
72 Ebooks gratis para Traducción, Información y Documentación
feb-marz 2016
Más
libros GRATIS
72 Ebooks gratis para Traducción, Información y Documentación
feb-marz 2016
Más
libros GRATIS

Managing and sharing data best practice for researchers. [e-Book] Essex, University of Essex, 2011.
Las iniciativas de las instituciones de educación superior y organismos de apoyo siguen el juego y el enfoque en el desarrollo de las infraestructuras de intercambio de datos; apoyo a los investigadores para gestionar y compartir datos a través de herramientas, orientación y formación práctica; y permitir que la citación y vinculación de los datos con publicaciones aumente la visibilidad y accesibilidad de los datos y la investigación misma. Mientras que la buena gestión de los datos es fundamental para los datos de investigación de alta calidad y, por tanto, la investigación de excelencia, es crucial para facilitar el intercambio de datos y asegurar la sostenibilidad y la accesibilidad de los datos a largo plazo y por lo tanto su reutilización para la ciencia futura.


Research data life cycle
Johnsson, M. and J. Ahlfeldt (2015). [e-Book] Research Libraries and Research Data Management within the Humanities and Social Sciences Lund, Lund University, 2015
Cada vez se pone mayor énfasis en la apertura de datos, gestión de datos planos, y en la investigación en torno a ”Big data”, lo que está impulsando a las instituciones académicas a desarrollar y desplegar nuevas iniciativas. El análisis de las necesidades de datos de los investigadores a través de dominios institucionales puede requerir de la participación de la biblioteca para identificar y conectar a los investigadores en todas las unidades funcionales, tanto formales e informales para compartir, analizar, y reutilizar datos. La investigación sobre la gestión de datos de investigación es uno de los retos futuros que deberemos asumir las bibliotecas de investigación. Se trata de una nueva forma de organizar la información que exige esfuerzos importantes en el aprendizaje de nuevos sistemas, métodos de trabajo y colaboración con los agentes implicados. Aquí se presenta el proyecto sobre Research Data Management (RDM) de la Universidad de Lund en Suecia.
El aumento del volumen y orrganización de la información capturada por las empresas y organizaciones, el aumento de los multimedia, las redes sociales y la “Internet de las cosas” van a impulsar un crecimiento exponencial de los datos en el futuro. Datos de registros de llamadas, transacciones de banca móvil, contenido generado por el usuario de internet, tales como blogs y tweets, búsquedas en línea, imágenes de satélite, etc. es información procesable que requiere el uso de técnicas computacionales para dar a conocer las tendencias y patrones dentro de y entre éstos extremadamente grandes conjuntos de datos socioeconómicos. Las bibliotecas de investigación juegan un papel vital en la gestión y curación de este tipo contenido, pero requieren de mecanismos de financiación adecuados.
La Ciencia Datos se refiere a un área emergente de trabajo se ocupa de la recogida, preparación, análisis, visualización, administración y conservación de grandes colecciones de información. Casi todos los analistas consideran “Big Data” como una de las tendencias de futuro que tendrán que tener en cuenta la mayoría de las empresas e instituciones. La sociedad TIC propicia y requiere un diluvio universal de datos, procesarlos, entenderlos y transformarlos en decisiones de valor es el reto del análisis big data. Vital para las empresas cuyo activo es la información.
Gestión de Datos de Investigación (RDM) es un proceso que está diseñado para gestionar y difundir conjuntos de datos de alta calidad, que cumplan con los requisitos académicos, legales y éticos. Hay dos salidas del proceso de RDM:
1. La preservación a largo plazo de los conjuntos de datos mediante sistemas de almacenamiento
2. Compartir y reutilización de los conjuntos de datos para la investigación y otros fines en la sociedad en general.
Esta propuesta hace hincapié en la creación de una organización coherente de gestión de datos de investigación en la Universidad de Lund, que utiliza los recursos existentes tanto dentro como fuera de la universidad y establece nuevas unidades de organización y sistemas de información específicos para esta nueva tarea. Se propone la creación de una nueva unidad para la Gestión de Datos de Investigación y Coordinación en la biblioteca de la universidad cuya responsabilidad sería la de coordinar la red de agentes existentes que apoyen las actividades de investigación desde los diferentes centros de manera ética, por parte de expertos en gestión de datos.

