«NIST Identifies Types of Cyberattacks That Manipulate Behavior of AI Systems». 2024. NIST, enero. https://www.nist.gov/news-events/news/2024/01/nist-identifies-types-cyberattacks-manipulate-behavior-ai-systems.
La publicación, una colaboración entre el gobierno, la academia y la industria, tiene la intención de ayudar a los desarrolladores y usuarios de IA a comprender los tipos de ataques que podrían esperar, junto con enfoques para mitigarlos, con la comprensión de que no hay una solución única.
Los sistemas de IA han permeado la sociedad moderna, trabajando en capacidades que van desde conducir vehículos hasta ayudar a los médicos a diagnosticar enfermedades o interactuar con clientes como chatbots en línea. Para aprender a realizar estas tareas, se entrenan con vastas cantidades de datos: un vehículo autónomo podría mostrar imágenes de carreteras con señales de tráfico, por ejemplo, mientras que un chatbot basado en un modelo de lenguaje grande (LLM) podría exponerse a registros de conversaciones en línea. Estos datos ayudan a la IA a predecir cómo responder en una situación dada.
Un problema importante es que los datos en sí mismos pueden no ser confiables. Sus fuentes pueden ser sitios web e interacciones con el público. Hay muchas oportunidades para que actores malintencionados corrompan estos datos, tanto durante el período de entrenamiento de un sistema de IA como después, mientras la IA continúa refinando sus comportamientos al interactuar con el mundo físico. Esto puede hacer que la IA se comporte de manera indeseable. Por ejemplo, los chatbots pueden aprender a responder con lenguaje abusivo o racista cuando se sortean cuidadosamente las protecciones mediante indicaciones maliciosas.
«En su mayor parte, los desarrolladores de software necesitan que más personas usen su producto para que pueda mejorar con la exposición», dijo Vassilev. «Pero no hay garantía de que la exposición sea buena. Un chatbot puede generar información negativa o tóxica cuando se le indica con un lenguaje cuidadosamente diseñado».
En parte porque los conjuntos de datos utilizados para entrenar una IA son demasiado grandes para que las personas los supervisen y filtren con éxito, todavía no hay una forma infalible de proteger la IA contra el desvío. Para ayudar a la comunidad de desarrolladores, el nuevo informe ofrece una visión de los tipos de ataques que podrían sufrir sus productos de IA y enfoques correspondientes para reducir el daño.
El informe considera los cuatro principales tipos de ataques: evasión, envenenamiento, privacidad y ataques de abuso. También los clasifica según múltiples criterios, como los objetivos y metas del atacante, las capacidades y el conocimiento.
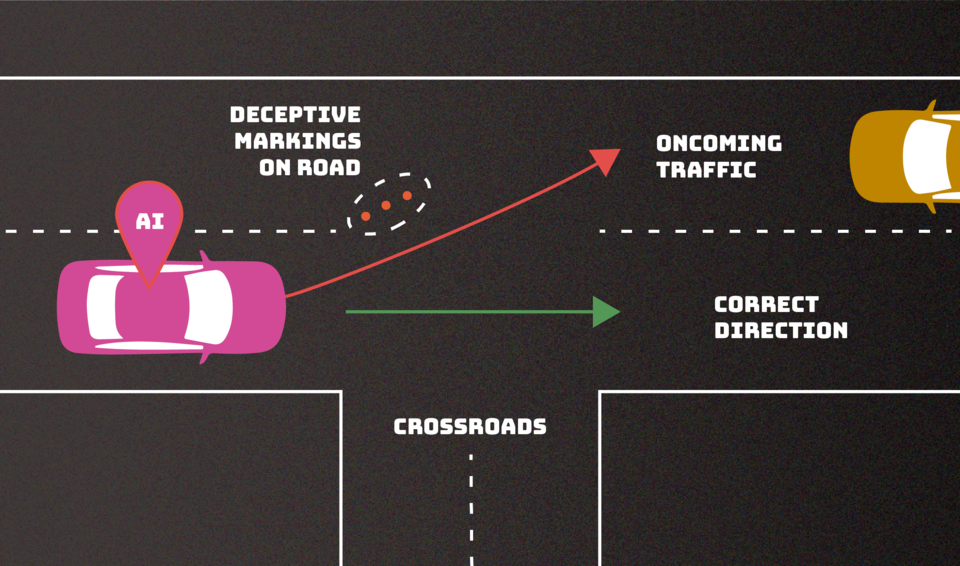
- Los ataques de evasión, que ocurren después de que se implementa un sistema de IA, intentan alterar una entrada para cambiar cómo el sistema responde a ella. Ejemplos incluirían agregar marcas a señales de alto para hacer que un vehículo autónomo las interprete como señales de límite de velocidad o crear marcas de carril confusas para hacer que el vehículo se desvíe de la carretera.
- Los ataques de envenenamiento ocurren en la fase de entrenamiento al introducir datos corruptos. Un ejemplo sería deslizar numerosas instancias de lenguaje inapropiado en registros de conversaciones, para que un chatbot interprete estas instancias como parloteo lo suficientemente común como para usarlo en sus propias interacciones con clientes.
Los ataques de privacidad, que ocurren durante la implementación, son intentos de aprender información sensible sobre la IA o los datos en los que se entrenó para mal usarla. Un adversario puede hacerle numerosas preguntas legítimas a un chatbot y luego utilizar las respuestas para ingeniería inversa del modelo para encontrar sus puntos débiles o adivinar sus fuentes. Agregar ejemplos indeseados a esas fuentes en línea podría hacer que la IA se comporte de manera inapropiada, y hacer que la IA olvide esos ejemplos específicos no deseados después del hecho puede ser difícil.
Los ataques de abuso implican la inserción de información incorrecta en una fuente, como una página web o un documento en línea, que una IA luego absorbe. A diferencia de los ataques de envenenamiento mencionados anteriormente, los ataques de abuso intentan darle a la IA piezas incorrectas de información de una fuente legítima pero comprometida para cambiar el uso previsto del sistema de IA.
«La mayoría de estos ataques son bastante fáciles de llevar a cabo y requieren un conocimiento mínimo del sistema de IA y capacidades adversarias limitadas», dijo la coautora Alina Oprea, profesora en la Universidad Northeastern. «Los ataques de envenenamiento, por ejemplo, pueden llevarse a cabo controlando unas pocas docenas de muestras de entrenamiento, lo que sería un porcentaje muy pequeño de todo el conjunto de entrenamiento».
Los autores, que también incluyeron a los investigadores de Robust Intelligence Inc., Alie Fordyce e Hyrum Anderson, desglosan cada una de estas clases de ataques en subcategorías y agregan enfoques para mitigarlos, aunque la publicación reconoce que las defensas que los expertos en IA han ideado contra ataques adversarios hasta ahora son incompletas.
