Worlock, David. 2026. “AI and the Issue of Science Article Retraction.” DavidWorlock.com, 6 de enero de 2026. https://www.davidworlock.com/2026/01/ai-and-the-issue-of-science-article-retraction/
Se ofrece una reflexión crítica sobre los desafíos que la inteligencia artificial (IA) plantea al sistema de publicación científica, especialmente en lo referente a la integridad del registro científico y el proceso de retractación de artículos académicos.
Worlock parte de una observación fundamental: aunque la IA está transformando profundamente la creación, difusión y análisis de conocimiento, muchos de los problemas estructurales que afectan a la ciencia —como la proliferación de artículos defectuosos, revisiones por pares ineficaces o la falta de mecanismos eficaces para gestionar retractaciones— no se resolverán simplemente mediante la automatización o la adopción de nuevas herramientas tecnológicas.
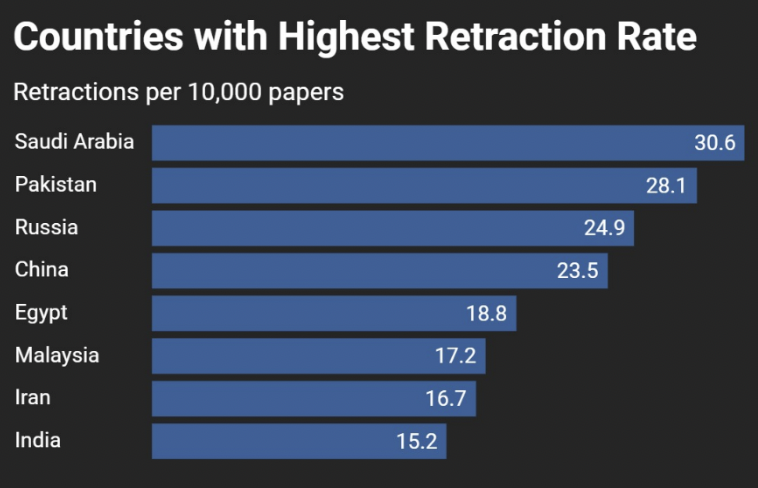
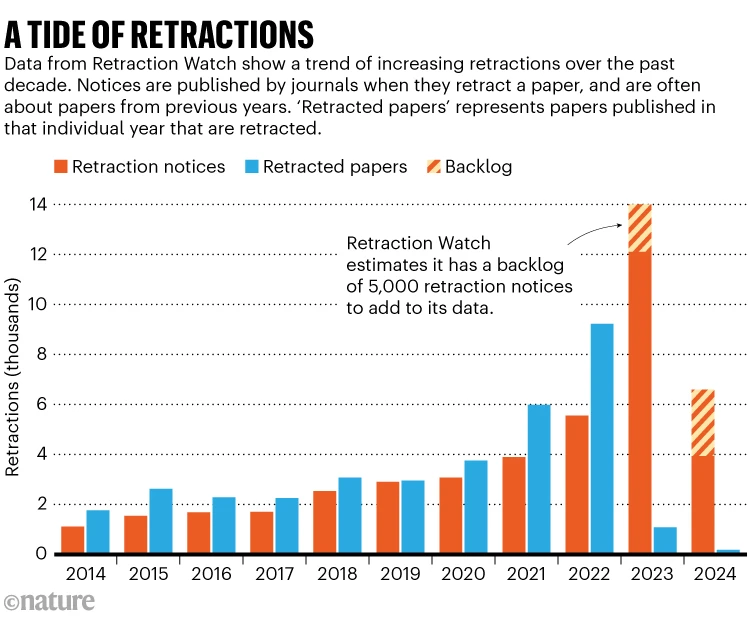
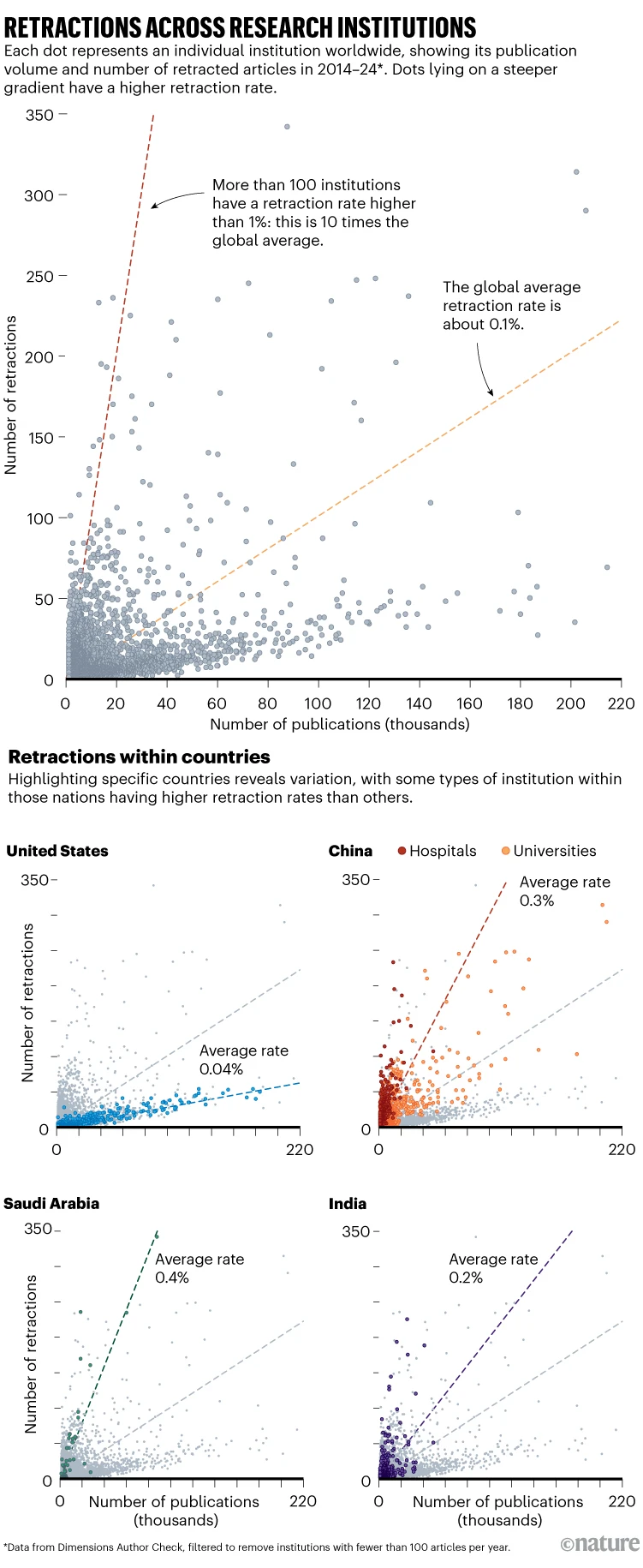
El autor contextualiza el tema en un contexto más amplio de crisis de confianza en las publicaciones científicas. Señala que la incapacidad del sistema para proporcionar estándares claros y verificables de calidad y autenticidad ha permitido que proliferan trabajos de mala calidad o incluso fraudulentos, muchos de los cuales permanecen en la literatura científica sin una retractación adecuada. Este problema no se limita a casos aislados, sino que forma parte de un sistema que continúa replicando y amplificando errores debido a la presión por publicar y a la ausencia de una infraestructura de retractación centralizada y transparente.
Worlock también examina el rol de la IA en este contexto. Aunque los sistemas de IA tienen la capacidad de procesar grandes volúmenes de información, Worlock advierte que la IA no sustituye la evaluación crítica humana y que los algoritmos pueden incluso exacerbar algunos de los problemas existentes si se utilizan sin criterio. Por ejemplo, las IA pueden integrar contenido repleto de errores metodológicos o datos falsos como si fuera válido, ya que carecen de un juicio epistemológico real para discernir la calidad científica, un reto que otros expertos han también identificado recientemente como un riesgo serio para la confianza en la literatura científica automatizada.