Además, se propone la creación de un nuevo sistema de información, “Lund University Dataset Directory”, un directorio de grupos de datos facilitaría la gestión de bases de datos y recuperación de la información en todo el ciclo de vida de los datos.
El objetivo es que los conjuntos de datos de investigación sean depositados en repositorios para compartir a nivel nacionales o disciplinarlo que requerirá – al igual que las tecnologías de la web semántica – de servicios de datos en línea no previstos aún por los agentes nacionales, por lo que para ello será necesario crear un laboratorio de datos dentro de la red RDM en la Universidad de Lund.
Ver además
Analytics: el uso de big data en el mundo real. Cómo las empresas más innovadoras extraen valor de datos inciertos [e-Book] IBM Institute for Business Value, 2014 Texto completo
Whyte, A. (2015). ‘Where to keep research data: DCC checklist for evaluating data repositories’ v.1.1 Edinburgh: Digital Curation Centre, 2015 Texto completo
Wanner, Amanda. Data literacy instruction in academic libraries: best practices for librarians. Archival and Information Studies Student Journal 2015 Texto completo
Erway, R. and A. Rinehart (2016). [e-Book] If You Build It, Will They Fund? Making Research Data Management Sustainable OCLC, 2016.Texto completo
Otros post relacionados

Tananbaum, G. (ed.). [e-Book] North American Campus-Based Open Access Funds: A Five-Year Progress Report, SPARC, 2014
Guía
Campus Open Access Funds Guide
En 2009 SPARC lanzo el proyecto “Campus-Based Open Access Funds”, con el mismo se tenía la intención de proporcionar información para la creación de un fondo de financiación del acceso abierto (OA) en instituciones que ya tenían en marcha un un proyecto en funcionamiento.
“Campus-Based Open Access Funds” es un fondo constituido por una institución específicamente para cubrir los costos de los investigadores que publican en revistas con cargos de procesamiento por artículo (APC). El objetivo fundamental de un fondo de financiación del acceso abierto es apoyar modelos de publicación que permitan la distribución gratuita inmediata en línea y el acceso a la investigación académica.
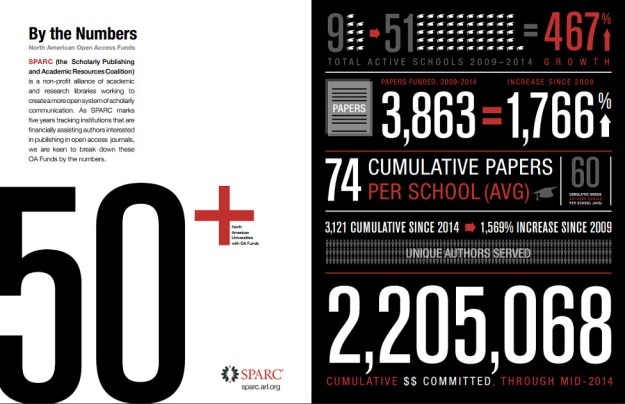
Este documento trata de aprender más acerca de las oportunidades que estos fondos podrían proporcionar para constituir modelos viables de financiación del acceso abierto. Se recoge importante información sobre los antecedentes, recursos prácticos, directrices, políticas, y datos que documentan la evolución de la financiación del OA a través de estos fondos. A medida que se acerca el quinto aniversario de este proyecto, SPARC publica el informe sobre la situación para evaluar los logros cuantitativos, así como aquellas áreas en las que se aportaron datos sobre el potencial de estos fondos.

Paul, R. and L. Elder [e-Book] The Miniature Guide to Scientific Thinking : Concepts & Tools, Foundation for Critical Thinking, 2003.
Esta guía sistematiza la esencia de los conceptos de pensamiento científico y herramientas para la investigación. Se puede utilizar como un suplemento a cualquier libro de texto para cualquier clase sobre investigación científica en cualquier disciplina. La esencia de los conceptos de pensamiento científico y herramientas se centra en las habilidades intelectuales inherentes al pensador científico bien cultivado.

Paul, R. and L. Elder (2014). [e-Book] The Miniature Guide to Critical Thinking Concepts & Tools, Foundation for Critical Thinking, 2008.
El pensamiento crítico es un proceso que se propone analizar, entender o evaluar la manera en la que se organizan los conocimientos que pretenden interpretar y representar el mundo, en particular las opiniones o afirmaciones que en la vida cotidiana suelen aceptarse como verdaderas. Se define, desde un punto de vista práctico, como un proceso mediante el cual se usa el conocimiento y la inteligencia para llegar de forma efectiva, a la postura más razonable y justificada sobre un tema (Wikipedia).
Todos pensamos está en nuestra naturaleza hacerlo. Pero gran parte de nuestro pensamiento se abandonada en sí misma, está sesgado, distorsionado y es parcial, y a veces estamos desinformados o tenemos prejuicios. Sin embargo, la calidad de nuestra vida y la de lo que producimos viene marcada la calidad de nuestro pensamiento. El pensamiento de mala calidad es costoso, tanto en dinero como en calidad de vida. La excelencia en el pensamiento, sin embargo, debe ser cultivada de manera sistemática. El pensamiento crítico es el arte de analizar y evaluar el pensamiento con el fin de mejorarlo. El pensamiento crítico es, auto-dirigido, auto-disciplinado, auto-monitoreado, y el pensamiento requiere de ser auto-corregido. Requiere rigurosos estándares de excelencia y dominio consciente de su uso. Ello implica una comunicación efectiva y habilidades de resolución de problemas y un compromiso para superar nuestro egocentrismo nativo y sociocentrismo.
Esta guía en miniatura, es ampliamente utilizado en la enseñanza y el aprendizaje, en la vida personal y profesional. En ella se esboza la esencia de lo que es el pensamiento crítico en un 24 páginas a través de la compleja interrelación existente entre los conceptos de pensamiento crítico y principios implícitos.las competencias sobre pensamiento crítico se aplican a todos los sujetos. por ejemplo, lógicamente a los pensadores que deben se mostrarse siempre críticos en cuanto a la propia finalidad de cuestionarse los distintos puntos de vista sobre un tema o cuestión, y deben esforzarse en ser claros, exactos, precisos y relevantes, ya que buscan pensar sobre lo que se ve como lógico y justo. Estás competencias se aplican tanto a la lectura como a la escritura, igualmente que para hablar y escuchar. El pensamiento crítico es transversal, y se utiliza en todas las disciplinas: historia, ciencias, matemáticas, la filosofía y artes; y tanto en en la vida profesional y personal.

