documentos genuinos o falsos.
Day también examinó un subconjunto de 2.85 millones de trabajos publicados en 2022, encontrando que alrededor del 2.2% se parecían a estudios de fábricas de documentos, variando según la disciplina científica.
A pesar de algunas preocupaciones, la estimación de Day es considerada plausible por algunos expertos. Day ve su estimación como un límite inferior, ya que puede perder fábricas de documentos que evitan plantillas conocidas. La distribución de estas fábricas no es uniforme en las revistas y se agrupan en títulos específicos, aunque Day no revela públicamente cuáles se ven más afectados.
Se destaca que las editoriales han intensificado sus esfuerzos para combatir las fábricas de documentos, utilizando diversas señales, como patrones textuales, direcciones de correo sospechosas, gráficos idénticos que representan diferentes experimentos y otras pistas.
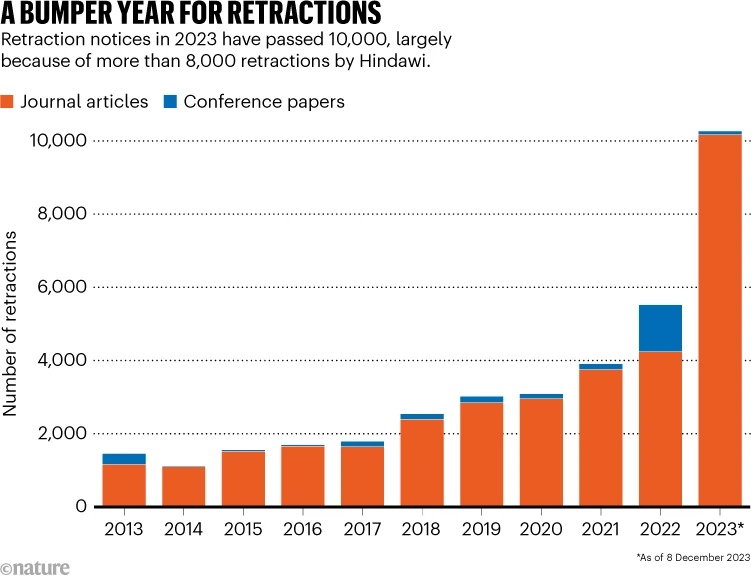
A pesar de los esfuerzos, el problema parece abrumar los sistemas de las editoriales. La base de datos de retractaciones más grande del mundo, mantenida por Retraction Watch, registra menos de 3.000 retractaciones relacionadas con actividades de fábricas de documentos de un total de 44.000. Los números de retractación son considerados una subestimación, lo que sugiere que los productores de fábricas de documentos se sienten relativamente seguros.