Rivero, Athena Chapekis, Samuel Bestvater, Emma Remy and Gonzalo. «When Online Content Disappears». Pew Research Center (blog), 17 de mayo de 2024. https://www.pewresearch.org/data-labs/2024/05/17/when-online-content-disappears/.
Un nuevo análisis del Pew Research Center muestra lo efímeros que son los contenidos en línea. Una cuarta parte de todas las páginas web que existieron en algún momento entre 2013 y 2023 ya no son accesibles, a partir de octubre de 2023. En la mayoría de los casos, esto se debe a que una página individual fue eliminada o suprimida de un sitio web que, por lo demás, funcionaba.
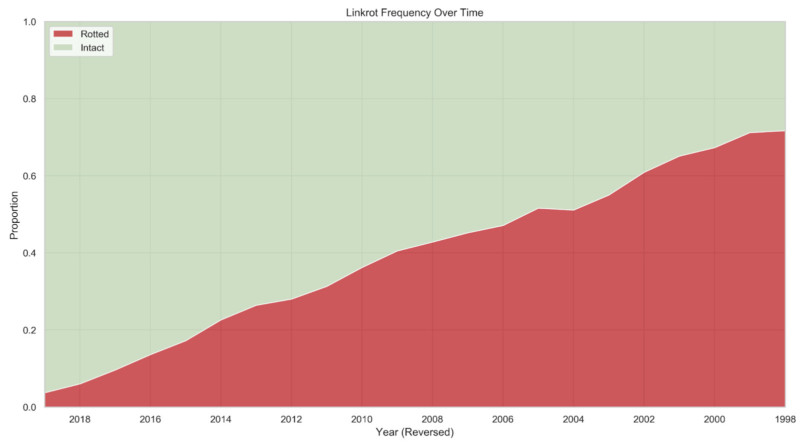
En el caso de los contenidos más antiguos, la tendencia es aún más marcada. Alrededor del 38% de las páginas web que existían en 2013 no están disponibles hoy en día, en comparación con el 8% de las páginas que existían en 2023. Un gráfico de líneas que muestra que el 38% de las páginas web de 2013 ya no están accesibles
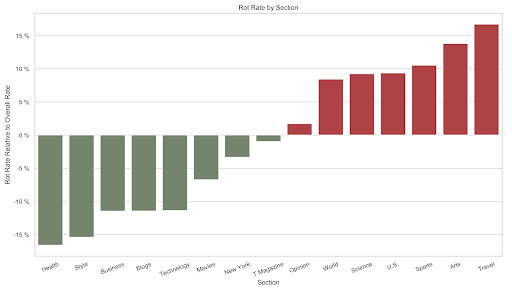
Esta «decadencia digital» se produce en muchos espacios en línea diferentes. Hemos examinado los enlaces que aparecen en sitios web gubernamentales y de noticias, así como en la sección «Referencias» de las páginas de Wikipedia en la primavera de 2023. Este análisis reveló que:
- El 23% de las páginas web de noticias contienen al menos un enlace roto, al igual que el 21% de las páginas web de sitios gubernamentales. Los sitios web de noticias con un alto nivel de tráfico y los que tienen menos tráfico tienen casi las mismas probabilidades de contener enlaces rotos. Las páginas de las administraciones locales (ayuntamientos) son especialmente propensas a tener enlaces rotos.
- El 54% de las páginas de Wikipedia contienen al menos un enlace en su sección «Referencias» que apunta a una página que ya no existe.
Para ver cómo se desarrolla la decadencia digital en las redes sociales, también se recogió una muestra en tiempo real de tuits durante la primavera de 2023 en la plataforma de redes sociales X (entonces conocida como Twitter) y los seguimos durante tres meses. Descubrimos que
- Casi uno de cada cinco tuits ya no son visibles públicamente en el sitio apenas unos meses después de haber sido publicados.
- En el 60% de los casos, la cuenta que publicó originalmente el tuit se hizo privada, se suspendió o se eliminó por completo. En el 40% restante, el titular de la cuenta eliminó el tuit, pero la cuenta seguía existiendo.
- Ciertos tipos de tuits tienden a desaparecer con más frecuencia que otros. Más del 40% de los tuits escritos en turco o árabe dejan de ser visibles en el sitio a los tres meses de su publicación.
- Y los tuits de cuentas con la configuración de perfil por defecto son especialmente propensos a desaparecer de la vista del público.