En el mundo de las bibliotecas hemos empezado a hablar de pensamiento crítico con la puesta de relieve de los programas de Alfabetización Informacional (ALFIN). La definición canónica de que es ALFIN dice que La alfabetización informacional consiste en adquirir la capacidad de saber cuándo y por qué necesitas información, dónde encontrarla, y cómo evaluarla, utilizarla y comunicarla de manera ética para el fomento de la autonomía del individuo y el desarrollo de su CAPACIDAD CRÍTICA en una sociedad compleja, necesitada de implicación y participación democrática.
Saber leer es sólo el comienzo de la misma – saber cómo enmarcar una pregunta, plantear una consulta, la forma de interpretar los textos que encuentras, cómo organizar y utilizar la información que descubres, cómo entenderla y como utilizarla para generar nuevo conocimiento es la esencia de lo que denominamos Alfabetización Informacional.
En esencia el pensamiento crítico tiene como objetivo asegurar que tenemos buenas razones para nuestras creencias. Pero ¿qué significa eso? De una manera fácil de entender se trataría de qué cuando alguien nos está tratando de convencer sobre algo, debemos pensar qué razones han llevado a creer lo que esta persona quiere que yo crea. ¿Se trata de buenas razones? Esto es de forma muy gráfica que significa pensamiento crítico y lógico.
Según la Universidad de Aucklan existen algunos obstáculos comunes para pensar de una manera lógica y crítica:

La cuestión de la identidad digital y e-reputación es central en el ecosistema de Internet de hoy en día, tanto en términos de uso individual como colectivo. Una identidad digital se compone de la suma total de las huellas digitales relacionadas con un individuo o una comunidad: las huellas es el «perfil» que corresponde a lo que digo sobre mi (que soy); cuando «Navegamos» trazamos que sitios hemos visito, comentamos o compramos (cómo me comporto); y, finalmente, dejamos por escrito huellas enunciativas – lo que publico en mi blog, por ejemplo – que reflejan directamente mis ideas y opiniones (lo que pienso).
Más precisamente, la identidad digital se puede definir tanto como la colección de trazas (escritos, audio / vídeo, mensajes de contenido del foro, detalles de acceso, etc.) que dejamos detrás de nosotros, consciente o inconscientemente, ya que al navegar por la red, dejamos el reflejo de esta masa de rastros tal como aparece después de haber sido «remezclado» por los motores de búsqueda.
Mi identidad digital incluye lo siguiente: dirección IP; cookies; mensajes de correo electrónico; nombre de pila; apellido; nombres de usuario; personal, administrativo, bancario, detalles profesionales y sociales; fotos; avatares y logotipos; etiquetas; vídeos; artículos; comentarios en foros; datos de geolocalización, etc.

Huella y reputación digital a veces se utilizan indistintamente, aunque existen matices. La reputación digital es un complemento para la identidad digital, mi reputación digital o e-reputación, corresponde a lo que otros dicen de mí. También puede ser mi «marca» (en cuyo caso hablamos de la marca personal). Es necesariamente subjetiva y fluctuante. En base a la imagen percibida, sino también en relación a la confianza y la credibilidad, ya que puede desenmarañar con una rapidez inversamente proporcional al tiempo que se necesita para establecerla y construirla.
¿Dónde están mis detalles de acceso?
Con la proliferación de servicios en línea se da un crecimiento exponencial de los sistemas de inicio de sesión, es decir, un nombre de usuario y la contraseña que se proporciona emparejada al acceso a esos servicios. No es raro que un individuo posea varias decenas de nombres de usuario y contraseñas diferentes. Tantos, de hecho, que hemos sido testigos de la aparición de programas de software especialmente diseñados para manejar mejor todas estas identidades múltiples de inicio de sesión.
Hoy en día, más y más servicios en la Web han optado por simplificar la tarea a sus usuarios mediante la suscripción de un único punto de acceso conocido como OpenID, en el que un único nombre de usuario y contraseña permiten a los usuarios acceder a sus mensajes de correo electrónico, el panel de su blog, su Facebook o cuenta de Twitter. en este sentido el sistema «Do Not Track» es un estándar desarrollado para los navegadores por el W3C que puede utilizarse en distintos navegadores (Firefox, Google Chrome, Internet Explorer) sirve para establecer la gestión «nativa» de inicio de sesión además de proteger la privacidad de sus usuarios, ofreciendo modos de navegación privada que no almacenan la datos de conexión habitual.

