García Rodríguez, A., Gómez Díaz, R., Cordón García, J.A., Alonso Arévalo, J. (2014, diciembre). Donde viven las etiquetas : el etiquetado en los blogs de literatura infantil y juvenil. BiD: textos universitaris de biblioteconomia i documentació, 33.
Con el objetivo de analizar las prácticas del etiquetado en los blogs de literatura infantil y juvenil, se recopila un conjunto de blogs especializados y pertenecientes a diferentes categorías y se estudia cómo es el etiquetado. Entre otras variables, se analiza la ubicación de las etiquetas, la forma de presentación, el tipo de etiquetas más utilizadas, etc. Los datos analizados ponen de manifiesto que el etiquetado es una práctica cada vez más habitual en los blogs como recurso para organizar los contenidos y para recuperar la gran cantidad de información que estos generan. Además de aportar el análisis de las prácticas del etiquetado, se da una serie de recomendaciones para mejorar la asignación de etiquetas y favorecer la visibilidad de la información de este tipo de blogs.
Entre las herramientas de la LIJ 2.0 por su sencillez, economía y facilidad de difusión, los blogs se han convertido en el escaparate del género, en un lugar en el que esos autores «invisibles» que escriben para niños y jóvenes consiguen que se hable de sus títulos y se hacen visibles.

«Donde viven los monstruos» es un libro infantil escrito e ilustrado por Maurice Sendak.
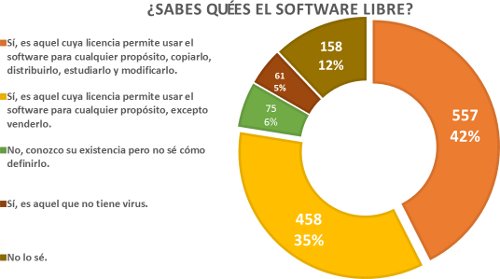
Leer un blog es una actividad consolidada, como lo demuestran los últimos datos sobre hábitos de lectura y compra de libros realizados por la Federación de Gremios de Editores de España (2012), que confirman que entre la población mayor de 14 años, el 46,9 % lee webs, blogs y foros, con una frecuencia al menos trimestral, un porcentaje que aumenta hasta el 77,9 % en la población de entre 14 y 24 años. En cuanto a la población de 10 a 13 años, el 40,7 % lee con frecuencia, al menos trimestral, webs, foros y blogs, y el 13,3 % participa en blogs y foros de cualquier tipo.
Las etiquetas son palabras del vocabulario que utiliza el usuario común, es decir, palabras sin ningún tipo de control terminológico que representan un contenido determinado (Gómez Díaz, 2012). Su finalidad es facilitar la recuperación del objeto al cual describen, por tanto, si están bien asignadas, aportan una valiosísima información sobre los términos, ya que representan, con el lenguaje del autor de la entrada del blog, el contenido. El problema es que en muchas ocasiones se pierde como punto de referencia que esa etiqueta sirve para la localización y recuperación de los contenidos del blog, y el resultado es un conjunto de etiquetas que, aunque describan el contenido, lo hacen de manera tan genérica que son muchas las entradas que utilizan la misma etiqueta, y por tanto el valor de discriminación de unos contenidos frente a otros se pierde. También puede suceder que la etiqueta solo tenga sentido para el autor que la asigna y no para los usuarios. Incluso puede ser ambigua porque represente varias realidades, o que la misma realidad sea representada con varias etiquetas, de manera que los contenidos que deberían mantenerse agrupados bajo la misma etiqueta aparezcan disgregados.
