![]()
HTRC Extracted Features Dataset
https://analytics.hathitrust.org/datasets
Este conjunto de datos proporciona a los investigadores acceso abierto a los datos extraídos de los volúmenes a texto completo de la Biblioteca HathiTrust Digital Library a una escala sin precedentes. Esta versión proporciona una manera novedosa y eficaz de extraer, generar y reutilizar los datos relevantes de un corpus de 13,5 millones de libros.
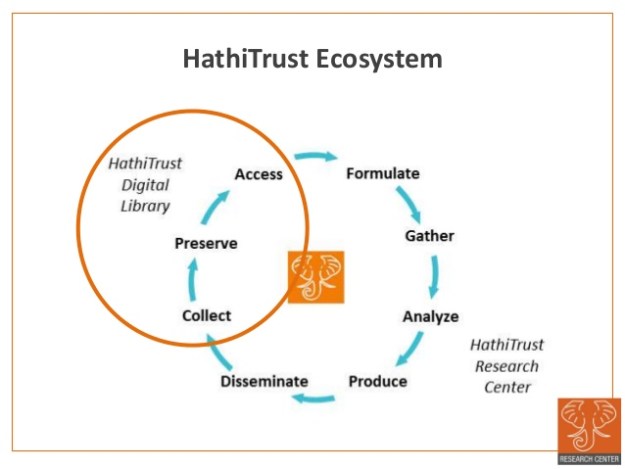
La palabra Hathi, pronunciado en indú “hah-tee”, significa en urdu elefante, motivo que representa su logotipo, el nombre se asigno por ser un animal famoso por su capacidad de memoria a largo plazo, sugiriendo la idea de preservación para el futuro, que es el objetivo del proyecto. HathiTrust es un proyecto de repositorio colaborativo a gran escala de contenidos digitales de las bibliotecas de investigación, incluyendo el contenido digitalizado a través de Google Books, así como contenidos digitalizados localmente por las bibliotecas, y ofrece una serie de servicios de localización y acceso, en particular búsqueda de texto completo a través de todo el repositorio.
HathiTrust anuncia hoy el lanzamiento de un conjunto de datos abierto significativamente expandido con HathiTrust Research Center (HTRC) Extracted Features (EF) Dataset, Version 1.0. Los datos corresponden a 13,7 millones de volúmenes de la biblioteca HathiTrust que están en dominio público.
Fundado en 2008 y alojada en la Universidad de Michigan, HathiTrust preserva y proporciona acceso a millones de libros y revistas digitalizados de las colecciones de más de 120 instituciones académicas y socios de investigación a través de su repositorio digital certificado de confianza. Incluye tanto materiales protegidos como de dominio público de los programas de digitalización masiva y de las iniciativas locales de digitalización de las instituciones asociadas al programa. El Centro de Investigación HathiTrust es un servicio de investigación avanzada de HathiTrust y un centro de investigación colaborativo lanzado conjuntamente por la Universidad de Indiana y la Universidad de Illinois.
El conjunto de datos abre la colección completa de HathiTrust para investigar las tendencias históricas y culturales, temas emergntes dentro del corpus y la evolución de las palabras y las estructuras de escritura en publicaciones que datan del siglo XVI al final del siglo XX. El conjunto de datos EF proporciona información cuantitativa sobre el recuento de palabras y líneas, partes del discurso y otros detalles dentro de cada página de cada volumen del HTDL. Además de estas investigaciones a gran escala, el EF Dataset también permite a los investigadores analizar de cerca el contenido de un determinado volumen o subconjunto de volúmenes.
Los datos proceden de los 13,7 millones de volúmenes encontrados en el HTDL, representando más de 5 mil millones de páginas de más de 2 billones de fichas. Una liberación preliminar del EF Dataset, extraído de un subconjunto mucho más pequeño que comprende solamente la colección del dominio público de HathiTrust, que permite la la utilización por parte de eruditos en economía, historia, lingüística, estudios literarios y sociología, entre otros campos.