Al llevar a cabo una búsqueda en Google nos da la ilusión de una página en blanco que no contiene nada más que el campo de búsqueda. Sin embargo a partir de este momento, e incluso cuando navegamos en el motor de búsqueda, Google sabe lo que somos y cual es nuestra identidad, compila todas nuestras solicitudes de búsqueda y el acceso a todos y cada mensaje que hemos enviado o recibido.
Cuando dejamos iniciada una sesión en un servicio antes de usar otro, en alguna manera estamos bajando la guardia ya que los motores de búsqueda analizan esta correlación. Es por eso que los rastros que de manera inconsciente dejamos en la red son fundamentales para la definición de la identidad digital.
La práctica de identificar y localizar a los usuarios es justificada por la mayoría de las compañías de Internet como la única manera de proporcionar una experiencia de navegación enriquecida para personalizar el servicio ofrecido. Si bien este argumento se puede justificar en términos técnicos, no exime a esas mismas empresas de proporcionar garantías con respecto a la cantidad de tiempo que conservan estos datos personales, y cómo se utiliza. Cuando añadimos estas aplicaciones a nuestro perfil, los anunciantes son capaces de aprender acerca de nuestras preferencias y gustos, incluso sobre toda una parte importante de nuestra vida privada, a veces incluso incluyendo nuestras relaciones íntimas.