Además, el artículo subraya la importancia de reforzar los mecanismos de retractación. Worlock plantea que la mera existencia de retractaciones no basta si estas no son accesibles, claras y eficientemente comunicadas, algo que muchos investigadores experimentan cuando intentan rastrear qué artículos han sido retirados y por qué. El problema, según él y otros especialistas, radica en que las retractaciones a menudo no están bien etiquetadas ni se integran en los flujos de datos primarios que usan los motores de búsqueda, las bases de datos académicas y los propios sistemas de entrenamiento de modelos de IA.
Una vez que se introducen datos en el modelo de formación de un LLM, no se pueden eliminar. No quiero escribir aquí sobre los actos de piratería cometidos por los actores de la IA de Silicon Valley al retirar masivamente artículos académicos de sitios web a menudo pirateados e ilegales. Sin duda, esos datos incluían artículos retractados que nunca se habían eliminado ni etiquetado como retractados en línea. De hecho, en el mundo anterior a la IA, una de las quejas sobre la búsqueda de artículos académicos era que los artículos retractados rara vez eran evidentes. Solo en épocas más recientes, Retraction Watch y Open Alex comenzaron a señalar qué datos no eran confiables en las bases de datos académicas. En otras palabras, fue la comunidad académica y sin fines de lucro la que acudió al rescate, no el sector editorial con fines de lucro. Se podría considerar cómo podríamos construir modelos más efectivos y precisos en el futuro y cómo podríamos asegurarnos de que el material retractado no se incluya en ellos.
En esencia, Worlock llama a una reforma profunda del ecosistema de publicación científica, donde la IA se utilice no como sustituto de la evaluación humana, sino como complemento que apoye una mayor transparencia, responsabilidad y calidad en la ciencia publicada. Su análisis enfatiza que los avances tecnológicos deben ir acompañados de estructuras éticas y metodológicas que preserven la integridad del registro científico y protejan la confianza pública en la investigación académica.