Tal y como afirman García y Rubio (2013, p. 65), «La utilización de las herramientas de la web 2.0, entre ellas los blogs, ha favorecido una mayor presencia de la LIJ en Internet y ha dado voz a una disciplina que, hasta no hace mucho, permanecía en la más absoluta invisibilidad. Internet se ha convertido en un espacio para intercambiar opiniones, promocionar y dar a conocer proyectos y experiencias, recomendar libros, fomentar la lectura…, un lugar en el que participan todos los agentes relacionados con el ámbito de los libros infantiles y juveniles, escritores, ilustradores, bibliotecarios, padres, maestros, editores, libreros y por supuesto, lectores».
Leer en un blog es una actividad consolidada entre niños y adultos, lo que ha dado lugar a que estos se hayan convertido en prescriptores de LIJ, en líderes de opinión sobre lecturas y en un recurso cada vez más utilizado para buscar información, de ahí la importancia de arbitrar mecanismos que favorezcan la recuperación de los contenidos, como hacen las etiquetas.
Dentro de los blogs, al igual que en el resto de las herramientas de la web social, el etiquetado se está convirtiendo en una práctica cada vez más habitual para organizar los contenidos, y como recurso por excelencia para recuperar la cada vez mayor cantidad de información que estos generan.
La asignación de etiquetas es común en los blogs de LIJ y también es frecuente que estas cumplan su función y aparezcan claramente visibles en las diferentes entradas. Sin embargo, la presentación de las etiquetas en el blog en forma de nube o lista no es tan usual según los ejemplos analizados.
La elección de los tipos de etiquetas cumple la función esencial de los blogs especializados, la reseña y recomendación de libros y la difusión de autores, ilustradores y títulos, de ahí que sean mayoritariamente utilizadas las referidas a autoría, contenido, género y materia.
Sin embargo, los administradores de los blogs no parecen preocuparse demasiado por evitar prácticas que en ocasiones pueden dificultar la recuperación de la información y la visibilidad de los términos en la nube, como pueden ser el uso indiscriminado de sinónimos, la utilización de diferentes lenguas para asignar las mismas etiquetas, errores tipográficos y ortográficos o las variadas formas de presentar los sintagmas nominales.
Aunque este tema no sea objeto de este trabajo, hay que tener en cuenta que el etiquetado sirve también para la recuperación no solo desde el propio blog, que es lo que se ha analizado aquí, sino que además es utilizado por los motores de búsqueda para la recuperación desde los buscadores.
El etiquetado tiene grandes posibilidades cara a la recuperación de la información y a potenciar la visibilidad, es conveniente realizarlo con cierto cuidado. Aunque es una práctica que no está normalizada, el uso de unas sencillas recomendaciones puede potenciar su utilidad.
Para ello, proponemos una serie de buenas prácticas que ayudarán al etiquetado en los blogs.
- Evitar etiquetas que solo encajen con un contenido, ya que los buscadores entenderán que tanto la página como el post de la etiqueta son un contenido duplicado y no se recuperará bien. Es recomendable que cada etiqueta se asocie a varias entradas.
- Evitar que las etiquetas sirvan para muchos contenidos, ya que esto provocará que la etiqueta pierda su valor de discriminación y el usuario tendrá dificultad para encontrar lo que busca.
- Adaptar la especificidad de la etiqueta al tipo de blog. Por ejemplo, en un blog sobre literatura infantil la etiqueta libros para niños es muy genérica, mientras que puede ser específica en un blog de literatura en general, independiente del número de entradas con las que coincida.
- No abusar del número de etiquetas asociadas a cada entrada, generalmente 4 o 5 suelen ser suficientes. A medida que aumenta el número de etiquetas es más fácil dispersar el contenido.
- Utilizar siempre las palabras de la misma manera, en singular o en plural, porque, si no, el lector se verá obligado a buscar lo mismo en varias etiquetas.
- Incluir una lista de etiquetas o una nube para que los usuarios sepan las que se han utilizado.
- Poner la lista o la nube en un lugar bien visible, preferentemente en uno de los márgenes laterales, en la parte superior.
- Indicar cuántos posts tiene cada etiqueta para que los usuarios conozcan los temas habituales del blog.