Todos los días producimos y reproducimos una cantidad fenomenal de huellas digitales. Del mismo modo que el volumen de documentos web se multiplicó exponencialmente hace unos años, hoy en día estamos asistiendo a una nueva explosión: la huella de identidad. Nuestras prácticas diarias de publicación en línea consisten en la posibilidad de subir fotos a Flickr o Picasa, la publicación de comentarios diarios en Facebook o Twitter, subir vídeos a YouTube. También compartimos marcadores en Delicious vs Diigo, subimos archivos de documentos a Google, leemos y emitimos correos electrónicos en los servicios de correo web, hacemos post en nuestros blogs, artículos en periódicos, publicaciones académicas en los repositorios de acceso abierto y revistas en línea, compramos libros en plataformas de editores, etc. Además nuestras prácticas como usuarios también se han multiplicado como resultado de las estrategias de sincronización ofrecidas por la mayoría de los principales ecosistemas de información en la red: Por ejemplo comenzamos la lectura de un documento en mi tableta de pantalla táctil del móvil en el transporte público, luego seguimos leyendo el mismo documento en el lugar donde lo dejamos en el ordenador personal en casa o a través de un servicio de suscripción tales como Amazon, Google Play o iTunes. Con todo ello estamos documentando nuestra identidad digital, literalmente, duradera y cada vez más transparente, formando parte de ella tanto los documentos que producimos, como lo que dicen de nosotros dentro de las interfaces de los motores de búsqueda y redes sociales.
El control de nuestra identidad
Una de las cuestiones más importantes en lo que se conoce como la «sociedad de la información» es que en cierta manera permite a todos y cada uno de nosotros invertir esta tendencia entre lo vivido y lo percibido de la identidad digital, y en alguna manera poder retomar el control, para medir el alcance de nuestras huellas de identidad como una conjunto y, si lo deseamos, delimitar sus perímetros.
La identidad digital va de la mano con lo que los psicólogos llaman «escopofilia», o el deseo de ver, junto con el deseo de ver sin ser visto, o, a la inversa, de existir al ser visto, son estos impulsos psicológicos, que van desde la mera falta de cuidado a la falta de modestia al por mayor, que provocan las huellas digitales que dejamos detrás de nosotros al ignorar o rechazar la admisión, o su potencial para causarnos algún daño.
Identidad vitro y post mortem.
La identidad digital ahora trasciende las fronteras de la vida biológica. Un estudio de AVG que data de octubre de 2007 ha demostrado que el 81% de los niños menores de dos años ya tienen una presencia digital, es decir, una o varias fotos publicadas en las redes sociales por sus propios padres … Y después de la muerte Por ejemplo, http://www.laviedapres.com. En Facebook, cuando un miembro de la red social muere, puede rellenar un formulario para que sus «amigos» sepan que el perfil del fallecido se puede congelar y se transforma en un «memorial digital» en la que estos mismos «amigos» pueden dejar mensajes. Otras empresas han hecho negocio de la gestión de nuestro identidad digital post mortem.
La interconexión es un peligro para la identidad
No hace mucho tiempo, en un mundo en gran medida desconectado, nuestra identidad parecía protegida. Sólo unos pocos años más tarde, en un mundo en gran medida conectado, nuestra identidad a veces está peligrosamente expuesta. Hoy en día vivimos en un mundo de hiper-proximidad, conectividad permanente y, tecnología ubicua nómada. En este mundo, nuestra identidad está en peligro si no ponemos garantías en su lugar. O, más precisamente, nuestra identidad puede poner en peligro de forma permanente nuestras relaciones sociales, tanto en el mundo físico como en el digital. Esto es se atestigua con los numerosos casos de personas que están siendo despedidos del trabajo después de usar la mayor red social del mundo demasiado ingenuamente.
El psicólogo Abraham Maslow describe el proceso típico de construcción de identidad entre los usuarios. Este proceso puede transponerse en el mundo digital. En la parte inferior es la necesidad de «seguridad», es decir, la necesidad de elegir un nombre de usuario. Luego viene la necesidad de amor y pertenencia, que puede ser canalizada en cualquier sitio de la comunidad. Después de esto es la necesidad de ser tenido en alta estima por los demás, que nos lleva a utilizar diversas estrategias para construir y gestionar nuestra «reputación» digital. Por último, existe la necesidad de autoestima, en otras palabras, el narcisista que sustenta y completa cualquier estrategia de presencia o de identidad en la Web, es decir, la auto-realización, que puede definirse como la armonía entre la identidad percibida y deseada de una persona o empresa.
Control y gestión de la identidad digital
Por otra parte está la parte positiva. Una de las cuestiones planteadas por la identidad digital en la Web es saber qué estrategias de identidad escoger. Para las individuos, empresas, e instituciones lo que más importa es el fortalecimiento de su identidad con fines de visibilidad, económicos, o sociales. Ello supone disponer de un gran activo de la red donde se hacen más visibles nuestras opiniones, escritos, investigaciones, productos, relaciones sociales e intereses, para ello existe toda una gama de herramientas para medir el perímetro de la identidad digital de una persona o entidad, poner en práctica estrategias de reputación o simplemente comprobar la disponibilidad de un nombre o marca en un determinado servicio, sitio web o red social. La forma más sencilla de ver nuestra identidad en línea es escribir nuestro nombre en Google u otro motor de búsqueda de uso general. Esto nos permitirá identificar los sitios en los que aparece nuestro nombre dentro de nuestro control, además de obtener también algunas huellas de identidad que escapaban a nuestro control, es decir lo que otros dicen de nosotros, de nuestra institución, marca o negocio.
Varios sitios actúan como «agregadores», en otras palabras, recuperan información con nuestro nombre de diferentes fuentes y presentan esta información de forma sinóptica. El más conocido de estos sitios fue 123people.com, donde aparece la dirección (recuperada de las páginas amarillas), fotos asociadas a un nombre (tomadas de Flickr o Google), artículos (publicados en mi sitio web, repositorio o blog), los nombres de dominio «Soy dueño» (o puedo comprar), videos (recuperados de YouTube), y los «contactos» (extraídos de los sitios de redes sociales que autorizan esta práctica). La eficacia de estas herramientas se correlacionan de forma natural con la actividad real en línea y la presencia, además de la configuración de privacidad que hemos elegido para diferentes cuentas.
Y si realmente quiero saber todo sobre una persona están los llamados “Neighbourhood search engines” (Motores de búsqueda de Vecindad). Aunque estos actualmente sólo están disponible en los Estados Unidos y son de pago Intelius.com y Everyblock.com proporcionan información muy detallada sobre un individuo dado, como su dirección y número de la seguridad social, las fechas de su matrimonio y, o divorcio, los nombres y números de teléfono de sus vecinos, el valor de las propiedades que poseen, así como la fecha en que lo compró, el tamaño de la parcela sobre la que se construye su casa, una imagen de satélite de su casa, la edad media de las personas que viven en su barrio. El coste de estos servicios varía de 2$ a más de 50$.En los Estados Unidos, tal información es de libre acceso en diferentes bases de datos gubernamentales. No hay necesidad de contratar a detectives privados para averiguar esta información.
Para aquellos que deseen vigilar rigurosamente los perímetros de su identidad en línea y seguimiento de las menciones de su nombre, incluso en los foros de discusión más oscuros, se necesita un enfoque más preciso y sistemático. En la actualidad hay soluciones profesionales de software especialmente diseñadas para llevar a cabo este tipo de monitorización o vigilancia de un nombre o denominación. estas herramientas exploran sistemáticamente lo que se conoce como la Web «invisible», que va de los foros de discusión de las bases de datos del gobierno. La reputación en línea se ha convertido en un mercado muy competitivo, con empresas dedicadas a la «gestión de la imagen y la protección», la «influencia», «limpieza» y «análisis de de la marca». Los servicios que ofrecen se obtienen mediante una suscripción anual que va desde 15 € al mes para mantenerse al tanto de lo que otros dicen de mí (o mi negocio) en la Web, a una suscripción de 100 € al año se nos permite trabajar una «buena» reputación, o incluso – y esta es una opción muy popular entre los padres norteamericanos – que se le mantenga informado de la actividad en línea de los hijos (sus amigos en Facebook, la fotos que publican, los mensajes que envían y reciben, etc.).
Potenciación de la Identidad digital en el contexto académico
Por otro lado, la cuestión de la identidad varía de una red a otra. La cuestión del anonimato, por ejemplo, está ausente en las redes sociales profesionales donde los usuarios muestran su CV precisamente para que sea conocido y dar visibilidad y reputación a nuestros contenidos. Es el caso de las redes sociales científicas como Research Gate, Academia.edu, etc. Este proceso está teniendo su incidencia en la necesidad de que los investigadores conozcan, utilicen y gestionen los mecanismos de valoración, acreditación y potenciación de la visibilidad científica de sus publicaciones, lo que a su vez incide en el desarrollo de la carrera personal del investigador, pero también de manera colectiva en la calidad de las propias universidades, cuya medición se basa fundamentalmente en los ranking elaborados a partir de los propios datos de investigación de sus académicos. Todo ello está poniendo de relieve la importancia más que nunca la necesidad por parte de quienes investigan de conocer los mecanismos de edición, comunicación, medición y promoción.
Sin lugar a dudas la mayor parte de los investigadores han trasladado sus actividades de investigación a la web y con el éxito de los medios sociales esta situación se ha hecho más evidente, ya que estas herramientas tienen más potencialidad para desarrollar un rango mayor de influencia académica que los entornos tradicionales de publicación. Han surgido cientos de plataformas que permiten compartir libremente todo tipo de información y conectarnos a través de redes. Estas nuevas herramientas generan estadísticas de actividad e interacciones entre sus usuarios tales como menciones, retweets, conversaciones, comentarios en Blogs o en Facebook; gestores de referencias que muestran índices de popularidad de las referencias más compartidas por otros investigadores o repositorios que generan estadísticas de visitas, o descargas de artículos.
Herramientas como Altmetric.com bajo suscripción, muestran el impacto de la investigación a sus autores y lectores de modo muy gráfico y nuevo. Monitorear, buscar y medir todas las conversaciones acerca de los artículos de una revista, así como los publicados por sus competidores. Recoge las menciones de artículos académicos de todas partes de la Web mediante la recopilación de menciones en los periódicos, blogs, redes sociales y otros sitios web. En cuestión de minutos, permite al autor disponer de los datos altmetrics para mostrarlos en su plataforma o aplicación.
La reputación científica es esencial para los investigadores, contribuye a su progreso, reconocimiento, obtención de subvenciones y de becas de investigación académica. Esta se basa fundamentalmente en los indicadores cuantitativos, como el Índice H, el número de citas, el número de artículos y otros indicadores. La Web nos permite, casi de forma gratuita, trabajar juntos, difundir nuestra investigación y llegar a los colegas de todo el mundo. Nada es más fácil que buscar en la Web. Es de reconocimiento casi común que la Web es actualmente el entorno propio de la investigación, y que el buen contenido combinado con los esfuerzos de difusión adecuados hará que una investigación sea potencialmente visible lo cual provocará una retroalimentación (feedback) que generará una capacidad por parte del investigador de tomar el control de la reputación y la difusión de su trabajo.La reputación digital puede ser potenciada y gestionada, por ello es importante que el investigador conozca los diferentes canales y destrezas para gestionar su visualización y posicionamiento. El investigador puede encontrar un aliado en el propio bibliotecario.
La firma es un elemento identitario único para el investigador. Sin embargo frecuentemente el nombre de un investigador aparece bajo innumerables formas que producen un importante efecto sobre el impacto de las publicaciones. Por ello es necesario establecer una forma única de identidad. En los últimos años han surgido sistemas que intentan paliar esta situación creando un sistema global de identificación de autores. Es el caso de Open Researcher and ContributorID (ORCID) un proyecto abierto, sin ánimo de lucro, comunitario, que ofrece un sistema para la identificación inequívoca de investigadores y un método claro para vincular las actividades de investigación y los productos de estos identificadores. ORCID tiene una habilidad única para llegar a todas las disciplinas y sectores de investigación, cruzar fronteras nacionales y cooperar con otros sistemas de identificación. ORCID proporciona un identificador digital persistente que distingue a un investigador de todos los otros investigadores garantizando que el trabajo de un investigador sea reconocido como suyo, con la posibilidad de ser vinculado a otros identificadores como Scopus, ResearcherID, Author Resolver, Inspire, IraLIS, RePEc, o LinkedIn. Orcid también se vincula a la producción de los investigadores facilitando conocer sus publicaciones, identificando colaboradores y revisores y en definitiva, favoreciendo el proceso de descubrimiento científico. Además el investigador puede incluir su identificador ORCID en su sitio web, al presentar publicaciones, solicitar subvenciones, y en cualquier flujo de trabajo de investigación para asegurarse de obtener reconocimiento por su trabajo.
En resumen, la Investigación 2.0 es la aplicación de las tecnologías de la web social al proceso científico permitiendo que las personas se relacionen de manera fluida y que los datos se compartan de forma abierta. Las posibilidades que ofrecen las tecnologías participativas facilitan que los autores puedan compartir información, favorecer el descubrimiento científico y la visibilidad de la investigación a través de bases de datos, plataformas y servicios de apoyo a los procesos de una investigación.
Conclusión
En conclusión. los datos de nuestra identidad, y los medios por los que se accede a ellos, son naturalmente porosos. Los diferentes sitios en los que publicamos partes de nuestra identidad digital son cada vez más, y cada vez más sistemática e interconectada. por ejemplo, si estoy conectado a YouTube a través de Gmail, Google añadirá todos los vídeos que tengo en mi perfil a mis intereses.
Cada vez que entramos en una búsqueda en línea, actualizamos nuestro estado o escribimos en nuestro «muro», proporcionamos a los motores de búsqueda y redes sociales – más a menudo involuntariamente que voluntaria – una verdadera mina de información sobre lo que somos y cómo nos comportamos en línea. En última instancia, cada clic, de acción o comportamiento actúa como si fueran metadatos en una especie de panóptico global.
.
Recomendaciones bibliográficas

