The Future of Algorithms and Collaborative Tagging in Our Libraries
Editor’s note: This is a guest post by Jessica Luna. Hack Library School, 2022
La folcsonomía es el proceso de utilizar etiquetas de contenidos digitales para su categorización o anotación. Permite a los usuarios clasificar sitios web, imágenes, documentos y otras formas de datos para que el contenido pueda ser fácilmente categorizado y localizado por los usuarios.
La búsqueda se ha convertido en un hilo conductor la vida diaria. El aprendizaje de métodos básicos y avanzados de búsqueda de diferentes tipos de información, la evaluación de los resultados de la búsqueda y la comprensión de cómo los algoritmos dan forma a nuestras consultas son sólo algunas de las cosas a tener en cuenta. Y son esos algoritmos los que han dominado nuestras vidas desde antes de la existencia de la Web 2.0.
Los métodos de recuperación de información personalizada (PIR) mediante el etiquetado colaborativo, también conocido como folcsonomías. El etiquetado colaborativo está cada vez más arraigado en los sistemas bibliotecarios en línea de última generación porque resulta familiar y cómodo para los usuarios navegar y descubrir materiales etiquetados de forma similar. La personalización se ha convertido en un factor esencial en la configuración de las folcsonomías actuales.
Las folcsonomías se utilizan en sitios web de redes sociales como Flickr, Twitter e Instagram para ayudar a los usuarios a buscar temas de su interés. Los creadores de contenidos en plataformas como YouTube y Twitch utilizan las folcsonomías para que sus contenidos sean más buscables y lleguen a un público más amplio. Esto nos hace plantearnos si los modelos de recomendación PIR son el futuro de los catálogos de las bibliotecas de nueva generación.
¿Cómo funciona?
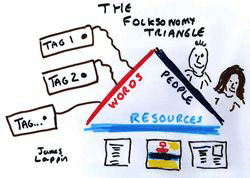
El modelo básico actual de sistema de folcsonomía contiene tres variables esenciales: usuarios, recursos y etiquetas. Estas tres variables constituyen la base para calcular el peso y la clasificación de las etiquetas en diversos sistemas de etiquetado. Los modelos PIR utilizan los perfiles de los usuarios y de los recursos para personalizar su experiencia de búsqueda en función de sus intereses. El objetivo es identificar la respuesta más cercana a la necesidad de una persona en función de las características de su cuenta de usuario.
Una parte importante de los modelos PIR para folksonomías son los sistemas de recomendación. Hay muchas investigaciones sobre diferentes métodos PIR que pueden cambiar drásticamente la forma de clasificar los documentos y las etiquetas que se recomiendan a los usuarios. Algunos sistemas de recomendación PIR reconocen que el comportamiento de etiquetado de los usuarios suele cambiar con el tiempo, por lo que el sistema ideal debería tener en cuenta el comportamiento de etiquetado histórico de un usuario a la hora de evaluar el peso y la clasificación de un recurso etiquetado. Otros algoritmos exploran la relación entre la relevancia de la consulta y la relevancia del interés del usuario. La teoría sugiere que cuantas más veces utiliza un usuario una etiqueta en su perfil, más interesado está en su tema.
El análisis de sentimientos es una forma de que el aprendizaje automático extraiga los intereses y sentimientos de los usuarios basándose en los temas que siguen y en las etiquetas que han buscado en el pasado. Aplica evaluaciones de similitud para crear una mayor precisión de los recursos recuperados. Los algoritmos generan relaciones entre palabras y frases, categorizando las relaciones semánticas entre frases y oraciones. Los términos se clasifican dentro de un espacio vectorial, y los que tienen mayor puntuación tienen más peso a la hora de representar un tema.
Problemas de personalización
Una queja común sobre los sistemas PIR es la privacidad. La personalización sólo puede producirse obteniendo datos del usuario, a menudo sin su conocimiento o consentimiento.
Los sistemas de recomendación pueden forzar a los usuarios a entrar en burbujas de filtros. Estos sistemas aíslan a los usuarios de otras perspectivas y visiones del mundo, perpetuando la ignorancia de la gente sobre creencias y culturas alternativas. Es esencialmente otro tipo de censura que estrecha la percepción de una persona. Por suerte, se han desarrollado otros métodos para diversificar las recomendaciones del PIR.
Mirando hacia el futuro
Los estudios PIR proporcionan una idea de cómo los algoritmos clasifican y ponderan las folksonomías. También nos permite suponer cómo las empresas privadas podrían utilizar métodos similares a la hora de sugerir recursos a los usuarios. Twitter me viene a la mente cuando pienso en los modelos PIR utilizados con las folcsonomías. Cuando interactúas suficientes veces con otro usuario o con un hashtag concreto, el algoritmo añade usuarios y hashtags similares a tu feed.
Hablamos de Twitter porque ha sido noticia últimamente. Para promover la transparencia del algoritmo, Elon Musk declaró en una reciente charla TED sus intenciones de hacer que Twitter sea de código abierto. Será nuestro primer vistazo al análisis crítico de los algoritmos de una plataforma de medios sociales y a una mayor investigación sobre los sistemas PIR.
Al convertirse los algoritmos de Twitter en código abierto, es posible que veamos más estudios sobre cómo los sistemas PIR dan forma a las experiencias de los usuarios. También abre la puerta a nuevas investigaciones sobre las implicaciones éticas de los sistemas PIR y sus posibles soluciones.
Por el momento, no hemos encontrado ningún catálogo de nueva generación que utilice métodos PIR para las folcsonomías. Los ILS/LSP suelen utilizar etiquetas como facetas en su catálogo. Koha tiene una nube de etiquetas que muestra las etiquetas más utilizadas. La adición de medidas de análisis de sentimiento podría resultar fructífera para identificar las similitudes entre las etiquetas. Las etiquetas que podrían considerarse molestas y subjetivas tendrían ahora un significado.
No está claro si algún ILS/LSP incluirá algún día métodos PIR en sus sistemas, pero es bueno saber cómo funcionan.