Olivier, E. (2016). [e-Book] What is digital identity?. OpenEdition Press, 2015.
How to Use for Business A Beginner’s Guide. Edtion ed.: HubSpot.com, 2012. <http://www.hubspot.com/Portals/53/docs/HowToUseTwitterForBusiness.pdf>.
Identidad Digital: El nuevo usuario en el mundo digital. Edtion ed. Madrid: Fundación telefónica, 2013. <http://www.fundaciontelefonica.com/arte_cultura/publicaciones-listado/pagina-item-publicaciones/?itempubli=229>.
Identidad Digital: El nuevo usuario en el mundo digital. . Edtion ed. Madrid: Madrid. Fundación Telefónica, 2013. <http://publiadmin.fundaciontelefonica.com/media/es/que_hacemos/media/publicaciones/identidad_digital.pdf?>.
ALONSO ARÉVALO, J., J. A. CORDÓN GARCÍA, R. GÓMEZ DÍAZ AND B. GARCÍA-DELGADO GIMÉNEZ Uso y aplicación de herramientas 2.0 en los servicios, producción, organización y difusión de la información en la biblioteca universitaria. Investigación Bibliotecológica, 2015/01/13/ 2015, 28(64). <http://www.revistas.unam.mx/index.php/ibi/article/view/45692>.
ALONSO-ARÉVALO, J. Alfabetización en Comunicación Científica: Acreditación, OA, redes sociales, altmetrics, bibliotecarios incrustados y gestión de la identidad digital. Alfabetización informacional: Reflexiones y Experiencias, 20 Y 21 de marzo del 2014. 2014. <http://eprints.rclis.org/22838/>.
ANDALIA, R. C., M. N. RODRÍGUEZ AND K. M. P. RODRÍGUEZ ORCID: en busca de un identificador único, permanente y universal para científicos y académicos. Revista Cubana de información en ciencias de la salud, 2014/11/27/ 2014, 26(1). <http://www.rcics.sld.cu/index.php/acimed/article/view/697>.
BURLAMAQUI, C. D. V. Pós-Modernidade e Fragmentação do Sujeito: globalização, identidade e transmidiação/ Postmodernity and Fragmentation of the Subject: globalization, identity and transmediation. Revista Hipertexto, 2011 2011, 1(2), 55-80. <http://www.latec.ufrj.br/revistas/index.php?journal=hipertexto&page=article&op=view&path%5B%5D=322>.
CASTAÑEDA, L. AND M. CAMACHO Desvelando nuestra identidad digital. El Profesional de la Información, 2012, 21(4), 354-360. <http://elprofesionaldelainformacion.metapress.com/app/home/contribution.asp?referrer=parent&backto=issue,4,17;journal,1,84;linkingpublicationresults,1:105302,1>.
ERTZSCHEID, O. Qu’est-ce que l’identité numérique? : Enjeux, outils, méthodologies. Edtion ed. Marseille: OpenEdition Press, 2013. 70 p. ISBN 978-2-8218-1338-0. <http://books.openedition.org/oep/332>.
ESPARZA, D. Crisis de identidad y revolución digital. Caracteres: estudios culturales y críticos de la esfera digital, 2012, 1(1), 77-85. <http://dialnet.unirioja.es/descarga/articulo/4228898.pdf>.
MAS, M. T. Gestores de información y reconocimiento social. BiD: Textos universitaris de biblioteconomia i documentació, 2014 2014, (32). <http://bid.ub.edu/es/32/taladriz2.htm>.
OLIVIER, E. Qu’est-ce que l’identité numérique ? Edtion ed. Marseille: OpenEdition Press 2013. ISBN 9782821813373. <http://books.openedition.org/oep/332>.
OLIVIER, E. What is digital identity? Edtion ed.: OpenEdition Press, 2016. <http://books.openedition.org/oep/1235>.

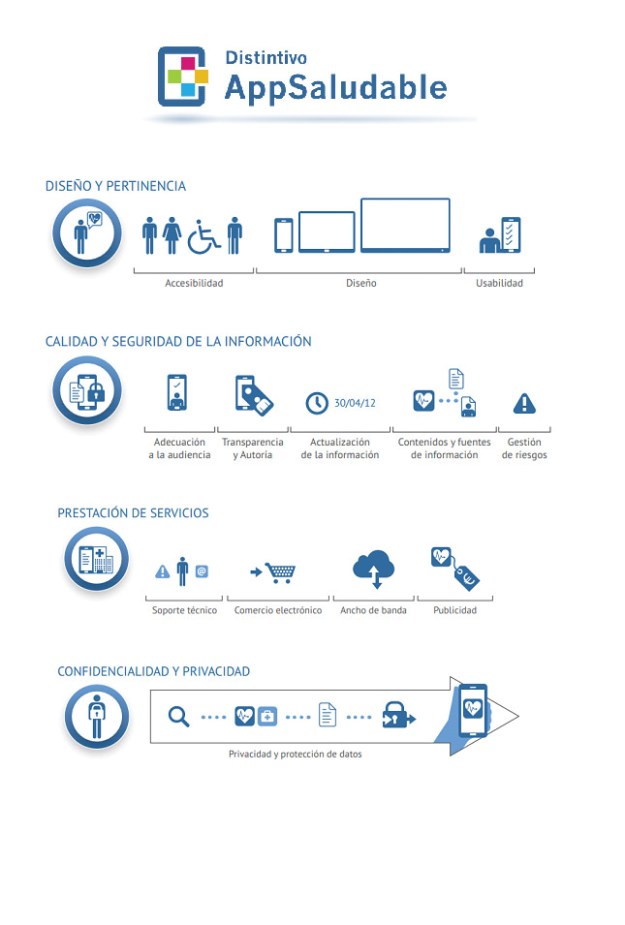
La Agencia de Calidad Sanitaria de Andalucía otorga el Distintivo AppSaludable http://www.calidadappsalud.com/, que es el primer sello en español que reconoce la calidad y seguridad de las apps de salud. Es un distintivo gratuito y abierto a todas las aplicaciones de iniciativas públicas y privadas, tanto españolas como de cualquier otro país. Establece una serie de recomendaciones que divide en 4 bloques:
También dispone de un catálogo con todas las aplicaciones móviles de salud a las que se ha otorgado el distintivo “App con distintivo Saludable” que también incluye aplicaciones en proceso de evaluación.

Foster, N. F. (2014). [e-Book] Participatory Design in Academic Libraries, New Reports and Findings. Nancy Fried Foster. Washington, Council on Library and Information Resources, 2014
Este informe se centra en cómo el personal en ocho instituciones académicas mostraron una nueva visión sobre cómo los estudiantes y profesores utilizan sus bibliotecas, y la forma en que el personal está usando estos hallazgos para mejorar las tecnologías de la biblioteca, espacio y servicios. El diseño participativo es un enfoque relativamente reciente para entender el comportamiento del usuario de la biblioteca. Se basa en técnicas utilizadas en la observación antropológica y etnográfica. La editora del informe, antropóloga Nancy Fried Foster, condujo varios talleres de diseño participativo para CLIR de 2007 a 2013. El informe se basa en una serie de presentaciones en el Segundo Seminario CLIR sobre el diseño participativo de las bibliotecas universitarias, que se celebró en la Universidad de Campus Río Rochester de junio de 5-7, 2013. los capítulos se centran en proyectos de la Universidad de Colorado, Boulder; Colegio Colby; Universidad de Connecticut; La Universidad de Columbia; Centro Médico de la Universidad Rush; Universidad de Purdue; Northwestern University; y la Universidad de Rochester. David Lindahl, de la Universidad de Missouri-Kansas City

Kirchner, J., J. Diaz, et al. (eds). [e-Book] The Center of Excellence Model for Information Services Washington, Council on Library and Information Resources, 2015.
En 2013, la Fundación Andrew W. Mellon otorgó a un grupo de bibliotecarios del programa de Becas de Liderazgo de Bibliotecas de Investigación de ARL una subvención de planificación para examinar el modelo de centro de excelencia (CoE) para servicios de información. Este informe describe el enfoque del equipo para examinar la factibilidad de los CdE en el entorno de la biblioteca. La subvención de planificación se concedió para determinar si el modelo de CoE podría servir como un medio para proporcionar los nuevos servicios necesarios para el uso eficaz de la información digital. El equipo llevó a cabo investigaciones preliminares de más de 100 centros, que se redujo a 35 para la investigación en profundidad. Se realizaron entrevistas con personal de 19 centros y 7 organizaciones financiadoras. En su conclusión, el equipo asesora el desarrollo de «redes de expertos» y proporciona una serie de recomendaciones para la construcción de dichas redes.
